По семи территориям Уральского района за 199Х г. известны значения двух признаков.
| Район | Расходы на покупку продовольственных товаров в общих расходах, %, у | Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская респ. | 68,8 | 45,1 |
| Свердловская обл. | 61,2 | 59,0 |
| Башкортостан | 59,9 | 57,2 |
| Челябинская обл. | 56,7 | 61,8 |
| Пермская обл. | 55,0 | 58,8 |
| Курганская обл. | 54,3 | 47,2 |
| Оренбургская обл. | 49,3 | 55,2 |
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации Аср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
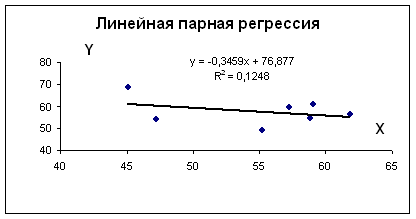
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Мой секрет
Средняя ошибка аппроксимации в excel. Оценка качества уравнения регрессии
Где y x — расчетное значение по уравнению.
Значение средней ошибки аппроксимации до 15% свидетельствует о хорошо подобранной модели уравнения.
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации А ср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии .
а) линейное уравнение регрессии;
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции .

На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения ε i для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям x i и y i можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где e i – наблюдаемые значения (оценки) ошибок ε i , а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Получаем b = -0.35, a = 76.88
Уравнение регрессии:
y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x y | y(x) | (y i -y cp) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
F-статистики. Критерий Фишера.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
, а затем на комбинацию клавиш + + .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Стандартная ошибка b | Стандартная ошибка a | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Стандартная ошибка y | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| F-статистика | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Регрессионная сумма квадратов
Рисунок 4 Результат вычисления функции ЛИНЕЙН Получили уровнение регрессии: Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб. Означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель. По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: Связь оценивается как тесная. 4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат. Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:
Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее , и то же самое произведём со значениями у.
Рисунок 5 Расчёт средних значений функции и аргумент Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%. С помощью инструмента анализа данных Регрессия можно получить: Порядок действий следующий: 1) проверьте доступ к Пакету анализа . В главном меню последовательно выберите: Файл/Параметры/Надстройки . 2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти. 3) В окне Надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК . Если Пакет анализа отсутствует в списке поля Доступные надстройки , нажмите кнопку Обзор , чтобы выполнить поиск. Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да , чтобы установить его. 4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия , а затем нажмите кнопку ОК . 5) Заполните диалоговое окно ввода данных и параметров вывода: Входной интервал Y — диапазон, содержащий данные результативного признака; Входной интервал X — диапазон, содержащий данные факторного признака; Метки — флажок, который указывает, содержит ли первая строка названия столбцов или нет; Константа — ноль — флажок, указывающий на наличие или отсутствие свободного члена в уравнении; Выходной интервал — достаточно указать левую верхнюю ячейку будущего диапазона; 6) Новый рабочий лист — можно задать произвольное имя нового листа. Затем нажмите кнопку ОК .
Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия Результаты регрессионного анализа для данных задачи представлены на рисунке 7.
Рисунок 7 Результат применения инструмента регрессия 5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.
Рисунок 8 Результат применения инструмента регрессия «Вывод остатка» Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:
Рисунок 9 Расчёт средней ошибки аппроксимации Средняя ошибка аппроксимации рассчитывается по формуле:
Качество построенной модели оценивается как хорошее, так как не превышает 8 — 10%. 6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: Поскольку 8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей. Выдвигаем гипотезу Н 0 о статистически незначимом отличии показателей от нуля:
На рисунке 7 имеются фактические значения t-статистики: t-критерий для коэффициента корреляции можно рассчитать двумя способами: где Данные для расчёта возьмём из таблицы на Рисунке 7.
Фактические значения t-статистики превосходят табличные значения: Поэтому гипотеза Н 0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы. Доверительный интервал для параметра a определяется как
Для параметра a 95%-ные границы как показано на рисунке 7 составили: Доверительный интервал для коэффициента регрессии определяется как
Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью 7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит: Тогда прогнозное значение прожиточного минимума составит: Ошибку прогноза рассчитаем по формуле:
где Дисперсию посчитаем также с помощью ППП Excel. Для этого: 1) Активизируйте Мастер функций : в главном меню выберете Формулы / Вставить функцию . 3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК .
Рисунок 10 Расчёт дисперсии Получили значение дисперсии Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.
Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:
Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным. Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. — М.: Финансы и статистика, 2003. — 192 с.: ил. Для общей оценки качества построенной эконометрической определяются такие характеристики как коэффициент детерминации, индекс корреляции, средняя относительная ошибка аппроксимации, а также проверяется значимость уравнения регрессии с помощью F -критерия Фишера. Перечисленные характеристики являются достаточно универсальными и могут применяться как для линейных, так и для нелинейных моделей, а также моделей с двумя и более факторными переменными. Определяющее значение при вычислении всех перечисленных характеристик качества играет ряд остатков ε i , который вычисляется путем вычитания из фактических (полученных по наблюдениям) значений исследуемого признака y i значений, рассчитанных по уравнению модели y рi . показывает, какая доля изменения исследуемого признака учтена в модели. Другими словами коэффициент детерминации показывает, какая часть изменения исследуемой переменной может быть вычислена, исходя из изменений включённых в модель факторных переменных с помощью выбранного типа функции, связывающей факторные переменные и исследуемый признак в уравнении модели. Коэффициент детерминации R 2 может принимать значения от 0 до 1. Чем ближе коэффициент детерминации R 2 к единице, тем лучше качество модели. Индекс корреляции можно легко вычислить, зная коэффициент детерминации: Индекс корреляции R характеризует тесноту выбранного при построении модели типа связи между учтёнными в модели факторами и исследуемой переменной. В случае линейной парной регрессии его значение по абсолютной величине совпадает с коэффициентом парной корреляции r (x, y) , который мы рассмотрели ранее, и характеризует тесноту линейной связи между x и y . Значения индекса корреляции, очевидно, также лежат в интервале от 0 до 1. Чем ближе величина R к единице, тем теснее выбранный вид функции связывает между собой факторные переменные и исследуемый признак, тем лучше качество модели. выражается в процентах и характеризует точность модели. Приемлимая точность модели при решении практических задач может определяться, исходя из соображений экономической целесообразности с учётом конкретной ситуации. Широко применяется критерий, в соответствии с которым точность считается удовлетворительной, если средняя относительная погрешность меньше 15%. Если E отн.ср. меньше 5%, то говорят, что модель имеет высокую точность. Не рекомендуется применять для анализа и прогноза модели с неудовлетворительной точностью, то есть, когда E отн.ср. больше 15%. F-критерий Фишера используется для оценки значимости уравнения регрессии. Расчётное значение F-критерия определяется из соотношения: Критическое значение F -критерия определяется по таблицам при заданном уровне значимости α и степенях свободы (можно использовать функцию FРАСПОБР в Excel). Здесь, по-прежнему, m – число факторов, учтённых в модели, n – количество наблюдений. Если расчётное значение больше критического, то уравнение модели признаётся значимым. Чем больше расчётное значение F -критерия, тем лучше качество модели. Определим характеристики качества построенной нами линейной модели для Примера 1 . Воспользуемся данными Таблицы 2. Коэффициент детерминации : Следовательно, в рамках линейной модели изменение объёма продаж на 90,1% объясняется изменением температуры воздуха. Значение индекса корреляции в случае парной линейной модели как мы видим, действительно по модулю равно коэффициенту корреляции между соответствующими переменными (объём продаж и температура). Поскольку полученное значение достаточно близко к единице, то можно сделать вывод о наличии тесной линейной связи между исследуемой переменной (объём продаж) и факторной переменноё (температура).
Критическое значение F кр при α = 0,1; ν 1 =1; ν 2 =7-1-1=5 равно 4,06. Расчётное значение F -критерия больше табличного, следовательно, уравнение модели является значимым. Средняя относительная ошибка аппроксимации Построенная линейная модель парной регрессии имеет неудовлетворительную точность (>15%), и её не рекомендуется использовать для анализа и прогнозирования. В итоге, несмотря на то, что большинство статистических характеристик удовлетворяют предъявляемым к ним критериям, линейная модель парной регрессии непригодна для прогнозирования объёма продаж в зависимости от температуры воздуха. Нелинейный характер зависимости между указанными переменными по данным наблюдений достаточно хорошо виден на Рис.1. Проведённый анализ это подтвердил. Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами. Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче. Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции. Но она может быть построена с применением одного из пяти видов аппроксимации:
Рассмотрим каждый из вариантов более подробно в отдельности. Способ 1: линейное сглаживаниеПрежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем. Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
Сглаживание, которое используется в данном случае, описывается следующей формулой: В конкретно нашем случае формула принимает такой вид: Величина достоверности аппроксимации у нас равна 0,9418 , что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное. Способ 2: экспоненциальная аппроксимацияТеперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
Общий вид функции сглаживания при этом такой: где e – это основание натурального логарифма. В конкретно нашем случае формула приняла следующую форму: Способ 3: логарифмическое сглаживаниеТеперь настала очередь рассмотреть метод логарифмической аппроксимации.
