Итак, очередная статья из цикла «математика на пальцах». Сегодня мы продолжим разговор о методах наименьших квадратов, но на сей раз с точки зрения программиста. Это очередная статья в серии, но она стоит особняком, так как вообще не требует никаких знаний математики. Статья задумывалась как введение в теорию, поэтому из базовых навыков она требует умения включить компьютер и написать пять строк кода. Разумеется, на этой статье я не остановлюсь, и в ближайшее же время опубликую продолжение. Если сумею найти достаточно времени, то напишу книгу из этого материала. Целевая публика — программисты, так что хабр подходящее место для обкатки. Я в целом не люблю писать формулы, и я очень люблю учиться на примерах, мне кажется, что это очень важно — не просто смотреть на закорючки на школьной доске, но всё пробовать на зуб.
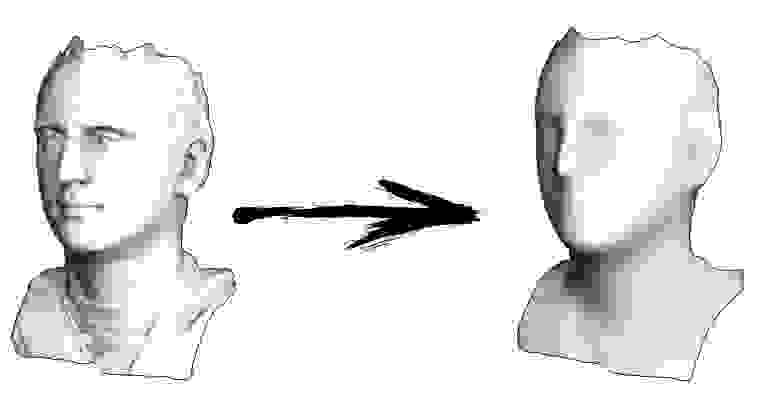
Итак, начнём. Давайте представим, что у меня есть триангулированная поверхность со сканом моего лица (на картинке слева). Что мне нужно сделать, чтобы усилить характерные черты, превратив эту поверхность в гротескную маску?

В данном конкретном случае я решаю эллиптическое дифференциальное уравнение, носящее имя Симеона Деми Пуассона. Товарищи программисты, давайте сыграем в игру: прикиньте, сколько строк в C++ коде, его решающем? Сторонние библиотеки вызывать нельзя, у нас в распоряжении только голый компилятор. Ответ под катом.
На самом деле, двадцати строк кода достаточно для солвера. Если считать со всем-всем, включая парсер файла 3Д модели, то в двести строк уложиться — раз плюнуть.
- Пример 1: сглаживание данных
- Пример 2: усиление/ослабление характеристических черт
- Пример 3: добавляем ограничения
- Лирическое отступление: численное решение систем линейных уравнений.
- Пример 3 ещё раз, но уже с другой стороны
- Пример 4: уравнение Пуассона
- Заключение
- Метод наименьших квадратов
- В чем именно заключается МНК (метод наименьших квадратов)
- Как вывести формулы для вычисления коэффициентов
- Как изобразить МНК на графике функций
- Доказательство метода МНК
- VMath
- Инструменты сайта
- Основное
- Навигация
- Информация
- Действия
- Содержание
- Метод наименьших квадратов
- Влияние систематических ошибок
- Псевдорешение системы линейных уравнений
- Геометрическая интерпретация
- Псевдообратная матрица
- Источники
Пример 1: сглаживание данных
Давайте расскажу, как это работает. Начнём издалека, представьте, что у нас есть обычный массив f, например, из 32 элементов, инициализированный следующим образом:
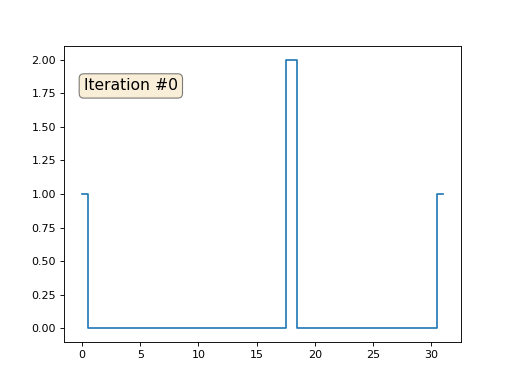
А затем мы тысячу раз выполним следующую процедуру: для каждой ячейки f[i] мы запишем в неё среднее значение соседних ячеек: f[i] = ( f[i-1] + f[i+1] )/2. Чтобы было понятнее, вот полный код:
Каждая итерация будет сглаживать данные нашего массива, и через тысячу итераций мы получим постоянное значение во всех ячейках. Вот анимация первых ста пятидесяти итераций:

Если вам неясно, почему происходит сглаживание, прямо сейчас остановитесь, возьмите ручку и попробуйте порисовать примеры, иначе дальше читать не имеет смысла. Триангулированная поверхность ничем принципиально от этого примера не отличается. Представьте, что для каждой вершины мы найдём соседние с ней, посчитаем их центр масс, и передвинем нашу вершину в этот центр масс, и так десять раз. Результат будет вот таким:
Разумеется, если не остановиться на десяти итерациях, то через некоторое время вся поверхность сожмётся в одну точку ровно так же, как и в предыдущем примере весь массив стал заполнен одним и тем же значением.
Пример 2: усиление/ослабление характеристических черт
Полный код доступен на гитхабе, а здесь я приведу самую важную часть, опустив лишь чтение и запись 3Д моделей. Итак, триангулированная модель у меня представлена двумя массивами: verts и faces. Массив verts — это просто набор трёхмерных точек, они же вершины полигональной сетки. Массив faces — это набор треугольников (количество треугольников равно faces.size()), для каждого треугольника в массиве хранятся индексы из массива вершин. Формат данных и работу с ним я подробно описывал в своём курсе лекций по компьютерной графике. Есть ещё третий массив, который я пересчитываю из первых двух (точнее, только из массива faces) — vvadj. Это массив, который для каждой вершины (первый индекс двумерного массива) хранит индексы соседних с ней вершин (второй индекс).
