На основе линейного уравнения множественной регрессии 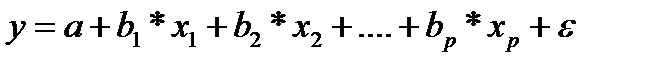
могут быть найдены частные уравнения регрессии:
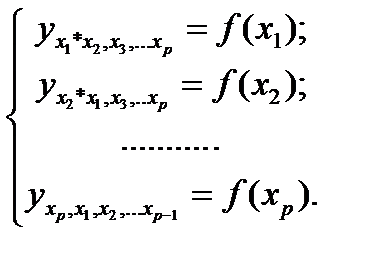 (25.1)
(25.1)
т.е. уравнения регрессии, которые связывают результативный признак с соответствующими факторами хi при закреплении других учитываемых во множественной регрессии факторов на среднем уровне. В случае линейной регрессии частные уравнения имеют следующий вид:
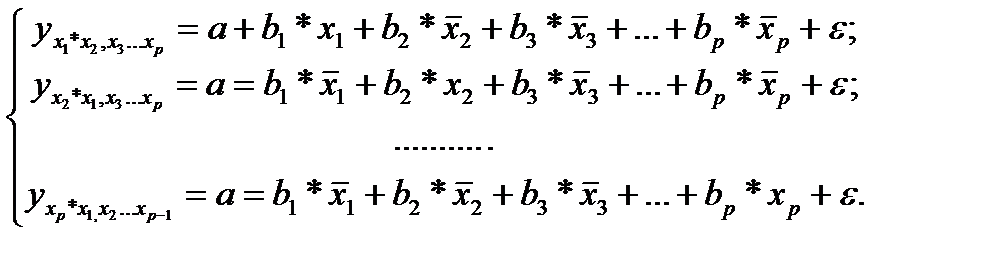 (25.2)
(25.2)
Подставляя в эти уравнения средние значения соответствующих факторов получаем систему уравнений линейной регрессии, т.е. имеем:
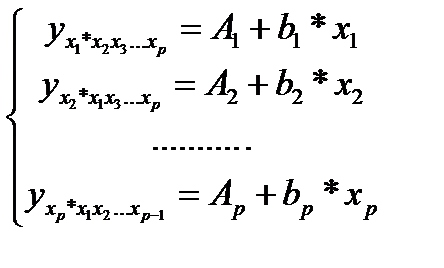 (25.3)
(25.3)
где 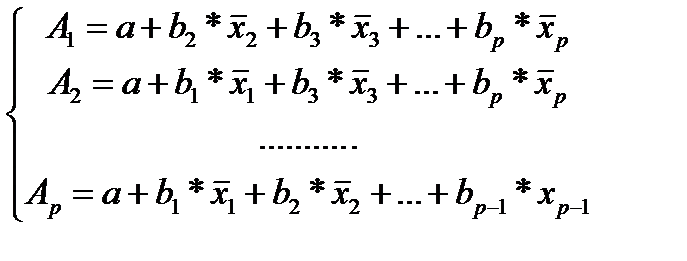 (25.4)
(25.4)
Частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на низменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии (Аi).Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности
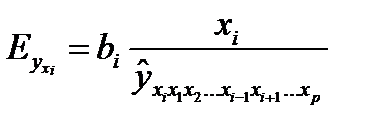 (25.5)
(25.5)
На основании данной информации могут быть найдены средние по совокупности показатели эластичности: 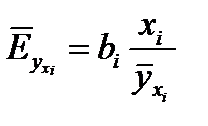 .
.
Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции и его квадрата – коэффициента детерминации. Показатель множественной корреляции характеризует тесноту совместного влияния факторов на результат.
Независимо от вида уравнения индекс множественной корреляции рассчитывается по формуле:
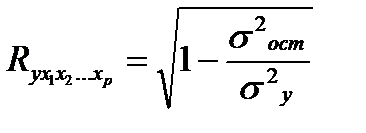 , (25.6)
, (25.6)
где σ 2 y — общая дисперсия результативного признака,
σ 2 ост — остаточная дисперсия .
Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов.
Сравнивая индексы множественной регрессии и парной корреляции, можно сделать вывод о целесообразности включения в уравнение регрессии того или иного фактора. В частности, если дополнительно включенные в уравнение множественной регрессии факторы третьестепенны, то индекс множественной корреляции практически совпадает с индексом парной корреляции.
Если оценивается значимость влияния фактора хi в уравнении регрессии, то определяется частный F- критерий:
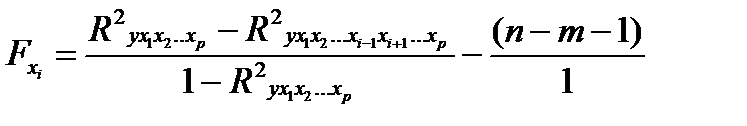 (25.7)
(25.7)
Значимость коэффициентов чистой регрессии производится по t — критерию Стьюдента.
24. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии
Частные коэффициенты (или индексы) корреляции характеризуют тесноту связи между результатом и соответствующим фактором при устранении влияния других факторов, включенных в уравнение регрессии.
Чем больше доля полученной разности в остаточной вариации, тем теснее связь между у и x2 , при неизменности действия фактора x1
Величина, рассчитываемая формулой:
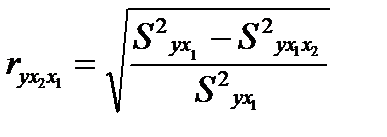 (26.1)
(26.1)
называется индексом частной корреляции для фактора х2:
Аналогично определяется индекс частной корреляции для фактора x1.
