Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
- Понятие линейной регрессии. Парная линейная регрессия
- Уравнение парной линейной регрессии и метод наименьших квадратов
- Определение коэффициентов уравнения парной линейной регрессии
- Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
- Анализ качества модели линейной регрессии
- Коэффициент детерминации
- F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
- Сумма квадратов остатков
- Стандартная ошибка регрессии
- Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
- Задачи регрессионного анализа
- Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
- Основы линейной регрессии
- Что такое регрессия?
- Линия регрессии
- Метод наименьших квадратов
- Предположения линейной регрессии
- Аномальные значения (выбросы) и точки влияния
- Гипотеза линейной регрессии
- Оценка качества линейной регрессии: коэффициент детерминации R 2
- Применение линии регрессии для прогноза
- Простые регрессионные планы
- Пример: простой регрессионный анализ
- Задача исследования
- Просмотр результатов
- Коэффициенты регрессии
- Распределение переменных
- Диаграмма рассеяния
- Критерии значимости
- Регрессия в Excel: уравнение, примеры. Линейная регрессия
- Виды регрессии
- Пример 1
- Использование возможностей табличного процессора «Эксель»
- Линейная регрессия в Excel
- Анализ результатов регрессии для R-квадрата
- Задача о целесообразности покупки пакета акций
- Решение средствами табличного процессора Excel
- Изучение результатов и выводы
- Корреляция и регрессия
Понятие линейной регрессии. Парная линейная регрессия
Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. В отличие от функциональной зависимости y = f(x) , когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при линейной регрессии одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y.
Если в результате наблюдения установлено, что при каждом определённом значении x существует сколько-то (n) значений переменной y, то зависимость средних арифметических значений y от x и является регрессией в статистическом понимании.
Если установленная зависимость может быть записана в виде уравнения прямой
то эта регрессионная зависимость называется линейной регрессией.
О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y). Парная линейная регрессия называется также однофакторной линейной регрессией, так как один фактор (независимая переменная x) влияет на результирующую переменную (зависимую переменную y).
В уроке о корреляционной зависимости были разобраны примеры того, как цена на квартиры зависит от общей площади квартиры и от площади кухни (две различные независимые переменные) и о том, что результаты наблюдений расположены в некотором приближении к прямой, хотя и не на самой прямой. Если точки корреляционной диаграммы соединить ломанной линией, то будет получена линия эмпирической регрессии. А если эта линия будет выровнена в прямую, то полученная прямая будет прямой теоретической регрессии. На рисунке ниже она красного цвета (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши).

По этой прямой теоретической регрессии может быть сделан прогноз или восстановление неизвестных значений зависимой переменной по заданным значениям независимой переменной.
В случае парной линейной регрессии для данных генеральной совокупности связь между независимой переменной (факториальным признаком) X и зависимой переменной (результативным признаком) Y описывает модель
 ,
,
 — свободный член прямой парной линейной регрессии,
— свободный член прямой парной линейной регрессии,
 — коэффициент направления прямой парной линейной регрессии,
— коэффициент направления прямой парной линейной регрессии,
 — случайная погрешность,
— случайная погрешность,
N — число элементов генеральной совокупности.
Уравнение парной линейной регрессии для генеральной совокупности можно построить, если доступны данные обо всех элементах генеральной совокупности. На практике данные всей генеральной совокупности недоступны, но доступны данные об элементах некоторой выборки.
Поэтому параметры генеральной совокупности оценивают при помощи соответствующих параметров соответствующей выборки: свободный член прямой парной линейной регрессии генеральной совокупности заменяют на свободный член прямой парной линейной регрессии выборки  , а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки
, а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки  .
.
В результате получаем уравнение парной линейной регрессии выборки


 — оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
— оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
 — погрешность,
— погрешность,
n — размер выборки.
Чтобы уравнение парной линейной регрессии было более похоже на привычное уравнение прямой, его часто также записывают в виде
 .
.
Уравнение парной линейной регрессии и метод наименьших квадратов
Определение коэффициентов уравнения парной линейной регрессии
Если заранее известно, что зависимость между факториальным признаком x и результативным признаком y должна быть линейной, выражающейся в виде уравнения типа , задача сводится к нахождению по некоторой группе точек наилучшей прямой, называемой прямой парной линейной регрессии. Следует найти такие значения коэффициентов a и b , чтобы сумма квадратов отклонений  была наименьшей:
была наименьшей:
 .
.
Если через  и
и  обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
- прямая парной линейной регрессии проходит через точку
 ;
; - среднее значение отклонений равна нулю: ;
- значения и не связаны: .
 ;
; ;
; и
и  не связаны:
не связаны:  .
.Условие метода наименьших квадратов выполняется, если значения коэффициентов равны:
 ,
,
 .
.
Пример 1. Найти уравнение парной линейной регрессии зависимости между валовым внутренним продуктом (ВВП) и частным потреблением на основе данных примера урока о корреляционной зависимости (эта ссылка, которая откроется в новом окне, потребуется и при разборе следующих примеров).
Решение. Используем рассчитанные в решении названного выше примера суммы:




