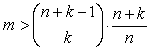Другой широко распространенной задачей обработки данных является представление их совокупности некоторой функцией у(х). Задача регрессии заключается в получении параметров этой функции такими, чтобы функция приближала облако исходных точек (заданных векторами VX и VY) с наименьшей среднеквадратичной погрешностью.
Чаще всего используется линейная регрессия, при которой функция у(х) имеет вид
и описывает отрезок прямой. К линейной регрессии можно свести многие виды нелинейной регрессии при двупараметрических зависимостях у(х) .
Для проведения линейной регрессии в систему встроен ряд приведенных ниже функций:
intercrpt(VX, VY) — возвращает значение параметра а (смещение линии регрессии по вертикали);
slope(VX, VY) — возвращает значение параметра b (наклона линии регрессии).
Функция для линейной регрессии общего вида.
В MathCAD реализована возможность выполнения линейной регрессии общего вида. При ней заданная совокупность точек приближается функцией вида:
F(x, K1, К2. Kn)=K1*F1(x)+K2*F2(x)+…+Kn*Fn(x).
Таким образом, функция регрессии является линейной комбинацией функций F1(x), F2(x). Fn(x), причем сами эти функции могут быть нелинейными, что резко расширяет возможности такой аппроксимации и распространяет ее на нелинейные функции.
Для реализации линейной регрессии общего вида используется функция linfit(VX,VY,F). Эта функция возвращает вектор коэффициентов линейной регрессии общего вида К, при котором среднеквадратичная погрешность приближения облака исходных точек, если их координаты хранятся в векторах VX и VY, оказывается минимальной. Вектор F должен содержать функции F1(x), F2(x). Fn(x), записанные в символьном виде.
Расположение координат точек исходного массива может быть любым, но вектор VX должен содержать координаты, упорядоченные в порядке их возрастания, а вектор VY — ординаты, соответствующие абсциссам в векторе VX.
Функции для одномерной и многомерной полиномиальной регрессии.
Введена в новую версию MathCAD и функция для обеспечения полиномиальной регрессии при произвольной степени полинома регрессии:
Она возвращает вектор VS, запрашиваемый функцией interp(VS,VX,VY,x), содержащий коэффициенты многочлена n-й степени, который наилучшим образом приближает “облако” точек с координатами, хранящимися в векторах VX и VY.
Для вычисления коэффициентов полинома регрессии используется функция submatrix.
На практике не рекомендуется делать степень аппроксимирующего полинома выше четвертой — шестой, поскольку погрешности реализации регрессии сильно возрастают.
Функция regress создает единственный приближающий полином, коэффициенты которого вычисляются по всей совокупности заданных точек, т. е. глобально. Иногда полезна другая функция полиномиальной регрессии, дающая локальные приближения отрезками полиномов второй степени, — loess(VX, VY, span ). Эта функция возвращает используемый функцией interp(VS,VX,VY,,r) вектор VS , дающий наилучшее приближение данных (с координатами точек в векторах VX и VY ) отрезками полиномов второй степени. Аргумент span>0 указывает размер локальной области приближаемых данных (рекомендуемое начальное значение — 0,75).
Чем больше span, тем сильнее сказывается сглаживание данных. При больших span regress(VX,VY,2) .
MathCAD позволяет выполнять также МНОГОМЕРНУЮ регрессию, самый типичный случай которой — приближение трехмерных поверхностей. Их можно характеризовать массивом значений высот z, соответствующих двумерному массиву Мху координат точек (х, у) на горизонтальной плоскости.
Новых функций для этого не задано. Используются уже описанные функции в несколько иной форме:
Regress (Mxy, Vz, n ) — возвращает вектор, запрашиваемый функцией interp (VS,Mxy,Vz,V) для вычисления многочлена п-й степени, который наилучшим образом приближает точки множества Мху и Vz. Мху — матрица mx2, содержащая координаты x и y.
Vz — m-мерный вектор, содержащий z-координат, соответствующих m точкам, указанным в Mxy ;
loes(Mxy,Vz,span) — аналогична loes(VX,VY, span), но в многомерном случае;
interp (VS,Mxy,Vz,V) — возвращает значение z по заданным векторам VS (создается функциями regress или loess ) и Мху , Vz и V (вектор координат х и у заданной точки, для которой находится z ).