В общем виде формула сглаживания выглядит так: где ln – это величина натурального логарифма. Отсюда и наименование метода. В нашем случае формула принимает следующий вид: Способ 4: полиномиальное сглаживаниеНастал черед рассмотреть метод полиномиального сглаживания.
Формула, которая описывает данный тип сглаживания, приняла следующий вид: Способ 5: степенное сглаживаниеВ завершении рассмотрим метод степенной аппроксимации в Excel.
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений. Общая формула, описывающая данный метод имеет такой вид: В конкретно нашем случае она выглядит так: Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844 ), наименьший уровень достоверности у линейного метода (0,9418 ). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации. Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант. Контрольная работа: Парная регрессия
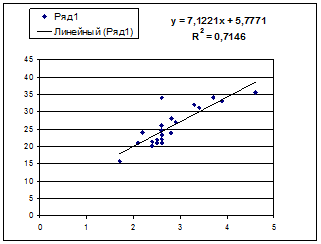
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи. 2. Рассчитайте параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессий. 3. Оцените тесноту связи с помощью показателей корреляции и детерминации. 4. С помощью среднего (общего) коэффициента эластичности дайте сравнительную оценку силы связи фактора с результатом. 5. Качество уравнений оцените с помощью средней ошибки аппроксимации. 6. С помощью F-критерия Фишера определите статистическую надежность результатов регрессионного моделирования. Выберите лучшее уравнение регрессии и дайте его обоснование. 7. Рассчитайте прогнозное значение результата по линейному уравнению регрессии, если прогнозное значение фактора увеличится на 7% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости α=0,05. 8. Оцените полученные результаты, выводы оформите в аналитической записке. 1. Поле корреляции для: · Линейной регрессии y=a+b*x:
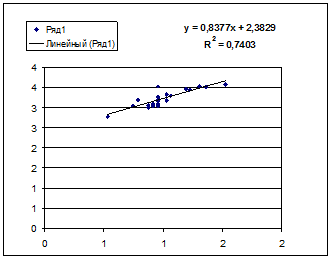
Гипотеза о форме связи: чем больше размер среднедушевого денежного дохода в месяц (факторный признак), тем больше при прочих равных условиях розничная продажа телевизоров (результативный признак). В данной модели параметр b называется коэффициентом регрессии и показывает, насколько в среднем отклоняется величина результативного признака у при отклонении величины факторного признаках на одну единицу. · Степенной регрессии
Гипотеза о форме связи : степенная функция имеет вид Y=ax b . Параметр b степенного уравнения называется показателем эластичности и указывает, на сколько процентов изменится у при возрастании х на 1%. При х = 1 a = Y. · Экспоненциальная регрессия
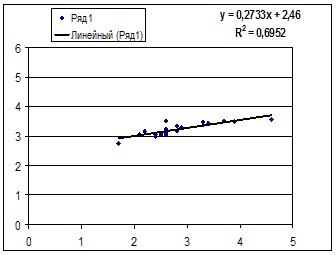
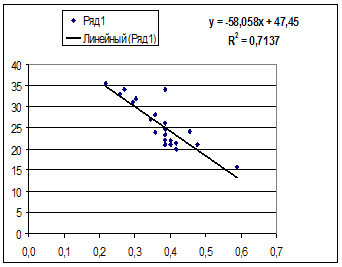
· Равносторонняя гипербола
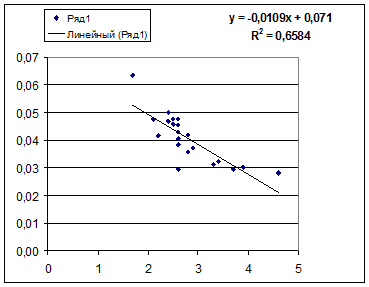
Гипотеза о форме связи: В ряде случаев обратная связь между факторным и результативным признаками может быть выражена уравнением гиперболы: Y=a+b/x. · Обратная гипербола
· Полулогарифмическая регрессия
2. Рассчитайте параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессий. · Рассчитаем параметры уравнений линейной парной регрессии. Для расчета параметров a и b линейной регрессии y=a+b*x решаем систему нормальных уравнений относительно a и b:
По исходным данным рассчитываем ∑y, ∑x, ∑yx, ∑x 2 , ∑y 2 (табл. 2):
Система нормальных уравнений составит:
· Рассчитаем параметры уравнений степенной парной регрессии. Построению степенной модели Для расчетов используем данные табл. 3:
Рассчитаем С и b:
Получим линейное уравнение: Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата y . · Рассчитаем параметры уравнений экспоненциальной парной регрессии. Построению экспоненциальной модели Для расчетов используем данные табл. 4:
Рассчитаем С и b:
Получим линейное уравнение: Для расчета теоретических значений y подставим в уравнение · Рассчитаем параметры уравнений полулогарифмической парной регрессии. Построению полулогарифмической модели Для расчетов используем данные табл. 5:
Рассчитаем a и b:
Получим линейное уравнение: · Рассчитаем параметры уравнений обратной парной регрессии. Для оценки параметров приведем обратную модель Для расчетов используем данные табл. 6:
Рассчитаем a и b:
Получим линейное уравнение: Для расчета теоретических значений y подставим в уравнение · Рассчитаем параметры уравнений равносторонней гиперболы парной регрессии. Для оценки параметров приведем модель равносторонней гиперболы Для расчетов используем данные табл. 7:
Рассчитаем a и b:
Получим линейное уравнение: 3. Оценка тесноты связи с помощью показателей корреляции и детерминации : · Линейная модель. Тесноту линейной связи оценит коэффициент корреляции. Был получен следующий коэффициент корреляции rxy =b · Степенная модель. Тесноту нелинейной связи оценит индекс корреляции. Был получен следующий индекс корреляции · Экспоненциальная модель. Был получен следующий индекс корреляции ρxy =0,8124, что говорит о том, что связь прямая и очень сильная, но немного слабее, чем в линейной и степенной моделях. Коэффициент детерминации r²xy =0,66. Это означает, что 66% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц. · Полулогарифмическая модель. Был получен следующий индекс корреляции ρxy =0,8578, что говорит о том, что связь прямая и очень сильная, но немного больше чем в предыдущих моделях. Коэффициент детерминации r²xy =0,7358. Это означает, что 73,58% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц. · Гиперболическая модель. Был получен следующий индекс корреляции ρxy =0,8448 и коэффициент корреляции rxy =-0,1784 что говорит о том, что связь обратная очень сильная. Коэффициент детерминации r²xy =0,7358. Это означает, что 73,5% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц. · Обратная модель. Был получен следующий индекс корреляции ρxy =0,8114 и коэффициент корреляции rxy =-0,8120, что говорит о том, что связь обратная очень сильная. Коэффициент детерминации r²xy =0,6584. Это означает, что 65,84% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц. Вывод: по полулогарифмическому уравнению получена наибольшая оценка тесноты связи: ρxy =0,8578 (по сравнению с линейной, степенной, экспоненциальной, гиперболической, обратной регрессиями). 4. С помощью среднего (общего) коэффициента эластичности дайте сравнительную оценку силы связи фактора с результатом. Рассчитаем коэффициент эластичности для линейной модели: · Для уравнения прямой:y = 5,777+7,122∙x
· Для уравнениястепенноймодели
· Для уравненияэкспоненциальноймодели
Для уравненияполулогарифмическоймодели
· Для уравнения обратной гиперболической модели
· Для уравнения равносторонней гиперболической модели
Сравнивая значения · · · · · · Известно, что коэффициент эластичности показывает связь между фактором и результатом, т.е. на сколько% изменится результат y от своей средней величины при изменении фактора х на 1% от своего среднего значения. В данном примере получилось, что самая большая сила связи между фактором и результатом в полулогарифмической модели, слабая сила связи в обратной гиперболической модели. 5. Оценка качества уравнений с помощью средней ошибки аппроксимации. Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчетные) значения
В среднем расчетные значения отклоняются от фактических на: · Линейная регрессия. Качество построенной модели оценивается как хорошее, так как · Степенная регрессия. Качество построенной модели оценивается как хорошее, так как · Экспоненциальная регрессия. Качество построенной модели оценивается как хорошее, так как · Полулогарифмическая регрессия. Качество построенной модели оценивается как хорошее, так как · Гиперболическая регрессия. Качество построенной модели оценивается как хорошее, так как · Обратная регрессия. Качество построенной модели оценивается как хорошее, так как 6. Рассчитаем F-критерий:
· Линейная регрессия. |



 .
.








 при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана). .
. для числа степеней свободы
для числа степеней свободы — случайная ошибка коэффициента корреляции.