Используя эти суммы, вычислим коэффициенты:


Таким образом получили уравнение прямой парной линейной регрессии:

Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
Пример 2. Найти уравнение парной линейной регрессии для выборки из 6 наблюдений, если уже вычислены следующие промежуточные результаты:
 ;
;
 ;
;
 ;
;
 ;
;
Анализ качества модели линейной регрессии
Метод наименьших квадратов имеет по меньшей мере один существенный недостаток: с его помощью можно найти уравнение линейной регрессии и в тех случаях, когда данные наблюдений значительно рассеяны вокруг прямой регрессии, то есть находятся на значительном расстоянии от этой прямой. В таких случаях за точность прогноза значений зависимой переменной ручаться нельзя. Существуют показатели, которые позволяют оценить качество уравнения линейной регрессии прежде чем использовать модели линейной регрессии для практических целей. Разберём важнейшие из этих показателей.
Коэффициент детерминации
Коэффициент детерминации  принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
 ,
,
 — сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
— сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
 — общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
— общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
 — сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
— сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
Пример 3. Даны сумма квадратов отклонений, объясняемых моделью линейной регрессии (3500), общая сумма квадратов отклонений (5000) и сумма квадратов отклонений ошибки (1500). Найти коэффициент детерминации двумя способами.
F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
Минимальное возможное значение F-статистики — 0. Чем выше значение статистики Фишера, тем качественнее модель линейной регрессии. Этот показатель представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы):

где m — число объясняющих переменных.
Сумма квадратов остатков
Сумма квадратов остатков (RSS) измеряет необъясненную часть дисперсии зависимой переменной:

 —
—
остатки — разности между реальными значениями зависимой переменной и значениями, оценёнными уравнением линейной регрессии.
В случае качественной модели линейной регрессии сумма квадратов остатков стремится к нулю.
Стандартная ошибка регрессии
Стандартная ошибка регрессии (SEE) измеряет величину квадрата ошибки, приходящейся на одну степень свободы модели:

Чем меньше значение SEE, тем качественнее модель.
Пример 4. Рассчитать коэффициент детерминации для данных из примера 1.
Решение. На основании данных таблицы (она была приведена в примере урока о корреляционной зависимости) получаем, что SST = 63 770,593 , SSE = 10 459,587 , SSR = 53 311,007 .
Можем убедиться, что выполняется закономерность SSR = SST — SSE :
Получаем коэффициент детерминации:
 .
.
Таким образом, 83,6% изменений частного потребления можно объяснить моделью линейной регресии.
Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
Итак, уравнение парной линейной регрессии:
 .
.
В этом уравнении a — свободный член, b — коэффициент при независимой переменной.
Интерпретация свободного члена: a показывает, на сколько единиц график регрессии смещён вверх при x=0, то есть значение переменной y при нулевом значении переменной x.
Интерпретация коэффициента при независимой переменной: b показывает, на сколько единиц изменится значение зависимой переменной y при изменении x на одну единицу.
Пример 5. Зависимость частного потребления граждан от ВВП (истолкуем это просто: от дохода) описывается уравнением парной линейной регрессии  . Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
. Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
Решение. Подставляем в уравнение парной линейной регрессии x i = 20000 и получаем прогноз потребления при доходе в 20 000 у.е. y i = 17036,4662 .
Подставляем в уравнение парной линейной регрессии x i = 5000 и получаем прогноз увеличения потребления при увеличении дохода на 5000 у.е. y i = 4161,9662 .
Если доход не меняется, то x i = 0 и получаем, что потребление уменьшается на 129,5338 у.е.
Задачи регрессионного анализа
Регрессионный анализ — раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным.
Наиболее частые задачи регрессионного анализа:
- установление факта наличия или отсутствия статистических зависимостей между переменными величинами;
- выявление причинных связей между переменными величинами;
- прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных.
Также делаются проверки статистических гипотез о регрессии. Кроме того, при изучении связи между двумя величинами по результатам наблюдений в соответствии с теорией регрессии предполагается, что зависимая переменная имеет некоторое распределение вероятностей при фиксированном значении независимой переменной.
В исследованиях поведения человека, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
Одна из важнейших гипотез в регрессионном анализе — гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю.
Если это предположение верно, то изменения независимой переменной X не влияют на изменения зависимой переменной Y: переменные X и Y не коррелированы, то есть линейной зависимости Y от X нет.