Выражая остаточную дисперсию через показатель детерминации
S 2 ост = σ 2 у (1-r 2 ), имеем формулу частной корреляции:
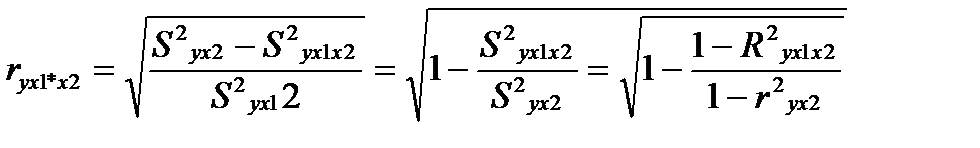 (26.2)
(26.2)
25. Коэффициент множественной корреляции
Практическая значимость уравнения множественной регрессии оценивается показателем множественной корреляции
Показатель множественной корреляции характеризует тесноту связи рассматриваемого набора факторов с исследуемым при знаком, или оценивает тесноту совместного влияния факторов на результат.
Независимо от формы связи показатель множественной корреляции можёт быть найден как индекс множественной корреляции:
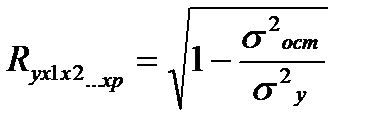 (27.1)
(27.1)
σ 2 ост – остаточная дисперсия для уравнения у=f(x1,x2,… xр)
σ 2 у – общая дисперсия результативного признака
Методика построения индекса множественной корреляции аналогична построению индекса корреляции для парной зависимости. Его пределы от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем I бором исследуемых факторов. Величина индекса множественно корреляции должна быть больше или равна максимальному парному индексу корреляции: —
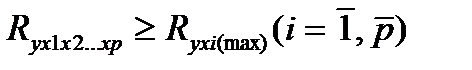 (27.2)
(27.2)
Обоснованность включения факторов в регрессионный анализ приведет к существенному отличию показателя от индекса корреляции парной зависимости. При включении модель маловажных факторов происходит уравнение индекса множественной корреляции с индексом парной корреляции. Сравнивая индексы множественной и парной корреляции делают заключение о возможности включения в уравнение регрессии того или иного фактора.
Расчет индекса множественной Корреляции предполагает определение уравнения множественной регрессии и на его основе остаточной дисперсии:
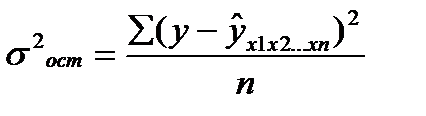 (27.3)
(27.3)
Возможна и такая интерпретация формулы индекса множественной корреляции
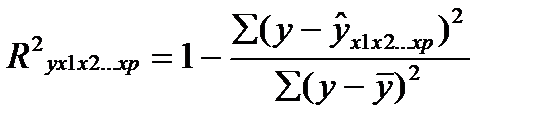 (27.4)
(27.4)
26. Коэффициент множественной детерминации
Коэффициент детерминации –это квадрат показателем множественной корреляции.
Множественный коэффициент детерминации можно рассматривать как меру качества уравнения регрессии, характеристику прогностической силы анализируемой регрессионной модели: чем ближе R 2 к единице, тем лучше регрессия описывает зависимость между объясняющими и зависимой переменными. Недостаток R 2 состоит в том, что его значение не убывает с ростом числа объясняющих переменных. В эконометрическом анализе чаще применяют скорректированный коэффициент детерминации R^ 2 определяемый по формуле
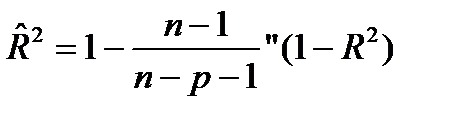 (28.1)
(28.1)
который может уменьшаться при введении в регрессионную модель переменных, не оказывающих существенного влияния на зависимую переменную.
Если известен коэффициент детерминации R 2 то критерий значимости уравнения регрессии может быть записан в виде:
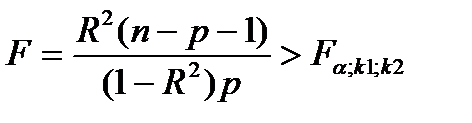 (28.2)
(28.2)
где ‚ к1= р, к2 = n — р — 1, ибо в уравнении множественной регрессии вместе со свободным членом оценивается m = р + 1 параметров.
27. Проверка гипотезы о значимости частного и множественного коэффициентов корреляции
Проверка гипотез используется, когда необходим обоснованный вывод о значимости частного и множественного коэффициентов корреляции. При этом гипотезой называется любое предположение о виде или параметрах неизвестного закона распределения.
Множественный коэффициент корреляции заключен в пре делах 0 до1. Он не меньше, чем абсолютная величина любого парного или частного коэффициента корреляции с таким же первичным индексом.
С помощью множественного коэффициента корреляции (по мере приближения к 1 делается вывод о тесноте взаимосвязи, но не о ее направлении.
