Во многих алгоритмах машинного обучения, в том числе в нейронных сетях, нам постоянно приходится иметь дело со взвешенной суммой или, иначе, линейной комбинацией компонент входного вектора. А в чём смысл получаемого скалярного значения?
В статье попробуем ответить на этот вопрос с примерами, формулами, а также множеством иллюстраций и кода на Python, чтобы вы могли легко всё воспроизвести и поставить свои собственные эксперименты.
Модельный пример
Чтобы теория не отрывалась от реальных кейсов, возьмём в качестве примера задачу бинарной классификации. Есть датасет: m образцов, каждый образец — n-мерная точка. Для каждого образца мы знаем к какому классу он относится (зелёный или красный). Также известно, что датасет является линейно разделимым, т.е. существует n-мерная гиперплоскость такая, что зелёные точки лежат по одну сторону от неё, а красные — по другую.

К решению задачи поиска такой гиперплоскости можно подходить разными способами, например с помощью логистической регрессии (logistic regression), метода опорных векторов с линейным ядром (linear SVM) или взять простейшую нейросеть:

В конце статьи мы с нуля напишем механизм обучения персептрона и решим задачу бинарной классификации своими руками, используя полученные знания.
От прямой линии до гиперплоскости
Рассмотрим подробную математику для прямой. Для общего случая гиперплоскости в n-мерном пространстве будет всё ровно тоже самое, с поправкой на количество компонент в векторах.

Прямая линия на плоскости задаётся тремя числами —  :
:



Первые два коэффициента  задают всё семейство прямых линий, проходящих через точку (0, 0). Соотношение между
задают всё семейство прямых линий, проходящих через точку (0, 0). Соотношение между  и
и  определяет угол наклона прямой к осям.
определяет угол наклона прямой к осям.
Если  , получаем линию, идущую под углом 45 градусов (
, получаем линию, идущую под углом 45 градусов ( ) к осям
) к осям  и
и  и делящую первый/третий квадранты пополам.
и делящую первый/третий квадранты пополам.
Ненулевой коэффициент  позволяет линии не проходить через ноль. При этом наклон к осям и не меняется. Т.е. задаёт семейство параллельных линий:
позволяет линии не проходить через ноль. При этом наклон к осям и не меняется. Т.е. задаёт семейство параллельных линий:
Геометрический смысл вектора  — это нормаль к прямой :
— это нормаль к прямой :
(Если не учитывать смещение , то  — это не более чем скалярное произведение двух векторов. Равенство нулю равносильно их ортогональности. Следовательно,
— это не более чем скалярное произведение двух векторов. Равенство нулю равносильно их ортогональности. Следовательно,  — семейство векторов, ортогональных
— семейство векторов, ортогональных  .)
.)
P.S. Понятно, что таких нормалей бесконечно много, как и троек (w1, w2, b) задающих прямую. Если все три числа умножить на ненулевой коэффициент  — прямая останется той же.
— прямая останется той же.
В общем случае n-мерного пространства,  задаёт n-мерную гиперплоскость.
задаёт n-мерную гиперплоскость.


Геометрический смысл линейной комбинации
Если точка  лежит на гиперплоскости, то
лежит на гиперплоскости, то
А что происходит с этой суммой, если точка не лежит на плоскости?
Гиперплоскость делит гиперпространство на два гиперподпространства. Так вот точки, находящиеся в одном из этих подпространств (условно говоря «выше» гиперплоскости), и точки, находящиеся в другом из этих подпространств (условно говоря «ниже» гиперплоскости), будут в этой сумме давать разный знак:
 0$» data-tex=»inline»/> — точка лежит «выше» гиперплоскости
0$» data-tex=»inline»/> — точка лежит «выше» гиперплоскости
 — точка лежит «ниже» гиперплоскости
— точка лежит «ниже» гиперплоскости
Это очень важное наблюдение, поэтому предлагаю его перепроверить простым кодом на Python:
Нужно понимать, что «выше» и «ниже» здесь — понятия условные. Это специально отражено в примере — зелёные точки оказываются визуально ниже. С геометрической точки зрения направление «выше» для данной конкретной линии определяется вектором нормали. Куда смотрит нормаль, там и верх:
Т.о. знак линейной комбинации позволяет отнести точку к верхнему или нижнему подпространству.
А значение? Значение (по модулю) определяет удалённость точки от плоскости:

Т.е. чем дальше от плоскости находится точка, тем больше будет значение линейной комбинации для неё. Если зафиксировать значение линейной комбинации, получим точки, лежащие на прямой, параллельной исходной.
Опять же, наблюдение важное, поэтому перепроверяем:
Выводы
- Линейная комбинация позволяет разделить n-мерное пространство гиперплоскостью.
- Точки по разные стороны гиперплоскости будут иметь разный знак линейной комбинации
 .
. - Чем точка удалённее от гиперплоскости, тем абсолютное значение линейной комбинации будет больше.
 .
.С точки зрения бинарной классификации последнее утверждение можно переформулировать следующим образом. Чем удалённее точка от гиперплоскости, являющейся границей решений (decision boundary), тем увереннее мы в том, что наш образец (sample) определяемый этой точкой попадает в тот или иной класс.
Близко и далеко: это как?
Близко и далеко — понятия сугубо субъективные. А при классификации отвечать нам нужно чётко — либо деталь годится для строительства ракеты для полёта на Марс, либо это брак. Либо человек кликнет по рекламе, либо нет. Возможно ответить с долей уверенности — дать вероятность позитивного (true) исхода.
Для этого к линейной комбинации можно применить функцию активации (в терминологии нейросетей).
Если применить логистическую функцию (график смотри ниже):

получаем на выходе вероятности и такую картинку:
Красные — точно нет (false, точно брак, точно не кликнет). Зелёные — точно да (true, точно годится, точно кликнет). Всё, что в определённом диапазоне близости от гиперплоскости (граница решений) получает некоторую вероятность. На самой прямой вероятность ровно 0.5.
P.S. «Точно» здесь определяется как меньше 0.001 или больше 0.999. Сама логистическая функция стремится к нулю на минус бесконечности и к единице на плюс бесконечности, но никогда этих значений не принимает.
N.B. Обратите внимание, что данный пример лишь демонстрирует каким образом можно ужать (squashing) расстояние со знаком в интервал вероятностей  . В практических задачах для поиска оптимального отображения используется калибровка вероятностей. Например, в алгоритме шкалирования по Платту (Platt scaling) логистическая функция параметризуется:
. В практических задачах для поиска оптимального отображения используется калибровка вероятностей. Например, в алгоритме шкалирования по Платту (Platt scaling) логистическая функция параметризуется:

и затем коэффициенты  и
и  подбираются машинным обучением. Подробнее смотрите: binary classifier calibration, probability calibration.
подбираются машинным обучением. Подробнее смотрите: binary classifier calibration, probability calibration.
В каком мы пространстве? (полезное умозрительное упражнение)
Казалось бы понятно — мы в пространстве данных  (data space), в котором лежат образцы . И ищем оптимальное разделение плоскостью, определяемой вектором
(data space), в котором лежат образцы . И ищем оптимальное разделение плоскостью, определяемой вектором  .
.
0$» data-tex=»inline»/> для зелёных точек
для красных точек
Но в нашей задаче бинарной классификации образцы зафиксированы, а веса меняются. Соответственно мы можем всё переиграть, перейдя в пространство весов  (weight space):
(weight space):