рассматривают во взаимосвязи с альтернативной гипотезой
 .
.
Статистика коэффициента направления

соответствует распределению Стьюдента с числом степеней свободы v = n — 2 ,
где  — стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
— стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
Доверительный интервал коэффициента направления прямой линейной регрессии:
 .
.
Критическая область, в которой с вероятностью P = 1 — α отвергают нулевую гипотезу и принимают альтернативную гипотезу:

Пример 6. На основе данных из предыдущих примеров (о ВВП и частном потреблении) определить доверительный интервал коэффициента направления прямой линейной регресии 95% и проверить гипотезу о равенстве нулю коэффициента направления прямой парной линейной регрессии.
Можем рассчитать, что  , а стандартная погрешность регрессии
, а стандартная погрешность регрессии  .
.
Таким образом, стандартная погрешность коэффициента направления прямой линейной регресии b 1 :
 .
.
Так как  и
и  (находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
(находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
 .
.
Так как гипотетическое значение коэффициента — нуль — не принадлежит доверительному интервалу, с вероятностью 95% можем отвергнуть основную гипотезу и принять альтернативную гипотезу, то есть считать, что зависимая переменная Y линейно зависит от независимой переменной X.
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Регрессия в Excel: уравнение, примеры. Линейная регрессия
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику Фрэнсисом Гальтоном в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а0 + а1x1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Линейная регрессия в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
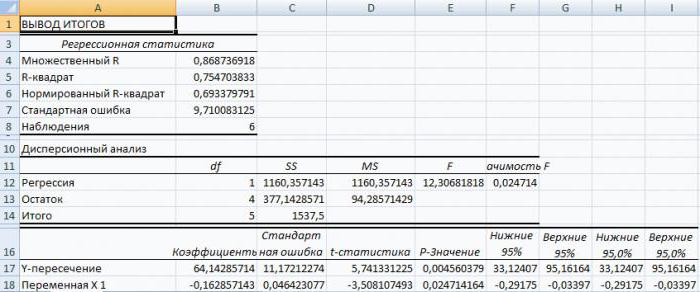
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
Значение t-статистики (критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
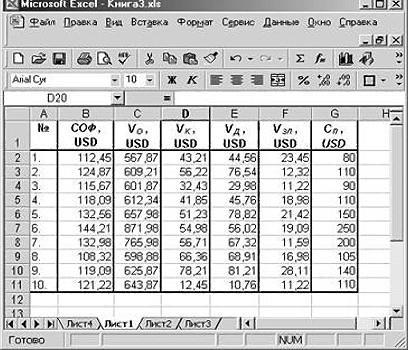
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:
- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
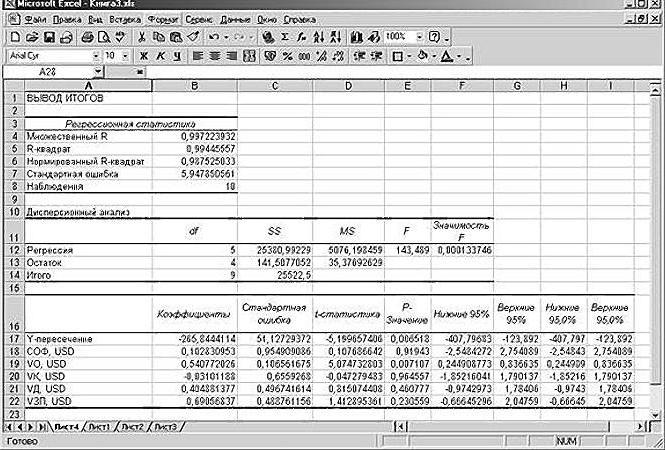
Получают анализ регрессии для данной задачи.
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
Корреляция и регрессия
Линейное уравнение регрессии имеет вид y=bx+a+ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид:
10a + 356b = 49
356a + 2135b = 9485
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 68.16, a = 11.17
Уравнение регрессии:
y = 68.16 x — 11.17
1. Параметры уравнения регрессии.
Выборочные средние.
1.1. Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 Y фактором X весьма высокая и прямая.
1.2. Уравнение регрессии (оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 68.16 x -11.17
Коэффициентам уравнения линейной регрессии можно придать экономический смысл. Коэффициент уравнения регрессии показывает, на сколько ед. изменится результат при изменении фактора на 1 ед.
Коэффициент b = 68.16 показывает среднее изменение результативного показателя (в единицах измерения у ) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 68.16.
Коэффициент a = -11.17 формально показывает прогнозируемый уровень у , но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений x , то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения x , можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и x определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