Частный коэффициент корреляции. Если переменные коррелируют друг с другом, то на величине парного коэффициента корреляции частично сказывается влияние других переменных. В связи с этим часто возникает необходимость исследовать частную корреляцию между переменными при устранении влияния одной/нескольких переменных
28. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Основной предпосылкой регрессионного анализа является то, что только результативный признак (У) подчиняется нормальному закону распределения, а факторные признаки х 1 . Х 2 . х n могут иметь произвольный закон распределения. В анализе динамических рядов в качестве факторного признака выступает время t При этом в регрессионном анализе заранее подразумевается наличие причинно-следственных связей между результативным (У) и факторными х 1 . Х 2 . х n признаками. В тех случаях, когда из природы процессов в модели или из данных наблюдений над ней следует вывод о нормальном законе распределения двух СВ — Y и X , из которых одна является независимой, т. е. Y является функцией X , то возникает соблазн определить такую зависимость “формульно”, аналитически.Уравнение регрессии, или статистическая модель связи социально-экономических явлений, выражаемая функцией Y=f( х 1 . Х 2 . х n ) является достаточно адекватным реальному моделируемому явлению или процессу в случае соблюдения следующих требований их построения. 1) Совокупность исследуемых исходных данных должна быть однородной и математически описываться непрерывными функциями. 2) Возможность описания моделируемого явления одним или несколькими уравнениями причинно-следственных связей. 3) Все факторные признаки должны иметь количественное (цифровое) выражение. 4) Наличие достаточно большого объема исследуемой выборочной совокупности. 5) Причинно-следственные связи между явлениями и процессами следует описывать линейной или приводимой к линейной формой зависимости. 6) Отсутствие количественных ограничений на параметры модели связи. 7) Постоянство территориальной и временной структуры изучаемойсовокупности. Соблюдение данных требований позволяет исследователю построить статистическую модель связи, наилучшим образом аппроксимирующую моделируемые социально-экономические явления и процессы. В случае успеха нам будет намного проще вести моделирование. Конечно, наиболее заманчивой является перспектива линейной зависимости типа Y = a + b · X . Подобная задача носит название задачи регрессионного анализа и предполагает следующий способ решения. Выдвигается следующая гипотеза H 0 : случайная величина Y при фиксированном значении величины X распределена нормально с математическим ожиданием М y = a + b · X и дисперсией D y , не зависящей от X . При наличии результатов наблюдений над парами X i и Y i предварительно вычисляются средние значения M y и M x , а затем производится оценка коэффициента b в виде b = = R xy что следует из определениякоэффициента корреляции. После этого вычисляется оценка для a в виде и производится проверка значимости полученных результатов. Таким образом, регрессионный анализ является мощным, хотя и далеко не всегда допустимым расширением корреляционного анализа, решая всё ту же задачу оценки связей в сложной системе.
29. Определение мультиколлинеарности. Последствия мулыиколлицеарности. Методы обнаружения мультиколлинеарности
Мультиколлинеарность -это процесс, при котором между факторами происходит совокупное воздействие друг на друга
Наличие мультиколлинеарности факторов может означать, что некоторые факторы действуют синхронно. В итоге вариация в исходных данных зависима и невозможно оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов.
Если рассматривается регрессия у = а + b * х + с * z + d * v + ε то для расчета параметров с применением МНК предполагается равенство:
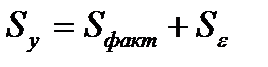 (31.1)
(31.1)
где 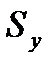 — общая сумма квадратов отклонений Σ(уi-у¯) 2
— общая сумма квадратов отклонений Σ(уi-у¯) 2
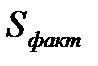 — факторная сумма квадратов отклонений: Σ(у^i-у¯) 2
— факторная сумма квадратов отклонений: Σ(у^i-у¯) 2
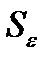 — остаточная сумма квадратов отклонений Σ(у^i-у) 2
— остаточная сумма квадратов отклонений Σ(у^i-у) 2
Если же факторы интеркоррелированы, то данное равенство нарушается.
Включение в модель мультиколлинеарных факторов нежелательно по причинам:
• затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в чистом виде, т.к. факторы коррелированны. При этом параметры линейной регрессии утрачивают экономический смысл;
• оценки параметров ненадежны, появляются стандартные ошибки, которые меняются с изменением объема наблюдений (по величине и знаку), Модель нельзя анализировать и строить на ее основе прогнозы.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных Коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между ними была бы единичной, т.к. все элементы не находящиеся на диагоналях равны 0. Для уравнения включающее три объясняющих переменных,
у = а + b1 * х1 + b2 * х2 + b3 * х3 +ε, при этом матрица коэффициентов корреляции между факторами имела определитель равный единице.
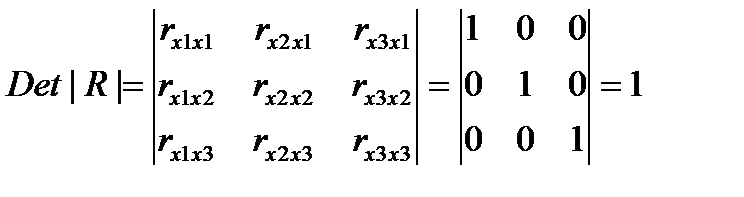 (31.2)
(31.2)
Если же между факторами существует полная линейная зависимость и все Коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю.
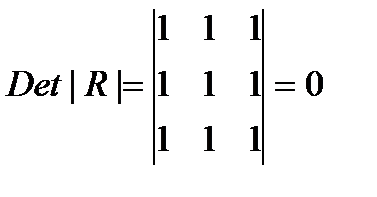 (31.3)
(31.3)
Чем ближе к — нулю определитель матрицы межфакторной корреляции тем сильнее мультиколлинеарность факторов и ненадежнее результаты множествснной регрессии. Наоборот чем ближе к единице определитель матрицы межфакторной корреляции тем меньше мультиколлинеарность факторов.
30. Методы устранения мультиколлинеарности
Устраняя мультиколлинеарность факторов чаще всего используют приведенную форму. Для этого в уравнение регрессии подставляют рассматриваемый фактор, выраженный из другого уравнения.
В двухфакторной регрессии вида
 (32.1)
(32.1)
сделав предобразования получим:
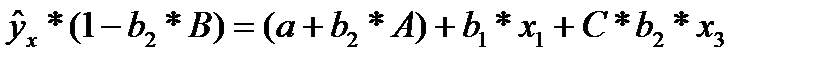 (32.2)
(32.2)
Если исключить один из факторов, то мы придем к уравнению парной регрессии. Вместе с тем, можно оставить факторы в модели, но исследовать данное двух факторное уравнение регрессии совместно с другим уравнением, в котором фактор рассматривается как зависимая переменная. При (1-b2*В) ≠ 0, делим первую и вторую части уравнения на (1-b2*В), получаем:
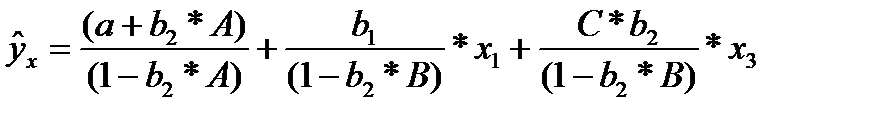 (32.3)
(32.3)
Получили приведенную форму уравнения для определения результативного признака у. Это уравнение может быть представлено в виде (32.4)
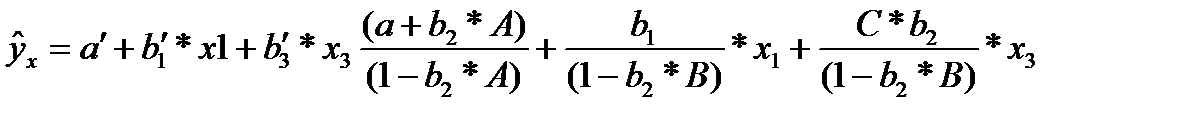
К нему для оценки параметров может быть применен метод наименьших квадратов.