Первое, что я делаю, это для каждой вершины моей поверхности считаю вектор кривизны. Давайте проиллюстрируем: для текущей вершины v я перебираю всех её соседей n1-n4; затем я считаю их центр масс b = (n1+n2+n3+n4)/4. Ну и финальный вектор кривизны может быть посчитан как c=v-b, это не что иное, как обычные конечные разности для второй производной.
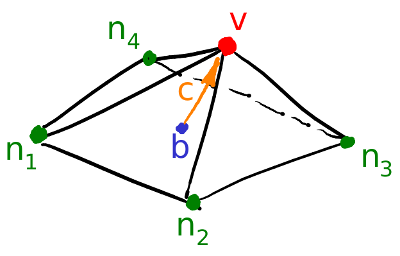
Непосредственно в коде это выглядит следующим образом:
Ну а дальше мы много раз делаем следующую вещь (смотрите предыдущую картинку): мы вершину v двигаем v := b + const * c. Обратите внимание, что если константа равна единице, то наша вершина никуда не сдвинется! Если константа равна нулю, то вершина заменяется на центр масс соседних вершин, что будет сглаживать нашу поверхность. Если константа больше единицы (заглавная картинка сделана при помощи const=2.1), то вершина будет сдвигаться в направлении вектора кривизны поверхности, усиливая детали. Вот так это выглядит в коде:
Кстати, если меньше единицы, то детали будут наоборот ослабляться (const=0.5), но это не будет эквивалентно простому сглаживанию, «контраст картинки» останется:
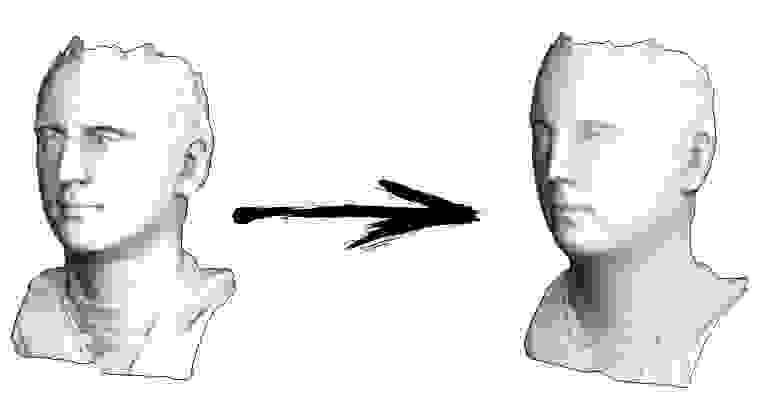
Обратите внимание, что мой код генерирует файл 3Д модели в формате Wavefront .obj, рендерил я в сторонней программе. Посмотреть получившуюся модель можно, например, в онлайн-вьюере. Если вам интересны именно методы отрисовки, а не генерирование модели, то читайте мой курс лекций по компьютерной графике.
Пример 3: добавляем ограничения
Давайте вернёмся к самому первому примеру, и сделаем ровно то же самое, но только не будем переписывать элементы массива под номерами 0, 18 и 31:
Остальные, «свободные» элементы массива я инициализировал нулями, и по-прежнему итеративно заменяю их на среднее значение соседних элементов. Вот так выглядит эволюция массива на первых ста пятидесяти итерациях:

Вполне очевидно, что на сей раз решение сойдётся не к постоянному элементу, заполняющему массив, а к двум линейным рампам. Кстати, действительно ли всем очевидно? Если нет, то экспериментируйте с этим кодом, я специально привожу примеры с очень коротким кодом, чтобы можно было досконально разобраться с происходящим.
Лирическое отступление: численное решение систем линейных уравнений.
Пусть нам дана обычная система линейных уравнений:

Её можно переписать, оставив в каждом из уравнений с одной стороны знака равенства x_i:
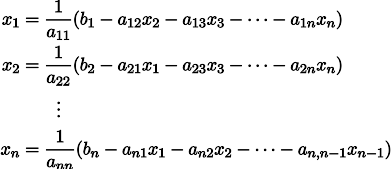
Пусть нам дан произвольный вектор 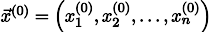 , приближающий решение системы уравнений (например, нулевой).
, приближающий решение системы уравнений (например, нулевой).
Тогда, воткнув его в правую часть нашей системы, мы можем получить обновлённый вектор приближения решения 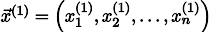 .
.
Чтобы было понятнее, x1 получается из x0 следующим образом:
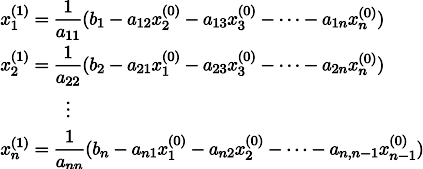
Повторив процесс k раз, решение будет приближено вектором 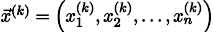
Давайте на всякий случай запишем рекурретную формулу:
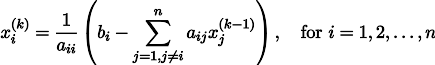
При некоторых предположениях о коэффициентах системы (например, вполне очевидно, что диагональные элементы не должны быть нулевыми, т.к. мы на них делим), данная процедура сходится к истинному решению. Эта гимнастика известна в литературе под названием метода Якоби. Конечно же, существуют и другие методы численного решения систем линейных уравнений, причём значительно более мощные, например, метод сопряжённых градиентов, но, пожалуй, метод Якоби является одним из самых простых.