— случайная ошибка коэффициента корреляции.



 параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.





 (2.11)
(2.11) . (2.12)
. (2.12) .
.










 ,
,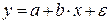 .
.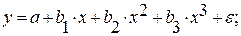
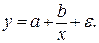
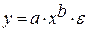 ;
;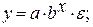
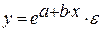
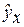 минимальна, т.е.
минимальна, т.е.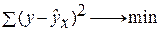
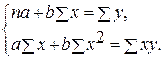
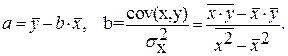
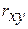 для линейной регрессии
для линейной регрессии 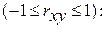
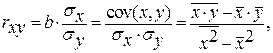
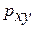 — для нелинейной регрессии (
— для нелинейной регрессии (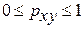 ):
):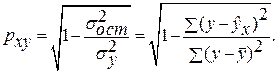
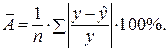
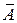 – не более 8 – 10%.
– не более 8 – 10%.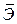 показывает, на сколько процентов в среднем по совокупности изменится результат у от своей средней величины при изменении фактора x на 1% от своего среднего значения:
показывает, на сколько процентов в среднем по совокупности изменится результат у от своей средней величины при изменении фактора x на 1% от своего среднего значения: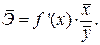
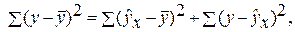
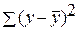 – общая сумма квадратов отклонений;
– общая сумма квадратов отклонений;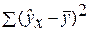 – сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
– сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);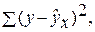 –остаточная сумма квадратов отклонений.
–остаточная сумма квадратов отклонений.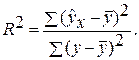
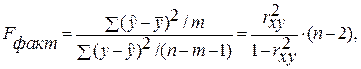
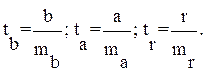
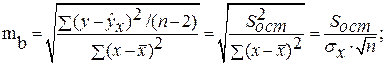
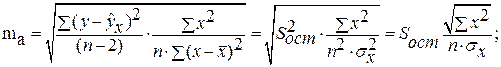
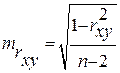
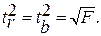
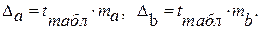

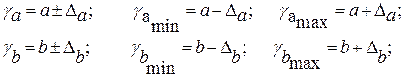
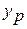 определяется путем подстановки в уравнение регрессии
определяется путем подстановки в уравнение регрессии 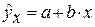 соответствующего (прогнозного) значения
соответствующего (прогнозного) значения 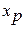 . Вычисляется средняя стандартная ошибка прогноза
. Вычисляется средняя стандартная ошибка прогноза 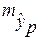 :
: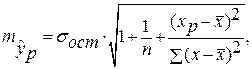 где
где 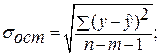
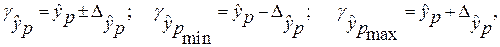 где
где 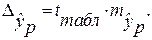
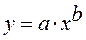 :
:
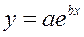 :
:
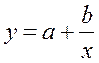 :
:
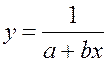 :
:
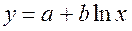 :
: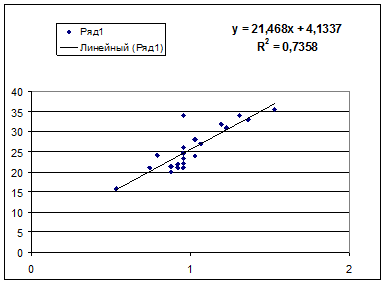
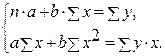
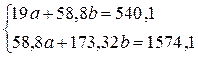
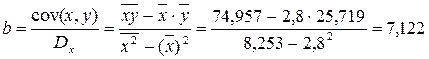
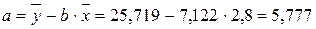
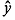 Ур-ие регрессии: = 5,777+7,122∙x. Данное уравнение показывает, что с увеличением среднедушевого денежного дохода в месяц на 1 тыс. руб. доля розничных продаж телевизоров повышается в среднем на 7,12%.