Отбор факторов, включаемых в регрессию -основной этап практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут различны. Они приводят построение уравнение множественной регрессии соответственно к разным методикам.
Наиболее распространены методы построения уравнения множественной регрессии:
• шаговый регрессионный анализ.
Каждый метод помогает устранить мультиколлинеарность позволяя производить отсев факторов из полного его набора (метод исключения), дополнительное введение фактора (метод включения), исключение ранее введенного фактора (шаговый регрессионный анализ).
На первый Взгляд может показаться, что матрица парных коэффициентов корреляции играет главную роль в отборе факторов. Вместе с тем вследствие взаимодействия факторов парные коэффициенты корреляции не могут полностью решать вопрос целесообразности включения в модель того определенного фактора. Эту роль выполняют показатели частной корреляции, оценивающие в чистом виде тесноту связи фактора с результатом. Матрица частных коэффициентов корреляции наиболее широко используется в процедуре отсева факторов. Отсев факторов можно проводить и по t-критерию Стьюдента для коэффициентов регрессии: из уравнения исключаются факторы с величиной t-критерия меньше табличного.
В заключении следует уточнить: число включаемых факторов обычно в 6—7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной вариации очень мало. Это приводит к тому, что пара метры уравнения регрессии оказываются статистически незначимыми, а Р-критерий меньше табличного значения.
31. Модели регрессии, нелинейные по факторным переменным
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы 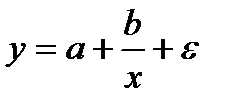 , параболы второй степени
, параболы второй степени 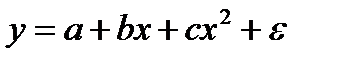 и д.р.
и д.р.
Различают два класса нелинейных регрессий:
• регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
• регрессии, нелинейные по оцениваемым параметрам.
Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
• полиномы разных степеней
К нелинейным регрессиям по оцениваемым параметрам относятся функции:
- Уравнение множественной регрессии
- Построение парной регрессионной модели
- Множественная линейная регрессия. Улучшение модели регрессии
- Понятие множественной линейной регрессии
- Уравнение множественной линейной регрессии и метод наименьших квадратов
- МНК-оценка коэффиентов уравнения множественной регрессии в скалярном виде
- МНК-оценка коэффиентов уравнения множественной регрессии в матричном виде
- Построение наилучшей (наиболее качественной) модели множественной линейной регрессии
- Оценка качества модели множественной линейной регрессии в целом
- Анализ значимости коэффициентов модели множественной линейной регрессии
- Исключение резко выделяющихся наблюдений
- Исключение незначимых переменных из модели
- Нелинейные модели для сравнения
- Применение пошаговых алгоритмов включения и исключения переменных
- Выбор самой качественной модели множественной линейной регрессии
Уравнение множественной регрессии
Назначение сервиса . С помощью онлайн-калькулятора можно найти следующие показатели:
- уравнение множественной регрессии, матрица парных коэффициентов корреляции, средние коэффициенты эластичности для линейной регрессии;
- множественный коэффициент детерминации, доверительные интервалы для индивидуального и среднего значения результативного признака;
Кроме этого проводится проверка на автокорреляцию остатков и гетероскедастичность.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Отбор факторов обычно осуществляется в два этапа:
- теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
- количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции). Научно обоснованное решение задач подобного вида также осуществляется с помощью дисперсионного анализа — однофакторного, если проверяется существенность влияния того или иного фактора на рассматриваемый признак, или многофакторного в случае изучения влияния на него комбинации факторов.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
- Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
- Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
- Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность — тесная линейная связь между факторами.
Пример . Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели.
Решение.
К исходной матрице X добавим единичный столбец, получив новую матрицу X
| 1 | 5 | 14.5 |
| 1 | 12 | 18 |
| 1 | 6 | 12 |
| 1 | 7 | 13 |
| 1 | 8 | 14 |
Матрица Y
| 9 |
| 13 |
| 16 |
| 14 |
| 21 |
Транспонируем матрицу X, получаем X T :
| 1 | 1 | 1 | 1 | 1 |
| 5 | 12 | 6 | 7 | 8 |
| 14.5 | 18 | 12 | 13 | 14 |
| Умножаем матрицы, X T X = |
|
В матрице, (X T X) число 5, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
| Умножаем матрицы, X T Y = |
|
Находим обратную матрицу (X T X) -1
| 13.99 | 0.64 | -1.3 |
| 0.64 | 0.1 | -0.0988 |
| -1.3 | -0.0988 | 0.14 |
Вектор оценок коэффициентов регрессии равен
| (X T X) -1 X T Y = y(x) = |
| * |
| = |
|
Получили оценку уравнения регрессии: Y = 34.66 + 1.97X1-2.45X2
Оценка значимости уравнения множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю коэффициент детерминации рассчитанного по данным генеральной совокупности. Для ее проверки используют F-критерий Фишера.