Пример 3 ещё раз, но уже с другой стороны
А теперь давайте ещё раз внимательно посмотрим на основной цикл из примера 3:
Я стартовал с какого-то начального вектора x, и тысячу раз его обновляю, причём процедура обновления подозрительно похожа на метод Якоби! Давайте выпишем эту систему уравнений в явном виде:

Потратьте немного времени, убедитесь, что каждая итерация в моём питоновском коде — это строго одно обновление метода Якоби для этой системы уравнений. Значения x[0], x[18] и x[31] у меня зафиксированы, соответственно, в набор переменных они не входят, поэтому они перенесены в правую часть.
Итого, все уравнения в нашей системе выглядят как — x[i-1] + 2 x[i] — x[i+1] = 0. Это выражение не что иное, как обычные конечные разности для второй производной. То есть, наша система уравнений нам просто-напросто предписывает, что вторая производная должна быть везде равна нулю (ну, кроме как в точке x[18]). Помните, я говорил, что вполне очевидно, что итерации должны сойтись к линейным рампам? Так именно поэтому, у линейной функции вторая производная нулевая.
А вы знаете, что мы с вами только что решили задачу Дирихле для уравнения Лапласа?
Кстати, внимательный читатель должен был бы заметить, что, строго говоря, у меня в коде системы линейных уравнений решаются не методом Якоби, но методом Гаусса-Зейделя, который является своебразной оптимизацией метода Якоби:
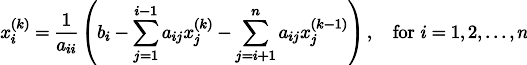
Пример 4: уравнение Пуассона
А давайте мы самую малость изменим третий пример: каждая ячейка помещается не просто в центр масс соседних ячеек, но в центр масс плюс некая (произвольная) константа:
В прошлом примере мы выяснили, что помещение в центр масс — это дискретизация оператора Лапласа (в нашем случае второй производной). То есть, теперь мы решаем систему уравнений, которая говорит, что наш сигнал должен иметь некую постоянную вторую производную. Вторая производная — это кривизна поверхности; таким образом, решением нашей системы должна стать кусочно-квадратичная функция. Проверим на дискретизации в 32 сэмпла:

При длине массива в 32 элемента наша система сходится к решению за пару сотен итераций. А что будет, если мы попробуем массив в 128 элементов? Тут всё гораздо печальнее, количество итераций нужно уже исчислять тысячами:

Метод Гаусса-Зейделя крайне прост в программировании, но малоприменим для больших систем уравнений. Можно попытаться его ускорить, применяя, например, многосеточные методы. На словах это может звучать громоздко, но идея крайне примитивная: если мы хотим решение с разрешением в тысячу элементов, то можно для начала решить с десятью элементами, получив грубую аппроксимацию, затем удвоить разрешение, решить ещё раз, и так далее, пока не достигнем нужного результата. На практике это выглядит следующим образом:

А можно не выпендриваться, и использовать настоящие солверы систем уравнений. Вот я решаю этот же пример, построив матрицу A и столбец b, затем решив матричное уравнение Ax=b:
А вот так выглядит результат работы этой программы, заметим, что решение получилось мгновенно:
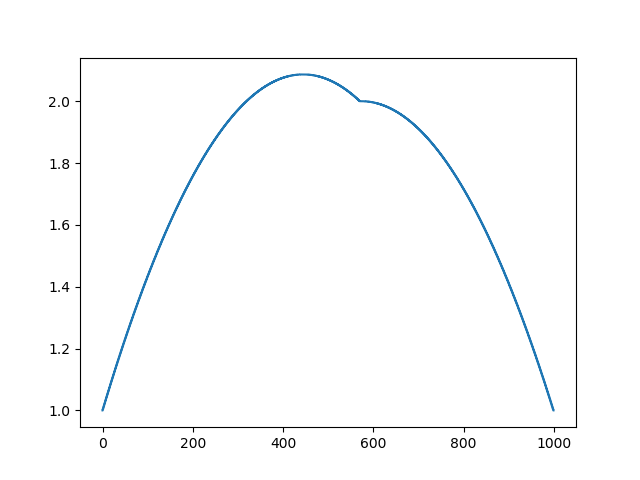
Таким образом, действительно, наша функция кусочно-квадратичная (вторая производная равна константе). В первом примере мы задали нулевую вторую производную, в третьем ненулевую, но везде одинаковую. А что было во втором примере? Мы решили дискретное уравнение Пуассона, задав кривизну поверхности. Напоминаю, что произошло: мы посчитали кривизну входящей поверхности. Если мы решим задачу Пуассона, задав кривизну поверхности на выходе равной кривизне поверхности на входе (const=1), то ничего не изменится. Усиление характеристических черт лица происходит, когда мы просто увеличиваем кривизну (const=2.1). А если const Скрытый текст
Это результат по умолчанию, рыжий Ленин — это начальные данные, голубая кривая — это их эволюция, в бесконечности результат сойдётся в точку:

А вот результат с коэффицентом 2.:

Домашнее задание: почему во втором случае Ленин сначала превращается в Дзержинского, а затем снова сходится к Ленину же, но большего размера?
Заключение
Очень много задач обработки данных, в частности, геометрии, могут формулироваться как решение системы линейных уравнений. В данной статье я не рассказал, как строить эти системы, моей целью было лишь показать, что это возможно. Темой следующей статьи будет уже не «почему», но «как», и какие солверы потом использовать.
Кстати, а ведь в названии статьи присутствуют наименьшие квадраты. Увидели ли вы их в тексте? Если нет, то это абсолютно не страшно, это именно ответ на вопрос «как?». Oставайтесь на линии, в следующей статье я покажу, где именно они прячутся, и как их модифицировать, чтобы получить доступ к крайне мощному инструменту обработки данных. Например, в десяток строк кода можно получить вот такое:
Метод наименьших квадратов
Начнем статью сразу с примера. У нас есть некие экспериментальные данные о значениях двух переменных – x и y . Занесем их в таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | |
| x i | 0 | 1 | 2 | 4 | 5 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 , 0 |
После выравнивания получим функцию следующего вида: g ( x ) = x + 1 3 + 1 .
