Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
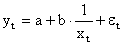
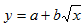
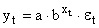
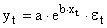

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
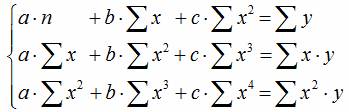
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
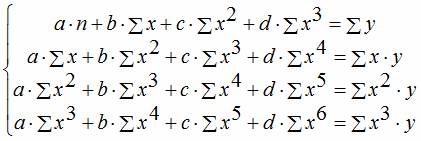
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Полиномиальная регрессия
Дата публикации Oct 8, 2018
Это мой третий блог в серии машинного обучения. Этот блог требует предварительных знаний о линейной регрессии. Если вы не знаете о линейной регрессии или нуждаетесь в обновлении, просмотрите предыдущие статьи этой серии.
Линейная регрессия требует, чтобы отношение между зависимой переменной и независимой переменной было линейным. Что если распределение данных было более сложным, как показано на рисунке ниже? Можно ли использовать линейные модели для подбора нелинейных данных? Как мы можем создать кривую, которая лучше всего отражает данные, как показано ниже? Что ж, мы ответим на эти вопросы в этом блоге.

Оглавление
- Почему полиномиальная регрессия
- Переоснащение против Подгонка
- Уклон против Различий компромиссов
- Применение полиномиальной регрессии к бостонскому набору данных.
Почему полиномиальная регрессия?
Чтобы понять необходимость полиномиальной регрессии, давайте сначала сгенерируем случайный набор данных.
Сгенерированные данные выглядят как

Давайте применим модель линейной регрессии к этому набору данных.
Сюжет самой подходящей линии

Мы можем видеть, что прямая линия не может захватить шаблоны в данных. Это примерпод-фитинга, Вычисление RMSE и R²-показателя линейной линии дает:
Чтобы преодолеть несоответствие, нам нужно увеличить сложность модели.
Чтобы сгенерировать уравнение более высокого порядка, мы можем добавить мощности оригинальных функций в качестве новых. Линейная модель,

может быть преобразован в

Это все еще считаетсялинейная модельпоскольку коэффициенты / веса, связанные с признаками, все еще линейны. x² это только особенность. Однако кривая, которая нам подходитквадратныйв природе.
Для преобразования оригинальных функций в условия высшего порядка мы будем использовать PolynomialFeatures класс предоставлен scikit-learn , Далее мы обучаем модель с использованием линейной регрессии.
Подгонка модели линейной регрессии к преобразованным объектам дает график ниже.

Из графика совершенно ясно, что квадратичная кривая может соответствовать данным лучше, чем линейная линия. Вычисление RMSE и R²-балла квадратичного графика дает:
Мы можем видеть, что среднеквадратичное отклонение уменьшилось, а показатель R² увеличился по сравнению с линейной линией
Если мы попытаемся подогнать кубическую кривую (степень = 3) к набору данных, мы увидим, что он проходит через больше точек данных, чем квадратичный и линейный графики.

Метрика кубической кривой
Ниже приведено сравнение подгонки линейных, квадратичных и кубических кривых к набору данных.

Если мы продолжим увеличивать степень до 20, мы увидим, что кривая проходит через большее количество точек данных. Ниже приведено сравнение кривых для степени 3 и 20.

Для степени = 20 модель также фиксирует шум в данных. Это примернад-фитинга, Даже если эта модель проходит через большую часть данных, она не сможет обобщить невидимые данные.
Чтобы избежать перестройки, мы можем добавить больше обучающих выборок, чтобы алгоритм не распознавал шум в системе и мог стать более обобщенным.(Примечание: добавление дополнительных данных может быть проблемой, если данные сами по себе являются помехами).
Как выбрать оптимальную модель? Чтобы ответить на этот вопрос, нам нужно понять компромисс между компромиссом и дисперсией.
Компромисс против дисперсии
предвзятостьотносится к ошибке из-за упрощенных предположений модели при подборе данных. Высокое смещение означает, что модель не может захватить шаблоны в данных, и это приводит кпод-фитинга,
отклонениеотносится к ошибке из-за сложной модели, пытающейся соответствовать данным. Высокая дисперсия означает, что модель проходит через большинство точек данных, и это приводит кнад-фитингаданные.
На картинке ниже представлены результаты нашего обучения.

