Пример 1 . По данной корреляционной таблице построить прямые регрессии с X на Y и с Y на X . Найти соответствующие коэффициенты регрессии и коэффициент корреляции между X и Y .
| y/x | 15 | 20 | 25 | 30 | 35 | 40 |
| 100 | 2 | 2 | ||||
| 120 | 4 | 3 | 10 | 3 | ||
| 140 | 2 | 50 | 7 | 10 | ||
| 160 | 1 | 4 | 3 | |||
| 180 | 1 | 1 |
Решение:
Уравнение линейной регрессии с y на x будем искать по формуле
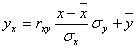
а уравнение регрессии с x на y, использовав формулу:
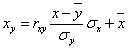
где x x , y — выборочные средние величин x и y, σx, σy — выборочные среднеквадратические отклонения.
Находим выборочные средние:
x = (15(1 + 1) + 20(2 + 4 + 1) + 25(4 + 50) + 30(3 + 7 + 3) + 35(2 + 10 + 10) + 40(2 + 3))/103 = 27.961
y = (100(2 + 2) + 120(4 + 3 + 10 + 3) + 140(2 + 50 + 7 + 10) + 160(1 + 4 + 3) + 180(1 + 1))/103 = 136.893
Выборочные дисперсии:
σ 2 x = (15 2 (1 + 1) + 20 2 (2 + 4 + 1) + 25 2 (4 + 50) + 30 2 (3 + 7 + 3) + 35 2 (2 + 10 + 10) + 40 2 (2 + 3))/103 — 27.961 2 = 30.31
σ 2 y = (100 2 (2 + 2) + 120 2 (4 + 3 + 10 + 3) + 140 2 (2 + 50 + 7 + 10) + 160 2 (1 + 4 + 3) + 180 2 (1 + 1))/103 — 136.893 2 = 192.29
Откуда получаем среднеквадратические отклонения:
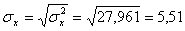 и
и 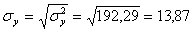
Определим коэффициент корреляции:
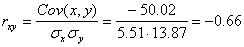
где ковариация равна:
Cov(x,y) = (35•100•2 + 40•100•2 + 25•120•4 + 30•120•3 + 35•120•10 + 40•120•3 + 20•140•2 + 25•140•50 + 30•140•7 + 35•140•10 + 15•160•1 + 20•160•4 + 30•160•3 + 15•180•1 + 20•180•1)/103 — 27.961 • 136.893 = -50.02
Запишем уравнение линий регрессии y(x):
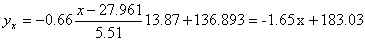
и уравнение x(y):
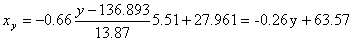
Построим найденные уравнения регрессии на чертеже, из которого сделаем следующие вывод:
1) обе линии проходят через точку с координатами (27.961; 136.893)
2) все точки расположены близко к линиям регрессии.

Пример 2 . По данным корреляционной таблицы найти условные средние y и x . Оценить тесноту линейной связи между признаками x и y и составить уравнения линейной регрессии y по x и x по y . Сделать чертеж, нанеся его на него условные средние и найденные прямые регрессии. Оценить силу связи между признаками с помощью корреляционного отношения.
Корреляционная таблица:
| X / Y | 2 | 4 | 6 | 8 | 10 |
| 1 | 5 | 4 | 2 | 0 | 0 |
| 2 | 0 | 6 | 3 | 3 | 0 |
| 3 | 0 | 0 | 1 | 2 | 3 |
| 5 | 0 | 0 | 0 | 0 | 1 |
Уравнение линейной регрессии с y на x имеет вид:
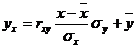
Уравнение линейной регрессии с x на y имеет вид:
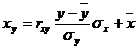
найдем необходимые числовые характеристики.
Выборочные средние:
x = (2(5) + 4(4 + 6) + 6(2 + 3 + 1) + 8(3 + 2) + 10(3 + 1) + )/30 = 5.53
y = (2(5) + 4(4 + 6) + 6(2 + 3 + 1) + 8(3 + 2) + 10(3 + 1) + )/30 = 1.93
Дисперсии:
σ 2 x = (2 2 (5) + 4 2 (4 + 6) + 6 2 (2 + 3 + 1) + 8 2 (3 + 2) + 10 2 (3 + 1))/30 — 5.53 2 = 6.58
σ 2 y = (1 2 (5 + 4 + 2) + 2 2 (6 + 3 + 3) + 3 2 (1 + 2 + 3) + 5 2 (1))/30 — 1.93 2 = 0.86
Откуда получаем среднеквадратические отклонения:
σx = 2.57 и σy = 0.93
и ковариация:
Cov(x,y) = (2•1•5 + 4•1•4 + 6•1•2 + 4•2•6 + 6•2•3 + 8•2•3 + 6•3•1 + 8•3•2 + 10•3•3 + 10•5•1)/30 — 5.53 • 1.93 = 1.84
Определим коэффициент корреляции:
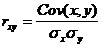
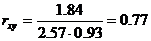
Запишем уравнения линий регрессии y(x):
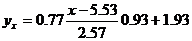
и вычисляя, получаем:
yx = 0.28 x + 0.39
Запишем уравнения линий регрессии x(y):
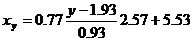
и вычисляя, получаем:
xy = 2.13 y + 1.42
Если построить точки, определяемые таблицей и линии регрессии, увидим, что обе линии проходят через точку с координатами (5.53; 1.93) и точки расположены близко к линиям регрессии.