Мы можем аппроксимировать эти данные с помощью линейной зависимости y = a x + b , вычислив соответствующие параметры. Для этого нам нужно будет применить так называемый метод наименьших квадратов. Также потребуется сделать чертеж, чтобы проверить, какая линия будет лучше выравнивать экспериментальные данные.
В чем именно заключается МНК (метод наименьших квадратов)
Главное, что нам нужно сделать, – это найти такие коэффициенты линейной зависимости, при которых значение функции двух переменных F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 будет наименьшим. Иначе говоря, при определенных значениях a и b сумма квадратов отклонений представленных данных от получившейся прямой будет иметь минимальное значение. В этом и состоит смысл метода наименьших квадратов. Все, что нам надо сделать для решения примера – это найти экстремум функции двух переменных.
Как вывести формулы для вычисления коэффициентов
Для того чтобы вывести формулы для вычисления коэффициентов, нужно составить и решить систему уравнений с двумя переменными. Для этого мы вычисляем частные производные выражения F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 по a и b и приравниваем их к 0 .
δ F ( a , b ) δ a = 0 δ F ( a , b ) δ b = 0 ⇔ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i = 0 — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) = 0 ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + ∑ i = 1 n b = ∑ i = 1 n y i ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + n b = ∑ i = 1 n y i
Для решения системы уравнений можно использовать любые методы, например, подстановку или метод Крамера. В результате у нас должны получиться формулы, с помощью которых вычисляются коэффициенты по методу наименьших квадратов.
n ∑ i = 1 n x i y i — ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n — ∑ i = 1 n x i 2 b = ∑ i = 1 n y i — a ∑ i = 1 n x i n
Мы вычислили значения переменных, при который функция
F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 примет минимальное значение. В третьем пункте мы докажем, почему оно является именно таким.
Это и есть применение метода наименьших квадратов на практике. Его формула, которая применяется для поиска параметра a , включает в себя ∑ i = 1 n x i , ∑ i = 1 n y i , ∑ i = 1 n x i y i , ∑ i = 1 n x i 2 , а также параметр
n – им обозначено количество экспериментальных данных. Советуем вам вычислять каждую сумму отдельно. Значение коэффициента b вычисляется сразу после a .
Обратимся вновь к исходному примеру.
Здесь у нас n равен пяти. Чтобы было удобнее вычислять нужные суммы, входящие в формулы коэффициентов, заполним таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | ∑ i = 1 5 | |
| x i | 0 | 1 | 2 | 4 | 5 | 12 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x i y i | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x i 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Решение
Четвертая строка включает в себя данные, полученные при умножении значений из второй строки на значения третьей для каждого отдельного i . Пятая строка содержит данные из второй, возведенные в квадрат. В последнем столбце приводятся суммы значений отдельных строчек.
Воспользуемся методом наименьших квадратов, чтобы вычислить нужные нам коэффициенты a и b . Для этого подставим нужные значения из последнего столбца и подсчитаем суммы:
n ∑ i = 1 n x i y i — ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n — ∑ i = 1 n x i 2 b = ∑ i = 1 n y i — a ∑ i = 1 n x i n ⇒ a = 5 · 33 , 8 — 12 · 12 , 9 5 · 46 — 12 2 b = 12 , 9 — a · 12 5 ⇒ a ≈ 0 , 165 b ≈ 2 , 184
У нас получилось, что нужная аппроксимирующая прямая будет выглядеть как y = 0 , 165 x + 2 , 184 . Теперь нам надо определить, какая линия будет лучше аппроксимировать данные – g ( x ) = x + 1 3 + 1 или 0 , 165 x + 2 , 184 . Произведем оценку с помощью метода наименьших квадратов.
Чтобы вычислить погрешность, нам надо найти суммы квадратов отклонений данных от прямых σ 1 = ∑ i = 1 n ( y i — ( a x i + b i ) ) 2 и σ 2 = ∑ i = 1 n ( y i — g ( x i ) ) 2 , минимальное значение будет соответствовать более подходящей линии.
σ 1 = ∑ i = 1 n ( y i — ( a x i + b i ) ) 2 = = ∑ i = 1 5 ( y i — ( 0 , 165 x i + 2 , 184 ) ) 2 ≈ 0 , 019 σ 2 = ∑ i = 1 n ( y i — g ( x i ) ) 2 = = ∑ i = 1 5 ( y i — ( x i + 1 3 + 1 ) ) 2 ≈ 0 , 096
Ответ: поскольку σ 1 σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0 , 165 x + 2 , 184 .
Как изобразить МНК на графике функций
Метод наименьших квадратов наглядно показан на графической иллюстрации. С помощью красной линии отмечена прямая g ( x ) = x + 1 3 + 1 , синей – y = 0 , 165 x + 2 , 184 . Исходные данные обозначены розовыми точками.
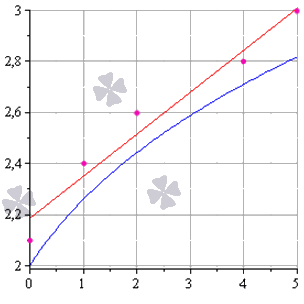
Поясним, для чего именно нужны приближения подобного вида.
Они могут быть использованы в задачах, требующих сглаживания данных, а также в тех, где данные надо интерполировать или экстраполировать. Например, в задаче, разобранной выше, можно было бы найти значение наблюдаемой величины y при x = 3 или при x = 6 . Таким примерам мы посвятили отдельную статью.