Функция для нелинейной регрессии общего вида.
Под нелинейной регрессией общего вида подразумевается нахождение вектора К параметров произвольной функции F(x,K1,K2. Kn), при котором обеспечивается минимальная среднеквадратичная погрешность приближения облака исходных точек.
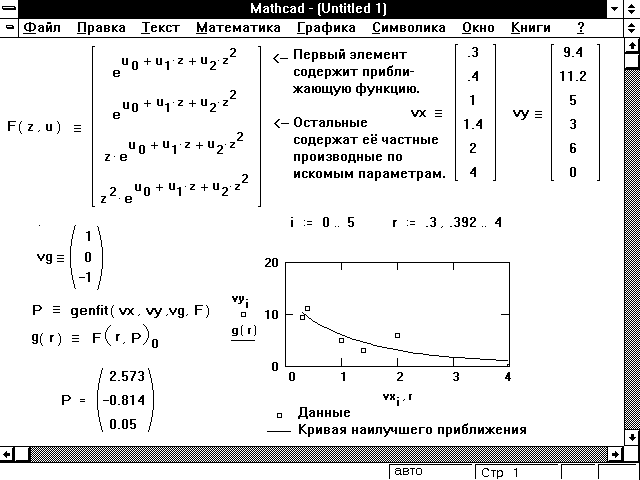
Для проведения нелинейной регрессии общего вида используется функция genfit(VX, VY, VS , F). Эта функция возвращает вектор К параметров функции F , дающий минимальную среднеквадратичную погрешность приближения функцией F(x,Kl,K2. Kn) исходных данных.
F должен быть вектором с символьными элементами, содержащими уравнение исходной функции и ее производных по всем параметрам. Вектор VS должен содержать начальные значения элементов вектора К, необходимые для решения системы нелинейных уравнений регрессии итерационным методом.
Уравнение линейной регрессии в mathcad
Mathcad включает ряд функций для вычисления регрессии. Обычно эти функции создают кривую или поверхность определенного типа, которая в некотором смысле минимизирует ошибку между собой и имеющимися данными. Функции отличаются прежде всего типом кривой или поверхности, которую они используют, чтобы аппроксимировать данные.
В отличие от функций интерполяции, обсужденных в предыдущем разделе, эти функции не требуют, чтобы аппроксимирующая кривая или поверхность проходила через точки данных. Функции регрессии, рассмотренные в этом разделе, следовательно, гораздо менее чувствительны к ошибкам данных, чем функции интерполяции. В отличие от функций сглаживания, рассматриваемых в следующем разделе, конечный результат регрессии — функция, с помощью которой можно оценить значения в промежутках между заданными точками.
Всякий раз, когда массивы используются в любой из функций, описанных в этом разделе, убедитесь, что каждый элемент в массиве содержит определённое значение, поскольку Mathcad присваивает 0 любым элементам, которые явно не определены.
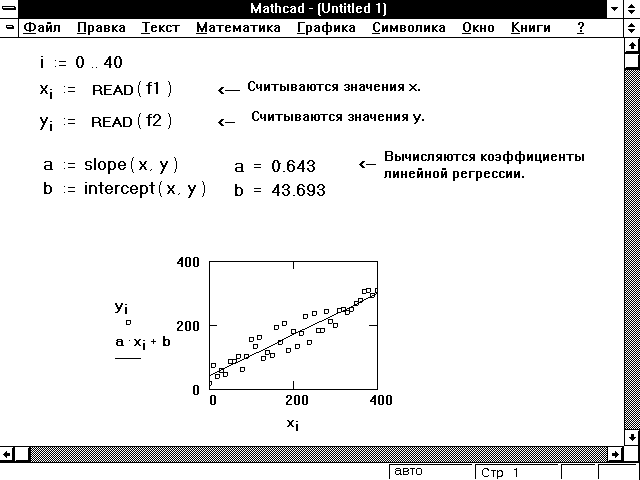
Эти функции возвращают наклон и смещение линии, которая наилучшим образом приближает данные в смысле наименьших квадратов. Если поместить значения x в вектор vx и соответствующие значения y в vy, то линия определяется в виде
y = slope(vx, vy)x + intercept(vx, vy)
slope(vx, vy)
Возвращает скаляр: наклон линии регрессии в смысле наименьших квадратов для данных из vx и vy.
intercept(vx, vy)
Возвращает скаляр: смещение по оси ординат линии регрессии в смысле наименьших квадратов для данных из vx и vy.