Из рисунка ниже мы можем наблюдать, что с увеличением сложности модели смещение уменьшается, а дисперсия увеличивается, и наоборот. В идеале модель машинного обучения должна иметьнизкая дисперсия и низкий уклон, Но практически невозможно иметь оба. Поэтому, чтобы получить хорошую модель, которая хорошо работает как на поездах, так и на невидимых данных,компромисссделан.

До сих пор мы рассмотрели большую часть теории полиномиальной регрессии. Теперь давайте реализуем эти концепции в наборе данных Boston Housing, который мы проанализировали впредыдущийблог.
Применение полиномиальной регрессии к набору данных Housing
Из рисунка ниже видно, что LSTAT имеет небольшое нелинейное изменение с целевой переменной MEDV , Мы преобразуем исходные функции в полиномы более высокой степени, прежде чем обучать модель

Давайте определим функцию, которая преобразует исходные элементы в полиномиальные элементы заданной степени, а затем применяет к ним линейную регрессию.
Далее мы вызываем вышеуказанную функцию со степенью 2.
Производительность модели с использованием полиномиальной регрессии:
Это лучше, чем мы достигли с помощью линейной регрессии впредыдущийблог.
Вот и все для этой истории. Это GithubСделки рЕПОсодержит весь код для этого блога, и можно найти полный блокнот Jupyter, используемый для набора данных жилья в БостонеВот,
Вывод
В этой серии машинного обучения мы рассмотрели линейную регрессию, полиномиальную регрессию и реализовали обе эти модели в наборе данных Boston Housing.
Мы расскажем о логистической регрессии в следующем блоге.
Полиномиальная регрессия
Полиномиальная регрессия означает приближение данных ( xi , yi ) полиномом k —й степени A ( x ) = a + b – x + c – x 2 + d – x 3 + . + h – x k . При k = 1 полином описывают прямой линией, при k = 2 – параболой, при k = 3 – кубической параболой и т.д. Как правило, на практике применяют k . Надо иметь в виду, что для построения регрессии полиномом k —й степени необходимо наличие по крайней мере ( k + l ) точек данных.
Чтобы осуществить полиномиальную регрессию с помощью MathCAD , надо выполнить следующие действия:
В главном меню необходимо выбрать «Вид – Панели инструментов – Матрица» , после чего в появившейся панели « Matrix » выбрать «Создать матрицу» на 1 строку и 7 столбцов и ввести координаты по оси x . Далее с помощью элемента «Транспонирование матрицы» той же панели транспонировать матрицу данных
х : = (0 1 2 3 4 5 6) Т .
Аналогичную операцию проводим с координатами по оси у
у : = (4,7 2,6 3,5 4,4 3,3 5,2 5,1) Т .
В MathCAD полиномиальная регрессия осуществляется комбинацией встроенной функции regress и полиномиальной интерполяции:
– regress ( х , у, k ) – вектор коэффициентов для построения полиномиальной регрессии данных;
– interp ( s , x , y , t ) – результат полиномиальной регрессии;
– х – вектор действительных данных аргумента, элементы которого расположены в порядке возрастания;
– у – вектор действительных данных значений того же размера;
– k – степень полинома регрессии (целое положительное число);
– t – значение аргумента полинома регрессии.
Для построения полиномиальной регрессии после функции regress необходимо использовать функцию interp .
Далее записываем функцию полиномиальной регрессии как А ( t ): = interp ( s , x , y , t ).
Чтобы построить график, необходимо выбрать в главном меню «Вид – Панели инструментов – График» , далее на появившейся панели « Graph » выбрать элемент «Декартов график» , после чего на рабочей области программы MathCAD появится область построения графика. По оси ординат области построения графика необходимо ввести « A ( t ), y », а по оси абсцисс « t , x ». Далее двойным щелчком левой кнопки мыши по области построения графика необходимо вызвать панель форматирования графика, на которой выбрать закладку «Трассировки», выделить мышью « trace 2» и в поле «Символ» выбрать « dmnd ». Кроме того, для удобства можно установить диапазон значений по оси абсцисс, вводя соответствующие значения в области на оси x графика. Поскольку значения по оси х изменяются от 0 до 6, их и введём. Полученный график показан ниже.

Рис. Регрессия полиномом второй степени
Кроме того, мы можем рассчитать значение функции A ( t ) в требуемых точках. Например, для точки с аргументом x = 1,5 значение аппроксимирующей функции A ( t ) будет: A ( 1,5) = 3,553.