Доказательство метода МНК
Чтобы функция приняла минимальное значение при вычисленных a и b , нужно, чтобы в данной точке матрица квадратичной формы дифференциала функции вида F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 была положительно определенной. Покажем, как это должно выглядеть.
У нас есть дифференциал второго порядка следующего вида:
d 2 F ( a ; b ) = δ 2 F ( a ; b ) δ a 2 d 2 a + 2 δ 2 F ( a ; b ) δ a δ b d a d b + δ 2 F ( a ; b ) δ b 2 d 2 b
Решение
δ 2 F ( a ; b ) δ a 2 = δ δ F ( a ; b ) δ a δ a = = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i δ a = 2 ∑ i = 1 n ( x i ) 2 δ 2 F ( a ; b ) δ a δ b = δ δ F ( a ; b ) δ a δ b = = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i δ b = 2 ∑ i = 1 n x i δ 2 F ( a ; b ) δ b 2 = δ δ F ( a ; b ) δ b δ b = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) δ b = 2 ∑ i = 1 n ( 1 ) = 2 n
Иначе говоря, можно записать так: d 2 F ( a ; b ) = 2 ∑ i = 1 n ( x i ) 2 d 2 a + 2 · 2 ∑ x i i = 1 n d a d b + ( 2 n ) d 2 b .
Мы получили матрицу квадратичной формы вида M = 2 ∑ i = 1 n ( x i ) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n .
В этом случае значения отдельных элементов не будут меняться в зависимости от a и b . Является ли эта матрица положительно определенной? Чтобы ответить на этот вопрос, проверим, являются ли ее угловые миноры положительными.
Вычисляем угловой минор первого порядка: 2 ∑ i = 1 n ( x i ) 2 > 0 . Поскольку точки x i не совпадают, то неравенство является строгим. Будем иметь это в виду при дальнейших расчетах.
Вычисляем угловой минор второго порядка:
d e t ( M ) = 2 ∑ i = 1 n ( x i ) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n = 4 n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2
После этого переходим к доказательству неравенства n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 с помощью математической индукции.
- Проверим, будет ли данное неравенство справедливым при произвольном n . Возьмем 2 и подсчитаем:
2 ∑ i = 1 2 ( x i ) 2 — ∑ i = 1 2 x i 2 = 2 x 1 2 + x 2 2 — x 1 + x 2 2 = = x 1 2 — 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
У нас получилось верное равенство (если значения x 1 и x 2 не будут совпадать).
- Сделаем предположение, что данное неравенство будет верным для n , т.е. n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 – справедливо.
- Теперь докажем справедливость при n + 1 , т.е. что ( n + 1 ) ∑ i = 1 n + 1 ( x i ) 2 — ∑ i = 1 n + 1 x i 2 > 0 , если верно n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 .
( n + 1 ) ∑ i = 1 n + 1 ( x i ) 2 — ∑ i = 1 n + 1 x i 2 = = ( n + 1 ) ∑ i = 1 n ( x i ) 2 + x n + 1 2 — ∑ i = 1 n x i + x n + 1 2 = = n ∑ i = 1 n ( x i ) 2 + n · x n + 1 2 + ∑ i = 1 n ( x i ) 2 + x n + 1 2 — — ∑ i = 1 n x i 2 + 2 x n + 1 ∑ i = 1 n x i + x n + 1 2 = = ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + n · x n + 1 2 — x n + 1 ∑ i = 1 n x i + ∑ i = 1 n ( x i ) 2 = = ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + x n + 1 2 — 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 — 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 — 2 x n + 1 x 1 + x n 2 = = n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + + ( x n + 1 — x 1 ) 2 + ( x n + 1 — x 2 ) 2 + . . . + ( x n — 1 — x n ) 2 > 0
Выражение, заключенное в фигурные скобки, будет больше 0 (исходя из того, что мы предполагали в пункте 2 ), и остальные слагаемые будут больше 0 , поскольку все они являются квадратами чисел. Мы доказали неравенство.
Ответ: найденные a и b будут соответствовать наименьшему значению функции F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 , значит, они являются искомыми параметрами метода наименьших квадратов (МНК).
VMath
Инструменты сайта
Основное
Навигация
Информация
Действия
Содержание
Вспомогательная страница к разделу ☞ ИНТЕРПОЛЯЦИЯ.
Метод наименьших квадратов
Пусть из физических соображений можно считать (предполагать), что величины $ x_ $ и $ y_ $ связаны линейной зависимостью вида $ y=kx+b $, а неизвестные коэффициенты $ k_ $ и $ b_ $ должны быть оценены экспериментально. Экспериментальные данные представляют собой $ m>1 $ точек на координатной плоскости $ (x_1,y_1), dots, (x_m,y_m) $. Если бы эти опыты производились без погрешностей, то подстановка данных в уравнение приводила бы нас к системе из $ m_ $ линейных уравнений для двух неизвестных $ k_ $ и $ b_ $: $$ y_1=k,x_1+b, dots, y_m=k,x_m+b . $$ Из любой пары уравнений этой системы можно было бы однозначно определить коэффициенты $ k_ $ и $ b_ $.
Однако, в реальной жизни опытов без погрешностей не бывает
Дорогая редакция! Формулировку закона Ома следует уточнить следующим образом:«Если использовать тщательно отобранные и безупречно подготовленные исходные материалы, то при наличии некоторого навыка из них можно сконструировать электрическую цепь, для которой измерения отношения тока к напряжению, даже если они проводятся в течение ограниченного времени, дают значения, которые после введения соответствующих поправок оказываются равными постоянной величине».
Источник: А.М.Б.Розен. Физики шутят. М.Мир.1993.