Рисунок 9 показывает, как можно использовать эти функции, чтобы провести линию через набор выборочных точек. Эти функции полезны не только, когда данные по существу должны представлять линейную зависимость, но и когда они представляют экспоненциальную зависимость. Например, если x и y связаны соотношением вида
можно применить эти функции к логарифму данных и использовать тот факт, что
A = exp(intercept(vx, vy)) и k = slope(vx, vy)
Такое приближение взвешивает ошибки по-другому, нежели приближение показательной функцией в смысле наименьших квадратов, но обычно это — хорошая аппроксимация.
Рисунок 9: Использование функций slope и intercept для линейной регрессии.
Эти функции полезны, когда есть набор измеренных сответствующих значений y и x, между которыми ожидается полиномиальная зависимость, и нужно приблизить эти значения с помощью полинома наилучшим в определённом смысле образом.
Используйте regress, когда нужно использовать единственный полином, чтобы приблизить все данные. Функция regress допускает использование полинома любого порядка. Однако на практике не следует использовать степень полинома выше n = 4.
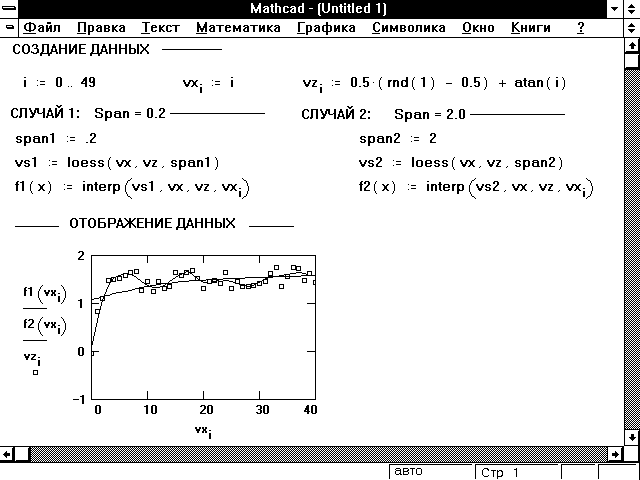
Так как regress пытается приблизить все точки данных, используя один полином, это не даст хороший результат, когда данные не связаны единой полиномиальной зависимостью. Например, предположим, ожидается, что зависят линейно от x в диапазоне от x1 до x10 и ведут себя подобно кубическому полиному в диапазоне от x11 до x20. Если используется regress с n = 3, можно получить хорошее приближение для второй половины, но ужасное — для первой. Функция loess облегчает эти проблемы, выполняя локальное приближение. Вместо создания одного полинома, как это делает regress, loess создаёт различные полиномы второго порядка в зависимости от расположения на кривой.
Она делает это, исследуя данные в малой окрестности точки, представляющей интерес. Аргумент span управляет размером этой окрестности. По мере того как диапазон становится большим, loess становится эквивалентным regress с n = 2. Хорошее значение по умолчанию — span = 0.75.
Рисунок 10 показывает, как span влияет на приближение, выполненное функцией loess. Заметьте, что меньшее значение span лучше приближает флуктуации данных. Большее значение span сглаживает колебания данных и создаёт более гладкую приближающую функцию.
Рисунок 10: Влияние различных значений span на функцию loess.
egress (vx, vy, n)
Возвращает вектор, требуемый interp, чтобы найти полином порядка n, который наилучшим образом приближает данные из vx и vy. vx есть m-мерный вектор, содержащий координаты x.vy есть m-мерный вектор, содержащий координаты y соответствующие m точкам, определенным в vx.