Ур-ие регрессии: = 5,777+7,122∙x. Данное уравнение показывает, что с увеличением среднедушевого денежного дохода в месяц на 1 тыс. руб. доля розничных продаж телевизоров повышается в среднем на 7,12%.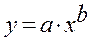 предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения:
предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения: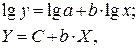 где
где 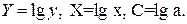
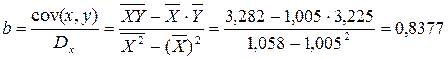
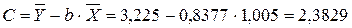
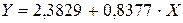 . Выполнив его потенцирование, получим:
. Выполнив его потенцирование, получим: 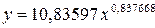
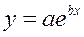 предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения:
предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения: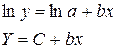 где
где 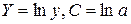
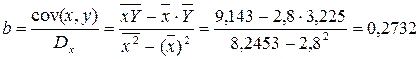
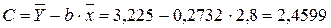
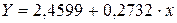 . Выполнив его потенцирование, получим:
. Выполнив его потенцирование, получим: 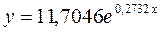
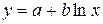 где
где 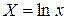
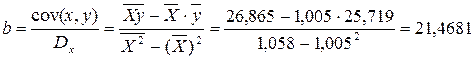
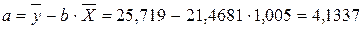
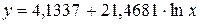 .
.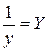 , тогда
, тогда 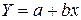
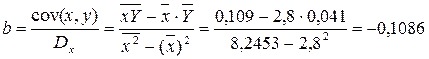
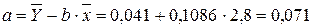
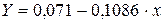 . Выполнив его потенцирование, получим:
. Выполнив его потенцирование, получим: 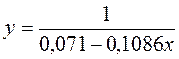
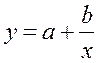 к линейному виду, заменив
к линейному виду, заменив 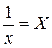 , тогда
, тогда 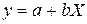
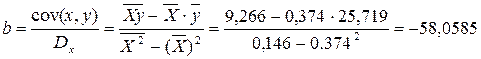
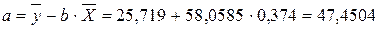
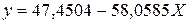 . Получим уравнение регрессии:
. Получим уравнение регрессии: 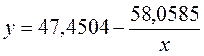 .
.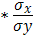 =7,122*
=7,122*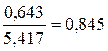 , что говорит о прямой сильной связи фактора и результата. Коэффициент детерминации r²xy =(0,845)²=0,715. Это означает, что 71,5% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
, что говорит о прямой сильной связи фактора и результата. Коэффициент детерминации r²xy =(0,845)²=0,715. Это означает, что 71,5% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.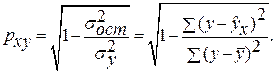 =
=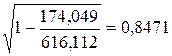 , что говорит о очень сильной тесной связи, но немного больше чем в линейной модели. Коэффициент детерминации r²xy =0,7175. Это означает, что 71,75% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
, что говорит о очень сильной тесной связи, но немного больше чем в линейной модели. Коэффициент детерминации r²xy =0,7175. Это означает, что 71,75% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.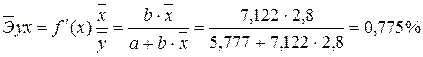
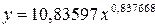 :
: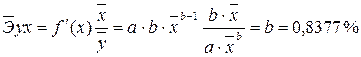
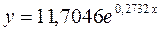 :
: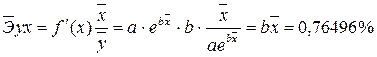
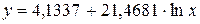 :
:
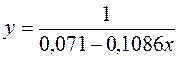 :
: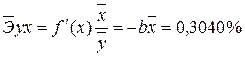
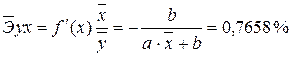
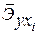 , характеризуем оценку силы связи фактора с результатом:
, характеризуем оценку силы связи фактора с результатом: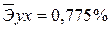
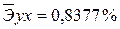
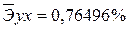
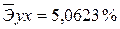
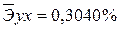
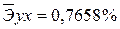
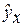 . Найдем величину средней ошибки аппроксимации
. Найдем величину средней ошибки аппроксимации 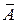 :
: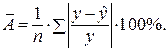
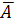 =
=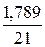 *100%= 8,5%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 8,5%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.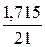 *100%= 8,2%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 8,2%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.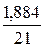 *100%= 9%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 9%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.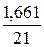 *100%= 7,9 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 7,9 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.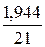 *100%= 9,3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 9,3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.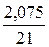 *100%= 9,9 3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 9,9 3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.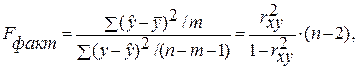
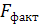 =
= 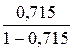 *19= 47,579
*19= 47,579