Будем предполагать, что величины $ x_,dots,x_m $ известны точно, а им соответствующие $ y_1,dots,y_m $ — приближенно. Если $ m>2 $, то при любых различных $ x_ $ и $ x_j $ пара точек $ (x_,y_i) $ и $ (x_,y_j) $ определяет прямую. Но другая пара точек определяет другую прямую, и у нас нет оснований выбрать какую-нибудь одну из всех прямых.
Часто в задаче удаленность точки от прямой измеряют не расстоянием, а разностью ординат $ k,x_i+b-y_i $, и выбирают прямую так, чтобы сумма квадратов всех таких разностей была минимальна. Коэффициенты $ k_0 $ и $ b_ $ уравнения этой прямой дают некоторое решение стоящей перед нами задачи, которое отнюдь не является решением системы линейных уравнений $$ k,x_1+b=y_1,dots, k,x_+b=y_m $$ (вообще говоря, несовместной).
Рассмотрим теперь обобщение предложенной задачи. Пусть искомая зависимость между величинами $ y_ $ и $ x_ $ полиномиальная: $$ y_1=f(x_1),dots , y_m=f(x_m), quad npu quad f(x)=a_0+a_1x+dots+a_x^ $$ Величина $ varepsilon_i=f(x_i)-y_i $ называется $ i_ $-й невязкой 1) . Уравнения $$ left<begin a_0+a_1x_1+dots+a_x_1^&=&y_1, \ a_0+a_1x_2+dots+a_x_2^&=&y_2, \ dots & & dots \ a_0+a_1x_m+dots+a_x_m^&=&y_m end right. $$ называются условными. Матрица этой системы — матрица Вандермонда (она не обязательно квадратная).
Предположим что данные интерполяционной таблицы $$ begin x & x_1 & x_2 & dots & x_m \ hline y & y_1 & y_2 &dots & y_m end $$ не являются достоверными: величины $ x_ $ нам известны практически без искажений (т.е. на входе процесса мы имеем абсолютно достоверные данные), а вот измерения величины $ y_ $ подвержены случайным (несистематическим) погрешностям.
Задача. Построить полином $ f_(x) $ такой, чтобы величина $$ sum_^m [f(x_j)-y_j]^2 $$ стала минимальной. Решение задачи в такой постановке известно как метод наименьшик квадратов 2) .
В случае $ deg f_ =m-1 $ мы возвращаемся к задаче интерполяции в ее классической постановке. Практический интерес, однако, представляет случай $ deg f_ n $: $$S=left(begin 1 &1&1&ldots&1\ x_1 &x_2&x_3&ldots&x_\ vdots&& & &vdots\ x_1^ &x_2^&x_3^&ldots&x_m^ endright) cdot left(begin 1 &x_1&x_1^2&ldots&x_1^\ 1 &x_2&x_2^2&ldots&x_2^\ ldots&& & &ldots\ 1 &x_m&x_m^2&ldots&x_m^ endright)$$ $$det S = sum_<1le j_1 0 $. По теореме Крамера система нормальных уравнений имеет единственное решение.
Осталось недоказанным утверждение, что полученное решение доставляет именно минимум сумме квадратов невязок. Этот факт следует из доказательства более общего утверждения — о псевдорешении системы линейных уравнений. Этот результат приводится ☟ НИЖЕ. ♦
Собственно минимальное значение величины cуммы квадратов невязок, а точнее усреднение по количеству узлов $$ sigma=fracsum_^m (f(x_j) -y_j)^2 $$ называется среднеквадратичным отклонением.

Показать, что линейный полином $ y=a_+a_1x $, построенный по методу наименьших квадратов, определяет на плоскости $ (x_,y) $ прямую, проходящую через центроид
Пример. По методу наименьших квадратов построить уравнение прямой, аппроксимирующей множество точек плоскости, заданных координатами из таблицы
$$ begin x & 0.5 & 1 & 1.5 & 2 & 2.5 & 3 \ hline y & 0.35 & 0.80 & 1.70 & 1.85 & 3.51 & 1.02 end $$
Решение. Имеем $$ s_0=6, s_1=0.5 + 1 + 1.5 + 2 + 2.5 + 3=10.5, $$ $$ s_2=0.5^2 + 1^2 + 1.5^2 + 2^2 + 2.5^2 + 3^2=22.75, $$ $$t_0=0.35 + 0.80 + 1.70 + 1.85 + 3.51 + 1.02=9.23, $$ $$ t_1 =0.5cdot 0.35 + 1 cdot 0.80 + 1.5 cdot 1.70 + 2 cdot 1.85 + $$ $$ +2.5 cdot 3.51 + 3 cdot 1.02=19.06 . $$ Решаем систему нормальных уравнений $$ left( begin 6 & 10.5 \ 10.5 & 22.75 end right) left( begin a_0 \ a_1 end right)= left( begin 9.23 \ 19.06 end right), $$ 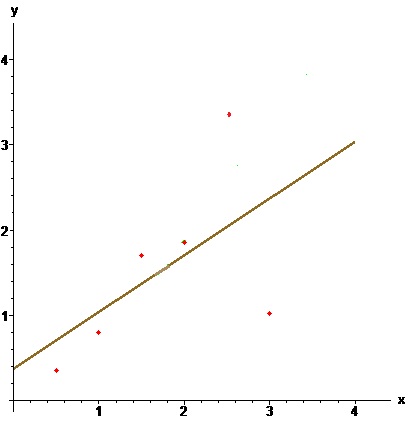 получаем уравнение прямой в виде $$ y= 0.375 + 0.665, x .$$
получаем уравнение прямой в виде $$ y= 0.375 + 0.665, x .$$
Вычислим и полиномы более высоких степеней. $$ f_2(x)=-1.568+3.579, x-0.833,x^2 , $$ $$ f_3(x)=2.217-5.942,x+5.475,x^2-1.201, x^3 , $$ $$ f_4(x)= -4.473+17.101,x-19.320,x^2+9.205, x^3-1.487,x^4 , $$ $$ f_5(x)= 16.390-71.235,x+111.233,x^2-77.620,x^3+25.067,x^4-3.0347, x^5 . $$
Среднеквадратичные отклонения: $$ begin deg & 1 & 2 & 3 & 4 & 5 \ hline sigma & 0.717 & 0.448 & 0.204 &0.086 & 0 end $$ ♦
Возникает естественный вопрос: полином какой степени следует разыскивать в МНК? При увеличении степени точность приближения, очевидно, увеличивается. Вместе с тем, увеличивается сложность решения системы нормальных уравнений и даже при небольших степенях $ n $ (меньших $ 10 $) мы столкнемся с проблемой чувствительности решения к точности представления входных данных.