Е loess (vx, vy, span)
Возвращает вектор, требуемый interp, чтобы найти набор полиномов второго порядка, которые наилучшим образом приближают определённые окрестности выборочных точек, определенных в векторах vx и vy. vx есть m-мерный вектор, содержащий координаты x. vy — m-мерный вектор, содержащий координаты y, соответствующие m точкам, определенным в vx. Аргумент span > 0) определяет, насколько большие окрестности loess будет использовать при выполнении локального приближения.
interp (vs, vx, vy, x)
Возвращает интерполируемое значение y, соответствующее x. Вектор vs вычисляется loess или regress на основе данных из vx и vy.
Многомерная полиномиальная регрессия
Функции loess и regress, обсужденные в предыдущем разделе, также полезны, когда имеется набор измеренных величин z, соответствующих значениям x и y, и необходимо приблизить полиномами поверхность, проходящую через эти значения z.
Свойства этих функций описаны в предыдущем разделе. При использовании этих функций для приближения значений z, соответствующих двум независимым переменным x и y, толкования их аргументов должны быть изменены. А именно:
Аргумент vx, который был m-мерным вектором значений x, становится матрицей, состоящей из m рядов и 2 столбцов, Mxy. Каждая строка Mxy содержит x в первом столбце и соответствующее значение y во втором столбце.
Аргумент x для функции interp становится двумерным вектором v, чьи элементы — значения x и y, в которых нужно найти значение полиномиальной функции, представляющей наилучшее приближение данных из Mxy и vz.
regress (Mxy,vz, k)
Возвращает вектор, требуемый interp, чтобы найти полином k-ого порядка, который наилучшим образом приближает данные из Mxy и vz. Mxy есть m x 2 матрица, содержащая x—y координаты. vz есть m-мерный вектор, содержащий значения z, соответствующие точкам, определенным в Mxy.
Е loess (Mxy, vz, span)
Возвращает вектор, требуемый interp, чтобы найти набор полиномов второго порядка, которые наилучшим образом приближают определённые окрестности выборочных точек, определенных в массивах Mxy и vz. Mxy — m x 2 матрица, содержащая x-y координаты. vz — m — мерный вектор, содержащий координаты z, соответствующие m точкам, определенным в Mxy. Аргумент span (span > 0) определяет, насколько большую окрестность loess будет рассматривать при выполнении локального приближения.
interp (vs, Mxy, vz, v)
Возвращает интерполируемое значение z, соответствующее точке x = v0 и y = v1. Вектор vs вычисляется ? loess или regress на основе данных из Mxy и vz.
Можно увеличивать число независимых переменных, просто добавляя столбцы в массив Mxy, а затем добавляя соответствующее число строк к вектору v, который передается функции interp. Функция regress может иметь любое число независимых переменных. Но когда число независимых переменных и степень полинома больше четырёх, она будет работать медленнее и требовать большего количества памяти. Функция loess допускает максимум четыре независимых переменных.
Имейте в виду, что для regress число значений данных m должно удовлетворять соотношению
где n — число независимых переменных (следовательно, число столбцов в Mxy), k — желаемая степень полинома, и m — число значений данных (следовательно, число строк в vz). Например, если имеется пять независимых переменных, и ищется приближение полиномом четвёртой степени, потребуется более чем 126 наблюдений.
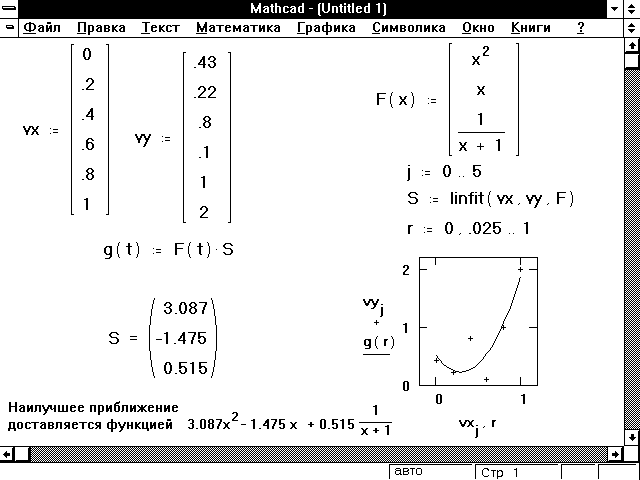
К сожалению, линейная или полиномиальная функции не во всех случаях подходят для описания зависимости данных. Бывает, что нужно искать эту зависимость в виде линейных комбинаций произвольных функций, ни одна из которых не является полиномом. Например, в рядах Фурье следует аппроксимировать данные, используя линейную комбинацию комплексных экспонент. Или предполагается, что данные могут быть смоделированы в виде линейной комбинации полиномов Лежандра, но только неизвестно, какие необходимо взять коэффициенты.