Образцы из тренировочного набора  в этом случае задают
в этом случае задают  гиперплоскостей и наша задача в том, чтобы найти такую точку , которая бы лежала с нужной стороны от каждой плоскости. Если исходный датасет является линейно-разделимым, то такая точка найдётся.
гиперплоскостей и наша задача в том, чтобы найти такую точку , которая бы лежала с нужной стороны от каждой плоскости. Если исходный датасет является линейно-разделимым, то такая точка найдётся.
При обучении модели удобнее рассуждать в пространстве весов, т.к. обновляются веса, а вектора-образцы из тренировочного набора задают нормали к гиперплоскостям. Например:
Предположим, что образцу соответствует зелёный класс, соответствующий неравенству:
 0$» data-tex=»inline»/>
0$» data-tex=»inline»/>
Т.к. на иллюстрации вектор смотрит против нормали , то значение линейной комбинации будет отрицательным — следовательно мы имеем ошибку классификации.
Соответственно необходимо обновить вектор в сторону, указываемую нормалью:
 , где
, где  0$» data-tex=»inline»/>
0$» data-tex=»inline»/>
с некоторой «скоростью»  . Тем самым на следующем шаге предсказание будет либо верным, либо менее неверным, т.к. слагаемое
. Тем самым на следующем шаге предсказание будет либо верным, либо менее неверным, т.к. слагаемое  , сонаправленное с нормалью, «довернёт» вектор весов в зелёную область.
, сонаправленное с нормалью, «довернёт» вектор весов в зелёную область.
Практика. Обучаем персептрон
Для решения задачи бинарной классификации в случае линейной разделимости образцов можно обучить простейший персептрон, устроенный по такой схеме:
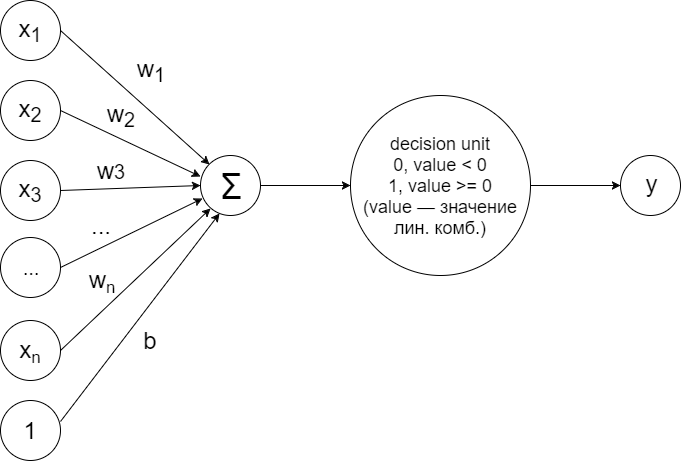
Эта конструкция реализует ровно тот принцип, который был описан выше. Вычисляется линейная комбинация:

По значению которой решатель (decision unit) принимает решение отнести образец к одному из двух классов по следующему принципу:
 класс +1 (зелёные точки)
класс +1 (зелёные точки)
класс -1 (красные точки)
Изначально веса инициализируются случайным образом, а на каждом шаге обучения для каждого образца проделывается следующий алгоритм:
Вычисляется предсказание (predicted label). Если оно не совпадает с реальным классом, то веса обновляются по следующему принципу:

где  — реальный класс образца
— реальный класс образца  . Почему это работает описано выше в умозрительном упражнении с переходом в пространство весов. Кратко:
. Почему это работает описано выше в умозрительном упражнении с переходом в пространство весов. Кратко:
- Доворачиваем вектор-вес в сторону верного класса: по нормали в случае класса +1; против нормали в случае класса -1. (Сама нормаль всегда смотрит в сторону класса +1.)
- Обновляем смещение по аналогичному принципу.
Вот что получается:
Заглянем теперь в пространство весов (weight space):
Красные и зелёные линии — это исходные образцы, синяя точка — итоговый вес.
А какие ещё веса дают верную классификацию? Смотрим:
Красные и зелёные линии — это исходные образцы, синяя точка — итоговый вес, фиолетовые точки — другие возможные веса.
И выворачиваем всё наизнанку ещё раз, переходя опять в пространство данных (data space):
Те веса, которые в пространстве весов на иллюстрации выше были отмечены фиолетовыми точками, здесь, в пространстве данных, стали линиями других возможных границ решения.
Упражнение (простое): На последней иллюстрации четыре характерных пучка линий. Найдите их среди фиолетовых точек в пространстве весов.
От автора
Спасибо всем хабровчанам за критические отзывы касательно первой версии статьи, в том числе yorko, который вместе с сообществом Open Data Science делает суперский открытый курс по машинному обучению — всем рекомендую.
Стало понятно, что материалу не хватает финального штриха и статья была отправлена на доработку. Вторая (она же текущая) версия дополнена примером обучения персептрона.
Итоги
Надеюсь эта статья позволит вам лучше понять и прочувствовать геометрический смысл линейных комбинаций. Ниже приведены ссылки на материалы, использованные при подготовке статьи и интересные с точки зрения углубления в тему. (Все материалы на английском языке.)
- Geoffrey Hinton. An overview of the main types of neural network architecture
Подробнее про обучение персептрона с переходом в пространство весов от гуру нейронных сетей Джеффри Хинтона.
Supervised Learning / Support Vector Machines
Про решение задач бинарной классификации методом опорных векторов и как с точки зрения этого алгоритма выбрать оптимальную разделяющую плоскость.
Hyperplane based сlassification: Perceptron and (Intro to) Support Vector Machines
Опять про персептроны, вскользь про метод опорных векторов. Детально рассматривается вопрос обучения и корректировки весов.
Polyhedra and Linear Programming. Polyhedra, Polytopes, and Cones
Линейная алгебра линейных комбинаций (теория) с множеством иллюстративных примеров.