В нашем примере коэффициент эластичности больше 1. Следовательно, при изменении Х на 1%, Y изменится более чем на 1%. Другими словами — Х существенно влияет на Y.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего Y на 0.9796 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве регрессии.
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.98 2 = 0.9596, т.е. в 95.96 % случаев изменения x приводят к изменению у . Другими словами — точность подбора уравнения регрессии — высокая. Остальные 4.04 % изменения Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (xi— x ) 2 | |y — yx|:y |
| 0.371 | 15.6 | 0.1376 | 243.36 | 5.79 | 14.11 | 780.89 | 2.21 | 0.1864 | 0.0953 |
| 0.399 | 19.9 | 0.1592 | 396.01 | 7.94 | 16.02 | 559.06 | 15.04 | 0.163 | 0.1949 |
| 0.502 | 22.7 | 0.252 | 515.29 | 11.4 | 23.04 | 434.49 | 0.1176 | 0.0905 | 0.0151 |
| 0.572 | 34.2 | 0.3272 | 1169.64 | 19.56 | 27.81 | 87.32 | 40.78 | 0.0533 | 0.1867 |
| 0.607 | 44.5 | .3684 | 1980.25 | 27.01 | 30.2 | 0.9131 | 204.49 | 0.0383 | 0.3214 |
| 0.655 | 26.8 | 0.429 | 718.24 | 17.55 | 33.47 | 280.38 | 44.51 | 0.0218 | 0.2489 |
| 0.763 | 35.7 | 0.5822 | 1274.49 | 27.24 | 40.83 | 61.54 | 26.35 | 0.0016 | 0.1438 |
| 0.873 | 30.6 | 0.7621 | 936.36 | 26.71 | 48.33 | 167.56 | 314.39 | 0.0049 | 0.5794 |
| 2.48 | 161.9 | 6.17 | 26211.61 | 402 | 158.07 | 14008.04 | 14.66 | 2.82 | 0.0236 |
| 7.23 | 391.9 | 9.18 | 33445.25 | 545.2 | 391.9 | 16380.18 | 662.54 | 3.38 | 1.81 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=7 находим tкрит:
tкрит = (7;0.05) = 1.895
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 94.6484 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Sy = 9.7287 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя. (a + bxp ± ε) где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 1 (-11.17 + 68.16*1 ± 6.4554)
(50.53;63.44)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bx i ± ε)
где
| xi | y = -11.17 + 68.16xi | εi | ymin | ymax |
| 0.371 | 14.11 | 19.91 | -5.8 | 34.02 |
| 0.399 | 16.02 | 19.85 | -3.83 | 35.87 |
| 0.502 | 23.04 | 19.67 | 3.38 | 42.71 |
| 0.572 | 27.81 | 19.57 | 8.24 | 47.38 |
| 0.607 | 30.2 | 19.53 | 10.67 | 49.73 |
| 0.655 | 33.47 | 19.49 | 13.98 | 52.96 |
| 0.763 | 40.83 | 19.44 | 21.4 | 60.27 |
| 0.873 | 48.33 | 19.45 | 28.88 | 67.78 |
| 2.48 | 158.07 | 25.72 | 132.36 | 183.79 |
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (7;0.05) = 1.895
Поскольку 12.8866 > 1.895, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 2.0914 > 1.895, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(68.1618 — 1.895 • 5.2894; 68.1618 + 1.895 • 5.2894)
(58.1385;78.1852)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a — ta)
(-11.1744 — 1.895 • 5.3429; -11.1744 + 1.895 • 5.3429)
(-21.2992;-1.0496)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с lang=EN-US>n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=7, Fkp = 5.59
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция, нежели отрицательная автокорреляция. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения ei с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения ei (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скоре всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости ei от ei-1.