Функция linfit разработана, чтобы решить эти виды проблем. Если предполагается, что данные могли бы быть смоделированы в виде линейной комбинации произвольных функций
y = a0f0(x) + a1f1(x) +. + anfn(x)
следует использовать linfit, чтобы вычислить ai. Рисунок 11 показывает пример, в котором линейная комбинация трех функций: x, x 2 и (x + 1) -1 используется для моделирования некоторых данных.
Всё-таки имеются случаи, когда гибкость linfit недостаточна — данные должны быть смоделированы не линейной комбинацией данных, а некоторой функцией, чьи параметры должны быть выбраны. Например, если данные могут быть смоделированы в виде суммы
f(x) = a1sin(2x) + a2tanh(3x)
и всё, что нужно сделать — решить уравнение относительно неизвестных коэффициентов a1 и a2, значит эта проблема решается с помощью linfit.
В противоположность этому, если данные должны быть смоделированы в виде суммы
f(x) = 2sin(a1x) + 3tanh(a2x)
и требуется найти неизвестные параметры a1 и a2, то это задача для функции genfit.
linfit (vx, vy,F)
Возвращает вектор, содержащий коэффициенты, используемые, чтобы создать линейную комбинацию функций из F, дающую наилучшую аппроксимацию данных из векторов vx и vy. F — функция, которая возвращает вектор, состоящий из функций, которые нужно oбъединить в виде линейной комбинации.
Е genfit (vx, vy, vg, F)
Возвращает вектор, содержащий n параметров u0, u1. un-1, которые обеспечивают наилучшее приближение данных из vx и vy функцией f, зависящей от x и параметров u0, u1. un-1. F — функция, которая возвращает n+1-мерный вектор, содержащий f и ее частные производные относительно параметров. vg есть n-мерный вектор начальных значений для n параметров.
Рисунок 11: Использование linfit для нахождения коэффициентов в линейной комбинации функций, приближающей данные наилучшим образом.
Всё, что можно делать с помощью linfit, можно также делать, хотя и менее удобно, с genfit. Различие между этими двумя функциями есть различие между решением системы линейных уравнений и решением системы нелинейных уравнений. Первая задача легко решается методами линейной алгебры. Вторая задача гораздо более трудная и решается итеративными методами. Это объясняет, почему genfit нуждается в векторе начальных значений в качестве аргумента, а linfit в этом не нуждается.
Рисунок 12 показывает пример, в котором genfit используется, чтобы найти экспоненту, приближающую набор данных наилучшим образом.
Рисунок 12: Использование genfit для нахождения параметров функции, доставляющих ей наилучшее приближение к данным.
Исправляем ошибки: Нашли опечатку? Выделите ее мышкой и нажмите Ctrl+Enter
Электронная библиотека
Основным объектом исследования, как правило, является выборка экспериментальных данных, которая, чаще всего, представляется в виде массива, состоящего из пар чисел (xi,yi). В связи с этим возникает задача аппроксимации конкретной зависимости y(xi) непрерывной функцией f(х). Функция f(х), в зависимости от специфики задачи, может отвечать различным требованиям:
— f(х) должна проходить через точки (xi,yi), т.е. f(xi) = yi, i = 1…n. В этом случае говорят об интерполяции данных функцией f(х) во внутренних точках между xi или экстраполяции за пределами интервала, содержащего все хi;
— f(х) должна некоторым образом (например, в виде определенной аналитической зависимости) приближать y(xi), не обязательно проходя через точки (xi,yi).