R 2 = 1 — s 2 e/∑(yi — yср) 2 = 1 — 33.18/77.2 = 0.57
F = R 2 /(1 — R 2 )*(n — m -1)/m = 0.57/(1 — 0.57)*(5-2-1)/2 = 1.33
Табличное значение при степенях свободы k1 = 2 и k2 = n-m-1 = 5 — 2 -1 = 2, Fkp(2;2) = 19
Поскольку фактическое значение F = 1.33 Пример №2 . Приведены данные за 15 лет по темпам прироста заработной платы Y (%), производительности труда X1 (%), а также по уровню инфляции X2 (%).
| Год | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X1 | 3,5 | 2,8 | 6,3 | 4,5 | 3,1 | 1,5 | 7,6 | 6,7 | 4,2 | 2,7 | 4,5 | 3,5 | 5,0 | 2,3 | 2,8 |
| X2 | 4,5 | 3,0 | 3,1 | 3,8 | 3,8 | 1,1 | 2,3 | 3,6 | 7,5 | 8,0 | 3,9 | 4,7 | 6,1 | 6,9 | 3,5 |
| Y | 9,0 | 6,0 | 8,9 | 9,0 | 7,1 | 3,2 | 6,5 | 9,1 | 14,6 | 11,9 | 9,2 | 8,8 | 12,0 | 12,5 | 5,7 |
Решение. Подготовим данные для вставки из MS Excel (как транспонировать таблицу для сервиса см. Задание №2) .

Включаем в отчет: Проверка общего качества уравнения множественной регрессии (F-статистика. Критерий Фишера, Проверка на наличие автокорреляции),
После нажатия на кнопку Дале получаем готовое решение.
Уравнение регрессии (оценка уравнения регрессии):
Y = 0.2706 + 0.5257X1 + 1.4798X2
Скачать.
Качество построенного уравнения регрессии проверяется с помощью критерия Фишера (п. 6 отчета).
Пример №3 .
В таблице представлены данные о ВВП, объемах потребления и инвестициях некоторых стран.
| ВВП | 16331,97 | 16763,35 | 17492,22 | 18473,83 | 19187,64 | 20066,25 | 21281,78 | 22326,86 | 23125,90 |
| Потребление в текущих ценах | 771,92 | 814,28 | 735,60 | 788,54 | 853,62 | 900,39 | 999,55 | 1076,37 | 1117,51 |
| Инвестиции в текущих ценах | 176,64 | 173,15 | 151,96 | 171,62 | 192,26 | 198,71 | 227,17 | 259,07 | 259,85 |
Решение:
Для проверки полученных расчетов используем инструменты Microsoft Excel «Анализ данных» (см. пример).
Пример №4 . На основе данных, приведенных в Приложении и соответствующих Вашему варианту (таблица 2), требуется:
- Построить уравнение множественной регрессии. При этом признак-результат и один из факторов остаются теми же, что и в первом задании. Выберите дополнительно еще один фактор из приложения 1 (границы наблюдения должны совпадать с границами наблюдения признака-результата, соответствующего Вашему варианту). При выборе фактора нужно руководствоваться его экономическим содержанием или другими подходами. Пояснить смысл параметров уравнения.
- Рассчитать частные коэффициенты эластичности. Сделать вывод.
- Определить стандартизованные коэффициенты регрессии (b-коэффициенты). Сделать вывод.
- Определить парные и частные коэффициенты корреляции, а также множественный коэффициент корреляции; сделать выводы.
- Оценить значимость параметров уравнения регрессии с помощью t-критерия Стьюдента, а также значимость уравнения регрессии в целом с помощью общего F-критерия Фишера. Предложить окончательную модель (уравнение регрессии). Сделать выводы.
Решение. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 3.9 | 10 |
| 1 | 3.9 | 14 |
| 1 | 3.7 | 15 |
| 1 | 4 | 16 |
| 1 | 3.8 | 17 |
| 1 | 4.8 | 19 |
| 1 | 5.4 | 19 |
| 1 | 4.4 | 20 |
| 1 | 5.3 | 20 |
| 1 | 6.8 | 20 |
| 1 | 6 | 21 |
| 1 | 6.4 | 22 |
| 1 | 6.8 | 22 |
| 1 | 7.2 | 25 |
| 1 | 8 | 28 |
| 1 | 8.2 | 29 |
| 1 | 8.1 | 30 |
| 1 | 8.5 | 31 |
| 1 | 9.6 | 32 |
| 1 | 9 | 36 |
Матрица Y
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 8 |
| 8 |
| 8 |
| 10 |
| 9 |
| 11 |
| 9 |
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 14 |
| 14 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3.9 | 3.9 | 3.7 | 4 | 3.8 | 4.8 | 5.4 | 4.4 | 5.3 | 6.8 | 6 | 6.4 | 6.8 | 7.2 | 8 | 8.2 | 8.1 | 8.5 | 9.6 | 9 |
| 10 | 14 | 15 | 16 | 17 | 19 | 19 | 20 | 20 | 20 | 21 | 22 | 22 | 25 | 28 | 29 | 30 | 31 | 32 | 36 |
Умножаем матрицы, (X T X)
Умножаем матрицы, (X T Y)
Находим определитель det(X T X) T = 139940.08
Находим обратную матрицу (X T X) -1
Уравнение регрессии
Y = 1.8353 + 0.9459X 1 + 0.0856X 2
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s
| 0.62 |
| 0.28 |
| 0.38 |
| 0.01 |
| 0.11 |
| -1 |
| -0.57 |
| 0.29 |
| -0.56 |
| 0.02 |
| -0.31 |
| 1.23 |
| -1.15 |
| 0.21 |
| 0.2 |
| -0.07 |
| -0.07 |
| -0.53 |
| 0.34 |
| 0.57 |
se 2 = (Y — X*s) T (Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(X T X) -1
| k(x) = 0.36 |
| = |
|
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X сильная
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции — последовательно берутся пары yx1,yx2. , x1x2, x1x3.. и так далее и для каждой пары находится коэффициент корреляции
Коэффициент детерминации
R 2 = 0.97 2 = 0.95, т.е. в 95% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл: Tтабл (n-m-1;a) = (17;0.05) = 1.74
Поскольку Tнабл Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
Построение парной регрессионной модели
Рекомендации к решению контрольной работы.