Значимость коэффициента корреляции.
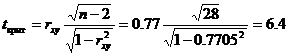
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=30-m-1 = 28 находим tкрит:
tкрит (n-m-1;α/2) = (28;0.025) = 2.048
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
Пример 3 . Распределение 50 предприятий пищевой промышленности по степени автоматизации производства Х (%) и росту производительности труда Y (%) представлено в таблице. Необходимо:
1. Вычислить групповые средние i и j x y, построить эмпирические линии регрессии.
2. Предполагая, что между переменными Х и Y существует линейная корреляционная зависимость:
а) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
б) вычислить коэффициент корреляции; на уровне значимости α= 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными Х и Y;
в) используя соответствующее уравнение регрессии, оценить рост производительности труда при степени автоматизации производства 43%.
Скачать решение
Пример . По корреляционной таблице рассчитать ковариацию и коэффициент корреляции, построить прямые регрессии.
Пример 4 . Найти выборочное уравнение прямой Y регрессии Y на X по данной корреляционной таблице.
Решение находим с помощью калькулятора.
Скачать
Пример №4
Пример 5 . С целью анализа взаимного влияния прибыли предприятия и его издержек выборочно были проведены наблюдения за этими показателями в течение ряда месяцев: X — величина месячной прибыли в тыс. руб., Y — месячные издержки в процентах к объему продаж.
Результаты выборки сгруппированы и представлены в виде корреляционной таблицы, где указаны значения признаков X и Y и количество месяцев, за которые наблюдались соответствующие пары значений названных признаков.
Решение.
Пример №5
Пример №6
Пример №7
Пример 6 . Данные наблюдений над двумерной случайной величиной (X, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X. Построить график уравнения регрессии и показать точки (x;y)б рассчитанные по таблице данных.
Решение.
Скачать решение
Пример 7 . Дана корреляционная таблица для величин X и Y, X- срок службы колеса вагона в годах, а Y — усредненное значение износа по толщине обода колеса в миллиметрах. Определить коэффициент корреляции и уравнения регрессий.
| X / Y | 0 | 2 | 7 | 12 | 17 | 22 | 27 | 32 | 37 | 42 |
| 0 | 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 25 | 108 | 44 | 8 | 2 | 0 | 0 | 0 | 0 | 0 |
| 2 | 30 | 50 | 60 | 21 | 5 | 5 | 0 | 0 | 0 | 0 |
| 3 | 1 | 11 | 33 | 32 | 13 | 2 | 3 | 1 | 0 | 0 |
| 4 | 0 | 5 | 5 | 13 | 13 | 7 | 2 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 2 | 12 | 6 | 3 | 2 | 1 | 0 |
| 6 | 0 | 1 | 0 | 1 | 0 | 0 | 2 | 1 | 0 | 1 |
| 7 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
Решение.
Скачать решение
Пример 8 . По заданной корреляционной таблице определить групповые средние количественных признаков X и Y. Построить эмпирические и теоретические линии регрессии. Предполагая, что между переменными X и Y существует линейная зависимость:
- Вычислить выборочный коэффициент корреляции и проанализировать степень тесноты и направления связи между переменными.
- Определить линии регрессии и построить их графики.
Скачать
- Решения задач: линейная регрессия и коэффициент корреляции
- Примеры решений онлайн: линейная регрессия
- Простая выборка
- Корреляционная таблица
- Коэффициент корреляции
- Основы линейной регрессии
- Что такое регрессия?
- Линия регрессии
- Метод наименьших квадратов
- Предположения линейной регрессии
- Аномальные значения (выбросы) и точки влияния
- Гипотеза линейной регрессии
- Оценка качества линейной регрессии: коэффициент детерминации R 2
- Применение линии регрессии для прогноза
- Простые регрессионные планы
- Пример: простой регрессионный анализ
- Задача исследования
- Просмотр результатов
- Коэффициенты регрессии
- Распределение переменных
- Диаграмма рассеяния
- Критерии значимости
Решения задач: линейная регрессия и коэффициент корреляции
Парная линейная регрессия — это зависимость между одной переменной и средним значением другой переменной. Чаще всего модель записывается как $y=ax+b+e$, где $x$ — факторная переменная, $y$ — результативная (зависимая), $e$ — случайная компонента (остаток, отклонение).