Для построения интерполяции-экстраполяции в MathCAD имеется несколько встроенных функций, позволяющих «соединять» точки выборки данных (xi,yi) кривой разной степени гладкости. По определению интерполяция означает построение функции А(х), аппроксимирующей зависимость у(х) в промежуточных точках (между xi). Поэтому интерполяцию еще по-другому называют аппроксимацией. В точках xi значения интерполяционной функции должны совпадать с исходными данными, т.е. A(xi) = y (хi).
Рис. 8.1. Линейная интерполяция
Самый простой вид интерполяции – линейная, которая представляет искомую зависимость А(х) в виде ломаной линии. Интерполирующая функции А(х) состоит из отрезков прямых, соединяющих точки.
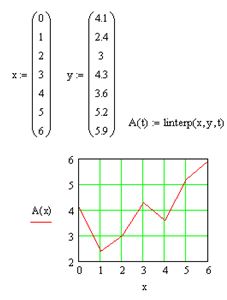
Для построения линейной интерполяции служит встроенная функция linterp (рис. 49) – функция, аппроксимирующая данные векторов х и у кусочно-линейной зависимостью linterp (х, у, t), где х – вектор действительных данных аргумента; у – вектор действительных данных значений того же размера; t – значение аргумента, при котором вычисляется интерполирующая функция.
Элементы вектора х должны быть определены в порядке возрастания, т.е. x1 3 + bt 2 + ct + d.
Коэффициенты а, b, с, d рассчитываются независимо для каждого промежутка исходя из значений yi в соседних точках. Этот процесс скрыт от пользователя, поскольку смысл задачи интерполяции состоит в выдаче значения A(t) в любом точке t (рис. 50). Выбор вспомогательных функций cspline, pspline, lspiine существенно влияет на поведение А(t) вблизи граничных точек рассматриваемого интервала (0, 6) и особенно разительно меняет результат экстраполяции данных за его пределами.
Если на графике задать построение функции А(х) вместо A(t), то будет получено просто соединение исходных точек ломаной. Так происходит потому, что в промежутках между точками вычисления интерполирующей функции не производятся.
Более сложный тип интерполяции – так называемая интерполяция В-сплайнами (рис. 51). В отличие от обычной сплайн-интерполяции сшивка элементарных В-сплайнов производится не в точках xi, а в других точках ui, координаты которых предлагается ввести пользователю. Сплайны могут быть полиномами 1, 2 или 3 степени (линейные, квадратичные или кубические). Применяется интерполяция В-сплайнами точно так же, как и обычная сплайн-интерполяция, различие со
стоит только в определении вспомогательной функции коэффициентов сплайна.
interp (s, х, у, t) – функция, аппроксимирующая данные векторов х с помощью В-сплайнов.
bspline(x, y, u, n) – вектор значений коэффициентов В-сплайна:
s – вектор вторых производных, созданный функцией bspiine;
х– вектор действительных данных аргумента, элементы которого расположены в порядке возрастания;
у – вектор действительных данных значений того же размера;
t – значение аргумента, при котором вычисляется интерполирующая функция;
u – вектор значений аргумента, в которых производится сшивка В- сплайнов;
n – порядок полиномов сплайновой интерполяции (1, 2 или 3).
Размерность вектора u должна быть на 1, 2 или 3 меньше размерности векторов х и у.
Первый элемент вектора и должен быть меньше или равен первому элементу вектора х, а последний элемент u – больше или равен последнему элементу х.
Для вычисления экстраполяции достаточно просто указать соответствующее значение аргумента, которое лежит за границами рассматриваемого интервала. С
этой точки зрения разницы в применении в MathCAD между интерполяцией и экстраполяцией нет.
На практике при построении экстраполяции следует соблюдать известную осторожность, не забывая о том, что ее успех определяется значимостью ближайших к границе интервала точек.