Статистические данные по экономике можно получить на странице Россия в цифрах.
После определения зависимой и объясняющих переменных можно воспользоваться сервисом Множественная регрессия. Регрессионную модель с 2-мя объясняющими переменными можно построить используя матричный метод нахождения параметров уравнения регрессии или метод Крамера для нахождения параметров уравнения регрессии.
Пример №3 . Исследуется зависимость размера дивидендов y акций группы компаний от доходности акций x1, дохода компании x2 и объема инвестиций в расширение и модернизацию производства x3. Исходные данные представлены выборкой объема n=50.
Тема I. Парная линейная регрессия
Постройте парные линейные регрессии — зависимости признака y от факторов x1, x2, x3 взятых по отдельности. Для каждой объясняющей переменной:
- Постройте диаграмму рассеяния (поле корреляции). При построении выберите тип диаграммы «Точечная» (без отрезков, соединяющих точки).
- Вычислите коэффициенты уравнения выборочной парной линейной регрессии (для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические») или надстройкой Пакет Анализа), коэффициент детерминации, коэффициент корреляции (функция КОРЕЛЛ), среднюю ошибку аппроксимации
 .
. - Запишите полученное уравнение выборочной регрессии. Дайте интерпретацию найденным в предыдущем пункте значениям.
- Постройте на поле корреляции прямую линию выборочной регрессии по точкам .
- Постройте диаграмму остатков.
- Проверьте статистическую значимость коэффициентов регрессии по критерию Стьюдента (табличное значение определите с помощью функции СТЬЮДРАСПОБР) и всего уравнения в целом по критерию Фишера (табличное значение Fтабл определите с помощью функции FРАСПОБР).
- Постройте доверительные интервалы для коэффициентов регрессии. Дайте им интерпретацию.
- Постройте прогноз для значения фактора, на 50% превышающего его среднее значение.
- Постройте доверительный интервал прогноза. Дайте ему экономическую интерпретацию.
- Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемого фактора на показатель.
Тема II. Множественная линейная регрессия
1. Постройте выборочную множественную линейную регрессию показателя на все указанные факторы. Запишите полученное уравнение, дайте ему экономическую интерпретацию.
2. Определите коэффициент детерминации, дайте ему интерпретацию. Вычислите среднюю абсолютную ошибку аппроксимации и дайте ей интерпретацию.
3. Проверьте статистическую значимость каждого из коэффициентов и всего уравнения в целом.
4. Постройте диаграмму остатков.
5. Постройте доверительные интервалы коэффициентов. Для статистически значимых коэффициентов дайте интерпретации доверительных интервалов.
6. Постройте точечный прогноз значения показателя y при значениях факторов, на 50% превышающих их средние значения.
7. Постройте доверительный интервал прогноза, дайте ему экономическую интерпретацию.
8. Постройте матрицу коэффициентов выборочной корреляции между показателем и факторами. Сделайте вывод о наличии проблемы мультиколлинеарности.
9. Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемых факторов на показатель.
Множественная линейная регрессия. Улучшение модели регрессии
Понятие множественной линейной регрессии
Множественная линейная регрессия — выраженная в виде прямой зависимость среднего значения величины Y от двух или более других величин X 1 , X 2 , . X m . Величину Y принято называть зависимой или результирующей переменной, а величины X 1 , X 2 , . X m — независимыми или объясняющими переменными.
В случае множественной линейной регрессии зависимость результирующей переменной одновременно от нескольких объясняющих переменных описывает уравнение или модель
 ,
,
где  — коэффициенты функции линейной регрессии генеральной совокупности,
— коэффициенты функции линейной регрессии генеральной совокупности,
 — случайная ошибка.
— случайная ошибка.
Функция множественной линейной регрессии для выборки имеет следующий вид:
 ,
,
где  — коэффициенты модели регрессии выборки,
— коэффициенты модели регрессии выборки,
 — ошибка.
— ошибка.
Уравнение множественной линейной регрессии и метод наименьших квадратов
Коэффициенты модели множественной линейной регресии, так же, как и для парной линейной регрессии, находят при помощи метода наименьших квадратов.
Разумеется, мы будем изучать построение модели множественной регрессии и её оценивание с использованием программных средств. Но на экзамене часто требуется привести формулы МНК-оценки (то есть оценки по методу наименьших квадратов) коэффициентов уравнения множественной линейной регрессии в скалярном и в матричном видах.
МНК-оценка коэффиентов уравнения множественной регрессии в скалярном виде
Метод наименьших квадратов позволяет найти такие значения коэффициентов, что сумма квадратов отклонений будет минимальной. Для нахождения коэффициентов решается система нормальных уравнений

Решение системы можно получить, например, методом Крамера:
 .
.
Определитель системы записывается так:

МНК-оценка коэффиентов уравнения множественной регрессии в матричном виде
Данные наблюдений и коэффициенты уравнения множественной регрессии можно представить в виде следующих матриц:

Формула коэффициентов множественной линейной регрессии в матричном виде следующая:
 ,
,
где  — матрица, транспонированная к матрице X,
— матрица, транспонированная к матрице X,
 — матрица, обратная к матрице
— матрица, обратная к матрице  .
.
Решая это уравнение, мы получим матрицу-столбец b, элементы которой и есть коэффициенты уравнения множественной линейной регрессии, для нахождения которых и был изобретён метод наименьших квадратов.
Построение наилучшей (наиболее качественной) модели множественной линейной регрессии
Пусть при обработке данных некоторой выборки в пакете программных средств STATISTICA получена первоначальная модель множественной линейной регрессии. Предстоит проанализировать полученную модель и в случае необходимости улучшить её.
Качество модели множественной линейной регрессии оценивается по тем же показателям качества, что и в случае модели парной линейной регрессии: коэффициент детерминации  , F-статистика (статистика Фишера), сумма квадратов остатков RSS, стандартная ошибка регрессии (SEE). В случае множественной регрессии следует использовать также скорректированный коэффициент детерминации (adjusted ), который применяется при исключении или добавлении в модель наблюдений или переменных.