В учебных задачах по математической статистике обычно используется следующий алгоритм для нахождения уравнения регрессии.
- Выбор модели (уравнения). Часто модель задана заранее (найти линейную регрессию) или для подбора используют графический метод: строят диаграмму рассеяния и анализируют ее форму.
- Вычисление коэффициентов (параметров) уравнения регрессии. Часто для этого используют метод наименьших квадратов.
- Проверка значимости коэффициента корреляции и параметров модели (также для них можно построить доверительные интервалы), оценка качества модели по критерию Фишера.
- Анализ остатков, вычисление стандартной ошибки регрессии, прогноз по модели (опционально).
Ниже вы найдете решения для парной регрессии (по рядам данных или корреляционной таблице, с разными дополнительными заданиями) и пару задач на определение и исследование коэффициента корреляции.
Примеры решений онлайн: линейная регрессия
Простая выборка
Пример 1. Имеются данные средней выработки на одного рабочего Y (тыс. руб.) и товарооборота X (тыс. руб.) в 20 магазинах за квартал. На основе указанных данных требуется:
1) определить зависимость (коэффициент корреляции) средней выработки на одного рабочего от товарооборота,
2) составить уравнение прямой регрессии этой зависимости.
Пример 2. С целью анализа взаимного влияния зарплаты и текучести рабочей силы на пяти однотипных фирмах с одинаковым числом работников проведены измерения уровня месячной зарплаты Х и числа уволившихся за год рабочих Y:
X 100 150 200 250 300
Y 60 35 20 20 15
Найти линейную регрессию Y на X, выборочный коэффициент корреляции.
Пример 3. Найти выборочные числовые характеристики и выборочное уравнение линейной регрессии $y_x=ax+b$. Построить прямую регрессии и изобразить на плоскости точки $(x,y)$ из таблицы. Вычислить остаточную дисперсию. Проверить адекватность линейной регрессионной модели по коэффициенту детерминации.
Пример 4. Вычислить коэффициенты уравнения регрессии. Определить выборочный коэффициент корреляции между плотностью древесины маньчжурского ясеня и его прочностью.
Решая задачу необходимо построить поле корреляции, по виду поля определить вид зависимости, написать общий вид уравнения регрессии Y на Х, определить коэффициенты уравнения регрессии и вычислить коэффициенты корреляции между двумя заданными величинами.
Пример 5. Компанию по прокату автомобилей интересует зависимость между пробегом автомобилей X и стоимостью ежемесячного технического обслуживания Y. Для выяснения характера этой связи было отобрано 15 автомобилей. Постройте график исходных данных и определите по нему характер зависимости. Рассчитайте выборочный коэффициент линейной корреляции Пирсона, проверьте его значимость при 0,05. Постройте уравнение регрессии и дайте интерпретацию полученных результатов.
Корреляционная таблица
Пример 6. Найти выборочное уравнение прямой регрессии Y на X по заданной корреляционной таблице
Пример 7. В таблице 2 приведены данные зависимости потребления Y (усл. ед.) от дохода X (усл. ед.) для некоторых домашних хозяйств.
1. В предположении, что между X и Y существует линейная зависимость, найдите точечные оценки коэффициентов линейной регрессии.
2. Найдите стандартное отклонение $s$ и коэффициент детерминации $R^2$.
3. В предположении нормальности случайной составляющей регрессионной модели проверьте гипотезу об отсутствии линейной зависимости между Y и X.
4. Каково ожидаемое потребление домашнего хозяйства с доходом $x_n=7$ усл. ед.? Найдите доверительный интервал для прогноза.
Дайте интерпретацию полученных результатов. Уровень значимости во всех случаях считать равным 0,05.
Пример 8. Распределение 100 новых видов тарифов на сотовую связь всех известных мобильных систем X (ден. ед.) и выручка от них Y (ден.ед.) приводится в таблице:
Необходимо:
1) Вычислить групповые средние и построить эмпирические линии регрессии;
2) Предполагая, что между переменными X и Y существует линейная корреляционная зависимость:
А) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
Б) вычислить коэффициент корреляции, на уровне значимости 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными X и Y;
В) используя соответствующее уравнение регрессии, оценить среднюю выручку от мобильных систем с 20 новыми видами тарифов.
Коэффициент корреляции
Пример 9. На основании 18 наблюдений установлено, что на 64% вес X кондитерских изделий зависит от их объема Y. Можно ли на уровне значимости 0,05 утверждать, что между X и Y существует зависимость?
Пример 10. Исследование 27 семей по среднедушевому доходу (Х) и сбережениям (Y) дало результаты: $overline=82$ у.е., $S_x=31$ у.е., $overline=39$ у.е., $S_y=29$ у.е., $overline =3709$ (у.е.)2. При $alpha=0,05$ проверить наличие линейной связи между Х и Y. Определить размер сбережений семей, имеющих среднедушевой доход $Х=130$ у.е.
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.