Влияние систематических ошибок
Пример. Уравнение прямой, аппроксимирующей множество точек плоскости, заданных координатами из таблицы
$$ begin x & 0.5 & 1 & 1.5 & 2 & 2.5 & 3 \ hline y & 0.35 & 0.80 & 1.70 & 1.85 & 2.51 & 2.02 end $$ имеет вид (охра) $$ y=0.175+0.779, x , . $$  Теперь заменим значение $ y_5 $ на $ 0.2 $. Уравнение прямой принимает вид: $$ y=0.483+0.383, x , . $$ График (зеленый) существенно изменился. Почему это произошло? — Дело в том, что эффективность метода наименьших квадратов зависит от нескольких предположений относительно входных данных: в нашем случае — значений $ y $. Предполагается, что эти величины являлись результатами экспериментов, измерений, и, если они подвержены погрешностям, то эти погрешности носят характер несистематических флуктуаций вокруг истинных значений. Иными словами, изначально предполагается, что в действительности точки плоскости должны лежать на некоторой прямой. И только несовершенство наших методов измерений (наблюдений) демонстрирует смещение их с этой прямой. Ответ для исходной таблицы визуально подтвержает это предположение: экспериментальные точки концентрируются вокруг полученной прямой и величины невязок (отклонений по $ y $-координате) имеют «паритет» по знакам: примерно половина точек лежит выше прямой, а половина — ниже.
Теперь заменим значение $ y_5 $ на $ 0.2 $. Уравнение прямой принимает вид: $$ y=0.483+0.383, x , . $$ График (зеленый) существенно изменился. Почему это произошло? — Дело в том, что эффективность метода наименьших квадратов зависит от нескольких предположений относительно входных данных: в нашем случае — значений $ y $. Предполагается, что эти величины являлись результатами экспериментов, измерений, и, если они подвержены погрешностям, то эти погрешности носят характер несистематических флуктуаций вокруг истинных значений. Иными словами, изначально предполагается, что в действительности точки плоскости должны лежать на некоторой прямой. И только несовершенство наших методов измерений (наблюдений) демонстрирует смещение их с этой прямой. Ответ для исходной таблицы визуально подтвержает это предположение: экспериментальные точки концентрируются вокруг полученной прямой и величины невязок (отклонений по $ y $-координате) имеют «паритет» по знакам: примерно половина точек лежит выше прямой, а половина — ниже.
После замены значения $ y_5 $ на новое, значительно отличающееся от исходного, существенно меняется величина $ 5 $-й невязки $ varepsilon_5= ax_5+b-y_5 $. А поскольку в минимизируемую функцию эта невязка входи еще и в квадрате, то понятно, что изначальная прямая просто не в состоянии правильно приблизить новую точку.
Эта проблема становится актуальной в тех случаях, когда в «истинно случайный» процесс привносятся намеренные коррективы. Данные начинают подвергаться существенным искажениям, возможно, даже имеющим «злой» умысел 3) .
Как бороться с ошибками такого типа? Понятно, что решение возможно в предположении, что число таких — систематических — ошибок должно быть существенно меньшим общего количества экспериментальных данных. Понятно, что каким-то образом эти «выбросы» надо будет исключить из рассмотрения, т.е. очистить «сырые» данные от «мусора» — прежде чем подсовывать их в метод наименьших квадратов (см. ☞ цитату). Как это сделать?
Псевдорешение системы линейных уравнений
Рассмотрим теперь обобщение задачи предыдущего пункта. В практических задачах часто бывает нужно найти решение, удовлетворяющее большому числу возможно противоречивых требований. Если такая задача сводится к системе линейных уравнений $$ left<begin a_x_1 +a_x_2+ldots+a_x_n &=&b_1\ a_x_1 +a_x_2+ldots+a_x_n &=&b_2\ ldots& & ldots \ a_x_1 +a_x_2+ldots+a_x_n &=&b_m endright. iff AX= $$ при числе уравнений $ m_ $ большем числа неизвестных $ n_ $, то такая переопределенная система, как правило, несовместна. В этом случае задача может быть решена только путем выбора некоторого компромисса — все требования могут быть удовлетворены не полностью, а лишь до некоторой степени.
Псевдорешением системы $ AX= $ называется столбец $ Xin mathbb R^n $, обеспечивающий минимум величины $$ sum_^m [a_x_1 +a_x_2+ldots+a_x_n-b_i]^2 . $$
Теорема. Существует псевдорешение системы
$$ AX= $$ и оно является решением системы $$ left[A^A right]X=A^ . $$ Это решение будет единственным тогда и только тогда, когда $ operatorname A =n $.
Система $ left[A^A right]X=A^ $ называется нормальной системой по отношению к системе $ AX= $. Формально она получается домножением системы $ AX= $ слева на матрицу $ A^ $. Заметим также, что если $ m=n_ $ и $ det A ne 0 $, то псевдорешение системы совпадает с решением в традиционном смысле.
Доказательство ☞ ЗДЕСЬ.
Если нормальная система имеет бесконечное количество решений, то обычно в качестве псевдорешения берут какое-то одно из них — как правило то, у которого минимальна сумма квадратов компонент («длина»).