, F-статистика (статистика Фишера), сумма квадратов остатков RSS, стандартная ошибка регрессии (SEE). В случае множественной регрессии следует использовать также скорректированный коэффициент детерминации (adjusted ), который применяется при исключении или добавлении в модель наблюдений или переменных.
Важный показатель качества модели линейной регрессии — проверка на выполнение требований Гаусса-Маркова к остаткам. В качественной модели линейной регрессии выполняются все условия Гаусса-Маркова:
- условие 1: математическое ожидание остатков равно нулю для всех наблюдений ( ε(e i ) = 0 );
- условие 2: теоретическая дисперсия остатков постоянна (равна константе) для всех наблюдений ( σ²(e i ) = σ²(e i ), i = 1, . n );
- условие 3: отсутствие систематической связи между остатками в любых двух наблюдениях;
- условие 4: отсутствие зависимости между остатками и объясняющими (независимыми) переменными.
В случае выполнения требований Гаусса-Маркова оценка коэффициентов модели, полученная методом наименьших квадратов является
Затем необходимо провести анализ значимости отдельных переменных модели множественной линейной регрессии с помощью критерия Стьюдента.
В случае наличия резко выделяющихся наблюдений (выбросов) нужно последовательно по одному исключить их из модели и проанализировать наличие незначимых переменных в модели и, в случае необходимости исключить их из модели по одному.
В исследованиях поведения человека, как и во многих других, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Кроме того, требуется на основе тех же данных построить две нелинейные модели регрессии — с квадратами двух наиболее значимых переменных и с логарифмами тех же наиболее значимых переменных. Они также будут сравниваться с линейными моделями, полученных на разных шагах.
Также требуется построить модели с применением пошаговых процедур включения (FORWARD STEPWISE) и исключения (BACKWARD STEPWISE).
Все полученные модели множественной регрессии нужно сравнить и выбрать из них наилучшую (наиболее качественную). Теперь разберём перечисленные выше шаги последовательно и на примере.
Оценка качества модели множественной линейной регрессии в целом
Пример. Задание 1. Получено следующее уравнение множественной линейной регрессии:
и следующие показатели качества описываемой этим уравнением модели:
| adj. | RSS | SEE | F | p-level |
| 0,426 | 0,279 | 2,835 | 1,684 | 2,892 | 0,008 |
Сделать вывод о качестве модели в целом.
Ответ. По всем показателям модель некачественная. Значение не стремится к единице, а значение скорректированного ещё более низкое. Значение RSS, напротив, высокое, а p-level — низкое.
Для анализа на выполнение условий Гаусса-Маркова воспользуемся диаграммой рассеивания наблюдений (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши):

Результаты проверки графика показывают: условие равенства нулю математического ожидания остатков выполняется, а условие на постоянство дисперсии — не выполняется. Достаточно невыполнения хотя бы одного условия Гаусса-Маркова, чтобы заключить, что оценка коэффициентов модели линейной регрессии не является несмещённой, эффективной и состоятельной.
Анализ значимости коэффициентов модели множественной линейной регрессии
С помощью критерия Стьюдента проверяется гипотеза о том, что соответствующий коэффициент незначимо отличается от нуля, и соответственно, переменная при этом коэффициенте имеет незначимое влияние на зависимую переменную. В свою очередь, в колонке p-level выводится вероятность того, что основная гипотеза будет принята. Если значение p-level больше уровня значимости α, то основная гипотеза принимается, иначе – отвергается. В нашем примере установлен уровень значимости α=0,05.
Пример. Задание 2. Получены следующие значения критерия Стьюдента (t) и p-level, соответствующие переменным уравнения множественной линейной регрессии:
| Перем. | Знач. коэф. | t | p-level |
| X1 | 0,129 | 2,386 | 0,022 |
| X2 | -0,286 | -2,439 | 0,019 |
| X3 | -0,037 | -0,238 | 0,813 |
| X4 | 0,15 | 1,928 | 0,061 |
| X5 | 0,328 | 0,548 | 0,587 |
| X6 | -0,391 | -0,503 | 0,618 |
| X7 | -0,673 | -0,898 | 0,375 |
| X8 | -0,006 | -0,07 | 0,944 |
| X9 | -1,937 | -2,794 | 0,008 |
| X10 | -1,233 | -1,863 | 0,07 |
Сделать вывод о значимости коэффициентов модели.
Ответ. В построенной модели присутствуют коэффициенты, которые незначимо отличаются от нуля. В целом же у переменной X8 коэффициент самый близкий к нулю, а у переменной X9 — самое высокое значение коэффициента. Коэффициенты модели линейной регрессии можно ранжировать по мере убывания незначимости с возрастанием значения t-критерия Стьюдента.
Исключение резко выделяющихся наблюдений
Пример. Задание 3. Выявлены несколько резко выделяющихся наблюдений (выбросов, то есть наблюдений с нетипичными значениями): 10, 3, 4 (соответствуют строкам исходной таблицы данных). Эти наблюдения следует последовательно исключить из модели и по мере исключения заполнить таблицу с показателями качества модели. Исключили наблюдение 10 — заполнили значение показателей, далее исключили наблюдение 3 — заполнили и так далее. По мере исключения STATISTICA будет выдавать переменные, которые остаются значимыми в модели множественной линейной регрессии — они будут выделены красном цветом. Те, что не будут выделены красным цветом — незначимые переменные и их также нужно внести в соответствующую ячейку таблицы. По завершении исключения выбросов записать уравнение конечной множественной линейной регрессии.
| № | adj. | SEE | F | p- level | незнач. пер. |
| 10 | 0,411 | 2,55 | 2,655 | 0,015 | X3, X4, X5, X6, X7, X8, X10 |
| 3 | 0,21 | 2,58 | 2,249 | 0,036 | X3, X4, X5, X6, X7, X8, X10 |
| 4 | 0,16 | 2,61 | 1,878 | 0,082 | X3, X4, X5, X6, X7, X8, X10 |
Уравнение конечной множественной линейной регрессии:
Случается однако, когда после исключения некоторого наблюдения исключение последующих наблюдений приводит к ухудшению показателей качества модели. Причина в том, что с исключением слишком большого числа наблюдений выборка теряет информативность. Поэтому в таких случаях следует вовремя остановиться.