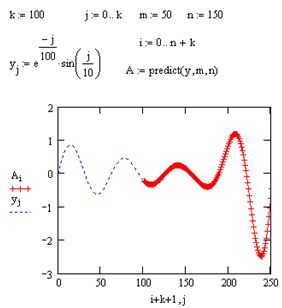
Стандартные функции интерполяции-экстраполяции стоит применять только в непосредственной близости границ интервала данных. В MathCAD имеется более развитый инструмент экстраполяции, который учитывает распределение данных вдоль всего интервала. В функцию predict встроен линейный алгоритм предсказания поведения функции, основанный на анализе, в том числе осцилляции:
predict (у, m, n) – функция предсказания вектора, экстраполирующего выборку данных:
у – вектор значений, взятых через равные промежутки значений аргумента;
m – количество последовательных элементов вектора у, согласно которым строится экстраполяция;
n – количество элементов вектора предсказаний.
Рис. 8.4. Функция предсказания
Пример использования функции предсказания на примере экстраполяции осциллирующих данных yj с меняющейся амплитудой приведен на рис. 52. Аргументы и принцип действия функции predict отличаются от рассмотренных выше встроен
ных функций интерполяции-экстраполяции. Значений аргумента для данных не требуется, поскольку по определению функция действует на данные, идущие друг за другом с равномерным шагом. Обратите внимание, что результат функции predict вставляется «в хвост» исходных данных.
Функция предсказания может быть полезна при экстраполяции данных на небольшие расстояния. Вдали от исходных данных результат часто бывает неудовлетворительным. Кроме того, функция predict хорошо работает в задачах анализа подробных данных с четко прослеживающейся закономерностью, в основном осциллирующего характера.
Задачи математической регрессии имеют смысл приближения выборки данных (xi, yi) некоторой функцией f(x), определенным образом минимизирующей совокупность ошибок |f(хi) – yi|. Регрессия сводится к подбору неизвестных коэффициентов, определяющих аналитическую зависимость f(х). В силу производимого действия большинство задач регрессии являются частным случаем более общей проблемы сглаживания данных. Как правило, регрессия очень эффективна, когда заранее известен (или, по крайней мере, хорошо угадывается) закон распределения данных (xi, yi).
Самый простой и наиболее часто используемый вид регрессии – линейная. Приближение данных (xi, yi) осуществляется линейной функцией у(х) = b + а · х. На координатной плоскости (х, у) линейная функция, как известно, представляется прямой линией. Еще линейную регрессию часто называют методом наименьших квадратов, поскольку коэффициенты а и b вычисляются из условия минимизации суммы квадратов ошибок |b+ a·xi – yi|.
Для расчета линейной регрессии в MathCAD имеется несколько способов. Выполняемые при этом действия дублируются, а результат получается одинаковым. Линейная регрессия по методу наименьших квадратов определяется функциями:
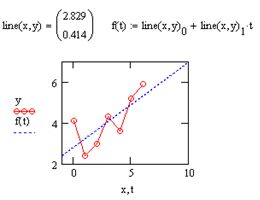
line(х, у) – вектор из двух элементов (b, а) коэффициентов линейной регрессии b + a · x (рис. 53);
intercept(х, у) – коэффициент b линейной регрессии;
slope(x,y) – коэффициент а линейной регрессии:
х – вектор действительных данных аргумента;
у – вектор действительных данных значений того же размера.
В MathCAD имеется альтернативный алгоритм, реализующий не минимизацию суммы квадратов ошибок, а медиан-медианную линейную регрессию для расчета коэффициентов а и b:
medfit(x, y) – вектор из двух элементов (b, а) коэффициентов линейном медиан-медианной регрессии b + а · х, где х, у – векторы действительных данных одинакового размера.
В MathCAD реализована регрессия одним полиномом, отрезками нескольких полиномов, а также двумерная регрессия массива данных.
Полиномиальная регрессия означает приближение данных (xi,yi) полиномом k-й степени a(x) = a + bx+cx 2 +dx 3 +…+h·x k при k = 1 полином является прямой линией, при k = 2 – параболой, при k = 3 – кубической параболой и т.д. Как правило, на практике применяются k Срочно? Закажи у профессионала, через форму заявки 8 (800) 100-77-13 с 7.00 до 22.00












 x + intercept(vx, vy)
x + intercept(vx, vy)