Пример. Найти псевдорешение системы
$$x_1+x_2 = 2, x_1-x_2 = 0, 2, x_1+x_2 = 2 .$$
Решение. Имеем: $$A=left( begin 1 & 1 \ 1 & -1 \ 2 & 1 end right), operatorname A =2, = left( begin 2 \ 0 \ 2 end right), A^A= left( begin 6 & 2 \ 2 & 3 end right), A^ = left( begin 6 \ 4 end right). $$
Ответ. $ x_1=5/7, x_2 = 6/7 $.
Показать, что матрица $ A^A $ всегда симметрична.
На дубовой колоде лежит мелкая монетка. К колоде
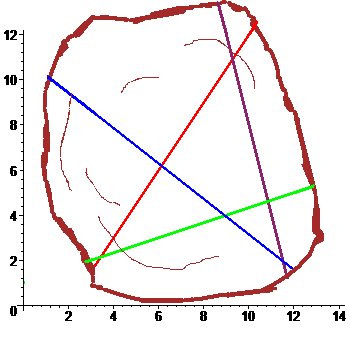
по очереди подходят четыре рыцаря и каждый наносит удар мечом, стараясь попасть по монетке. Все промахиваются. Расстроенные, рыцари уходят в харчевню пропивать злосчастную монетку. Укажите максимально правдоподобное ее расположение, имея перед глазами зарубки: $$ begin 3, x &- 2, y&=& 6,\ x &-3,y&=&-3,\ 11,x& + 14,y&=& 154, \ 4,x&+y&=&48. end $$
Геометрическая интерпретация
Псевдообратная матрица
Пусть сначала матрица $ A_ $ порядка $ mtimes n_ $ — вещественная и $ m ge n_ $ (число строк не меньше числа столбцов). Если $ operatorname (A) = n $ (столбцы матрицы линейно независимы), то псевдообратная к матрице $ A_ $ определяется как матрица $$ A^=(A^A)^ A^ . $$ Эта матрица имеет порядок $ n times m_ $. Матрица $ (A^A)^ $ существует ввиду того факта, что при условии $ operatorname (A) = n $ будет выполнено $ det (A^ A) > 0 $ (см. упражнение в пункте ☞ ТЕОРЕМА БИНЕ-КОШИ или же пункт ☞ СВОЙСТВА ОПРЕДЕЛИТЕЛЯ ГРАМА ). Очевидно, что $ A^ cdot A = E_ $, т.е. псевдообратная матрица является левой обратной для матрицы $ A_ $. В случае $ m=n_ $ псевдообратная матрица совпадает с обратной матрицей: $ A^=A^ $.
Пример. Найти псевдообратную матрицу к матрице $$ A= left( begin 1 & 0 \ 0 & 1 \ 1 & 1 end right) . $$
Решение. $$ A^= left( begin 1 & 0 & 1 \ 0 & 1 & 1 end right) Rightarrow A^ cdot A = left( begin 2 & 1 \ 1 & 2 end right) Rightarrow $$ $$ Rightarrow (A^ cdot A)^ = left( begin 2/3 & -1/3 \ -1/3 & 2/3 end right) Rightarrow $$ $$ Rightarrow quad A^ = (A^ cdot A)^ A^ = left( begin 2/3 & -1/3 & 1/3 \ -1/3 & 2/3 & 1/3 end right) . $$ При этом $$ A^ cdot A = left( begin 1 & 0 \ 0 & 1 end right),quad A cdot A^ = left( begin 2/3 & -1/3 & 1/3 \ -1/3 & 2/3 & 1/3 \ 1/3 & 1/3 & 2/3 end right) , $$ т.е. матрица $ A^ $ не будет правой обратной для матрицы $ A_ $. ♦
Вычислить псевдообратную матрицу для $$ mathbf left( begin 1 & 0 \ 1 & 1 \ 1 & 1 end right) quad ; quad mathbf left( begin x_1 \ x_2 \ x_3 end right) . $$
Концепция псевдообратной матрицы естественным образом возникает из понятия псевдорешения системы линейных уравнений . Если $ A^ $ существует, то псевдорешение (как правило, переопределенной и несовместной!) системы уравнений $ AX=mathcal B_ $ находится по формуле $ X= A^ mathcal B $ при любом столбце $ mathcal B_ $. Верно и обратное: если $ E_, E_,dots, E_ $ – столбцы единичной матрицы $ E_m $: $$ E_=left( begin 1 \ 0 \ 0 \ vdots \ 0 end right), E_=left( begin 0 \ 1 \ 0 \ vdots \ 0 end right),dots, E_=left( begin 0 \ 0 \ 0 \ vdots \ 1 end right), $$ а псевдорешение системы уравнений $ AX=E_ $ обозначить $ X_ $ (оно существует и единственно при условии $ operatorname (A) = n $), то $$ A^=left[X_1,X_2,dots,X_m right] . $$
Теорема. Пусть $ A_ $ вещественная матрица порядка $ mtimes n_ $, $ m ge n_ $ и $ operatorname (A) = n $. Тогда псевдообратная матрица $ A^ $ является решением задачи минимизации
$$ min_<Xin mathbb R^> |AX-E_m|^2 $$ где минимум разыскивается по всем вещественным матрицам $ X_ $ порядка $ ntimes m_ $, а $ || cdot || $ означает евклидову норму матрицы (норму Фробениуса) : $$ |[h_]_|^2=sum_ h_^2 . $$ При сделанных предположениях решение задачи единственно.
С учетом этого результата понятно как распространить понятие псевдообратной матрицы на случай вещественной матрицы $ A_^ $, у которой число строк меньше числа столбцов: $ m ☞ ЗДЕСЬ
Источники
[1]. Беклемишев Д.В. Дополнительные главы линейной алгебры. М.Наука.1983, с.187-234