Исключение незначимых переменных из модели
Пример. Задание 4. По мере исключения из модели множественной линейной регрессии переменных с незначимыми коэффициентами (получены при выполнении предыдущего задания, занесены в последнюю колонку таблицы) заполнить таблицу с показателями качества модели. Последняя колонка, обозначенная звёздочкой — список переменных, имеющих значимое влияние на зависимую переменную. Эти переменные STATISTICA будет выдавать выделенными красным цветом. По завершении исключения незначимых переменных записать уравнение конечной множественной линейной регрессии.
| Искл. пер. | adj. | SEE | F | p- level | * |
| X3 | 0,18 | 1,71 | 2,119 | 0,053 | X4, X5, X6, X7, X8, X10 |
| X4 | 0,145 | 1,745 | 1,974 | 0,077 | X5, X6, X7, X8, X10 |
| X5 | 0,163 | 2,368 | 2,282 | 0,048 | X6, X7, X8, X10 |
| X6 | 0,171 | 2,355 | 2,586 | 0,033 | X7, X8, X10 |
| X7 | 0,167 | 2,223 | 2,842 | 0,027 | X8, X10 |
| X8 | 0,184 | 1,705 | 3,599 | 0,013 | X10 |
Когда осталась одна переменная, имеющая значимое влияние на зависимую переменную, больше не исключаем переменные, иначе получится, что в модели все переменные незначимы.
Уравнение конечной множественной линейной регрессии после исключения незначимых переменных:
Переменные X1 и X2 в задании 3 не вошли в список незначимых переменных, поэтому они вошли в уравнение конечной множественной линейной регрессии «автоматически».
Нелинейные модели для сравнения
Пример. Задание 5. Построить две нелинейные модели регрессии — с квадратами двух наиболее значимых переменных и с логарифмами тех же наиболее значимых переменных.
Так как в наблюдениях переменных X9 и X10 имеется 0, а натуральный логарифм от 0 вычислить невозможно, то берутся следующие по значимости переменные: X1 и X2.
Полученное уравнение нелинейной регрессии с квадратами двух наиболее значимых переменных:
Показатели качества первой модели нелинейной регрессии:
| adj. | RSS | SEE | F | p-level |
| 0,17 | 0,134 | 159,9 | 1,845 | 4,8 | 0,0127 |
Вывод: модель некачественная, так как RSS и SEE принимают высокие значения, p-level стремится к нулю, коэффициент детерминации незначимо отличается от нуля.
Полученное уравнение нелинейной регрессии с логарифмами двух наиболее значимых переменных:
Показатели качества второй модели нелинейной регрессии:
| adj. | RSS | SEE | F | p-level |
| 0,182 | 0,148 | 157,431 | 1,83 | 5,245 | 0 |
Вывод: модель некачественная, так как RSS и SEE принимают высокие значения, p-level стремится к нулю, коэффициент детерминации незначимо отличается от нуля.
Применение пошаговых алгоритмов включения и исключения переменных
Пример. Задание 6. Настроить пакет STATISTICA для применения пошаговых процедур включения (FORWARD STEPWISE) и исключения (BACKWARD STEPWISE). Для этого в диалоговом окне MULTIPLE REGRESSION указать Advanced Options (stepwise or ridge regression). В поле Method выбрать либо Forward Stepwise (алгоритм пошагового включения), либо Backward Stepwise (алгоритм пошагового исключения). Необходимо настроить следующие параметры:
- в окне Tolerance необходимо установить критическое значение для уровня толерантности (оставить предложенное по умолчанию);
- в окне F-remove необходимо установить критическое значение для статистики исключения (оставить предложенное по умолчанию);
- в окне Display Results необходимо установить режим At each step (результаты выводятся на каждом шаге процедуры).
Построить, как описано выше, модели множественной линейной регрессии автоматически.
В результате применения пошагового алгоритма включения получено следующее уравнение множественной линейной регрессии:
Показатели качества модели нелинейной регрессии, полученной с применением пошаговой процедуры включения:
| adj. | RSS | SEE | F | p-level |
| 0,41 | 0,343 | 113,67 | 1,61 | 6,11 | 0,002 |
В результате применения пошагового алгоритма исключения получено следующее уравнение множественной линейной регрессии:
Показатели качества модели нелинейной регрессии, полученной с применением пошаговой процедуры исключения:
| adj. | RSS | SEE | F | p-level |
| 0,22 | 0,186 | 150,28 | 1,79 | 6,61 | 0 |
Выбор самой качественной модели множественной линейной регрессии
Пример. Задание 7. Сравнить модели, полученные на предыдущих шагах и определить самую качественную.
| Модель | Ручная | Кв. перем. | Лог. перем. | forward stepwise | backward stepwise |
| 0,255 | 0,17 | 0,182 | 0,41 | 0,22 |
| adj. | 0,184 | 0,134 | 0,148 | 0,343 | 0,186 |
| RSS | 122,01 | 159,9 | 157,43 | 113,67 | 150,28 |
| SEE | 1,705 | 1,845 | 1,83 | 1,61 | 1,79 |
| F | 3,599 | 4,8 | 5,245 | 6,11 | 6,61 |
| p-level | 0,013 | 0,0127 | 0 | 0,002 | 0 |
Самая качественная модель множественной линейной регрессии — модель, построенная методом FORWARD STEPWISE (пошаговое включение переменных), так как коэффициент детерминации у неё самый высокий, а RSS и SEE наименьшие в сравнении значений оценок качества других регрессионных моделей.