Множественной регрессии
Для проверки общего качества уравнения регрессии обычно используется коэффициент детерминации R 2 , который характеризует долю дисперсии зависимой переменной Y, объясняемую регрессионной моделью, и определяется по формуле:
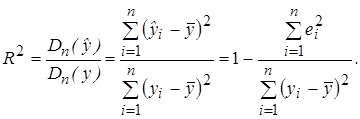 (3.27)
(3.27)
Свойства коэффициента R 2 подробно рассмотрены в разделе 2.4.
Для множественной регрессии коэффициент детерминации (или множественный коэффициент детерминации) является неубывающей функцией числа объясняющих переменных, т. е. добавление новой объясняющей переменной (фактора-аргумента Х) в модель никогда не уменьшает значение R 2 . Действительно, каждая новая объясняющая переменная может лишь дополнить информацию, объясняющую поведение зависимой переменной. В целом это уменьшает неопределенность в поведении исследуемой величины Y. Однако увеличение R 2 при добавлении новых переменных далеко не всегда приводит к улучшению качества регрессионной модели, так как эти переменные могут не оказывать существенного влияния на результативный признак. Поэтому, наряду с коэффициентом R 2 , для анализа используется скорректированный коэффициент детерминации 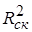 , определяемый соотношением:
, определяемый соотношением:
 (3.28)
(3.28)
или с учетом (3.27)
 . (3.29)
. (3.29)
Можно заметить, что знаменатель в (3.29) является несмещенной оценкой общей дисперсии зависимой переменной Y, а числитель – несмещенной оценкой остаточной дисперсии (дисперсии случайных отклонений).
Скорректированный коэффициент детерминации устраняет (корректирует) неоправданный эффект, связанный с ростом R 2 при увеличении числа объясняющих переменных. Из (3.28) следует, что 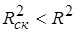 при m > 1 Можно показать, что увеличивается при добавлении новой объясняющей переменной только тогда, когда t-статистика для этой переменной по модулю больше единицы, т. е. когда ее коэффициент регрессии (параметр модели) считается относительно значимым. Таким образом, в определенной степени использование скорректированного коэффициента детерминации более предпочтительно для сравнения регрессионных моделей при изменении количества объясняющих переменных (регрессоров). Добавление в модель новых регрессоров может осуществляться до тех пор, пока растет .
при m > 1 Можно показать, что увеличивается при добавлении новой объясняющей переменной только тогда, когда t-статистика для этой переменной по модулю больше единицы, т. е. когда ее коэффициент регрессии (параметр модели) считается относительно значимым. Таким образом, в определенной степени использование скорректированного коэффициента детерминации более предпочтительно для сравнения регрессионных моделей при изменении количества объясняющих переменных (регрессоров). Добавление в модель новых регрессоров может осуществляться до тех пор, пока растет .
В компьютерных пакетах приводятся данные как по R 2 , так и по , которые используются на практике для оценки суммарной меры общего качества построенной регрессионной модели.
В общем случае качество модели считается удовлетворительным, если R 2 > 0,5. Однако не следует рассматривать коэффициент детерминации как абсолютный показатель качества модели. Можно привести ряд примеров, когда неправильно специфицированные модели имели сравнительно высокие коэффициенты детерминации. Поэтому коэффициент детерминации в современной эконометрике следует рассматривать лишь как один из показателей, который необходим для анализа строящейся модели.
Анализ общей (совокупной) статистической значимости уравнения множественной регрессии осуществляется на основе проверки основной гипотезы об одновременном равенстве нулю всех коэффициентов при объясняющих переменных:
Если данная гипотеза не отклоняется, то естественно считать уравнение модели статистически незначимым, т. е. не выражающим существенную линейную связь между Y и Х1, Х2, …, Хm.
Напомним (см. раздел 2.4.3), что общая дисперсия зависимой переменной Dn(y) может быть представлена в виде суммы двух составляющих:

где  Dn(y) – соответственно, дисперсия, объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Dn(y) – соответственно, дисперсия, объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Исходя из этого проводится дисперсионный анализ для проверки гипотезы Н0 (F-тест).
Строится проверочная F-статистика:
 (3.30)
(3.30)
где  – объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);
– объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);  – остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n — m — 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n — 1 — m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
– остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n — m — 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n — 1 — m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
Если рассчитан коэффициент детерминации R 2 , то критерий значимости уравнения регрессии (3.30) может быть представлен в следующем виде:
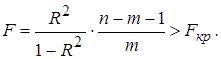 (3.31)
(3.31)
Критерий (3.31) обычно используется на практике для тестирования гипотезы о статистической значимости коэффициента детерминации (Н0 : R 2 = 0; Н1 : R 2 > 0) которая эквивалентна гипотезе об общей статистической значимости уравнения множественной регрессии.
Отметим, что в отличие от парной регрессии, где t-тест и F-тест равносильны, в случае множественной регрессии коэффициент R 2 приобретает самостоятельную значимость.
Пример 3.2. Оценим статистическую значимость построенной модели.
Пусть при оценке регрессии с тремя объясняющими переменными (  по 30 наблюдениям получено значение коэффициента детерминации R 2 = 0,7. Тогда, наблюдаемое значение F-статистики
по 30 наблюдениям получено значение коэффициента детерминации R 2 = 0,7. Тогда, наблюдаемое значение F-статистики 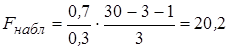 . По таблице критических точек распределения Фишера найдем F0,05; 3; 26 = 2,98 при заданном уровне значимости a = 0,05. Поскольку Fнабл = 20,2 > Fкр = 2,98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
. По таблице критических точек распределения Фишера найдем F0,05; 3; 26 = 2,98 при заданном уровне значимости a = 0,05. Поскольку Fнабл = 20,2 > Fкр = 2,98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
Мультиколлинеарность
Весьма нежелательным эффектом, который может проявляться при построении моделей множественной регрессии и искажать статистическую информацию, полученную по модели, является мультиколлинеарность [1,28,33]– линейная взаимосвязь двух или нескольких объясняющих переменных. Различают функциональную и корреляционную формы мультиколлинеарности.
При функциональной форме мультиколлинеарности по крайней мере два регрессора связаны между собой линейной функциональной зависимостью. В этом случае определитель матрицы Х Т Х равен нулю в силу присутствия линейно зависимых вектор-столбцов (нарушается предпосылка 5 МНК), что приводит к невозможности решения соответствующий системы уравнений и получения оценок параметров регрессионной модели.
Однако в эконометрических исследованиях мультиколлинеарность чаще всего проявляется в более сложной корреляционной форме, когда между хотя бы двумя объясняющими переменными существует тесная корреляционная связь. Ниже рассмотрены некоторые способы обнаружения, а также уменьшения и устранения мультиколлинеарности.
Один из таких способов заключается в исследовании матрицы Х Т Х. Если ее определитель близок к нулю, то это может свидетельствовать о наличии мультиколлинеарности. В этом случае наблюдаются значительные стандартные ошибки коэффициентов регрессии и их статистическая незначимость по t-критерию, хотя в целом регрессионная модель может оказаться значимой по F-тесту.
Другой подход состоит в анализе матрицы парных коэффициентов корреляции между объясняющими переменными (факторами). Если бы факторы не коррелировали между собой, то корреляционная матрица R была бы единичной матрицей, поскольку все недиагональные элементы (хi ¹ xj) равны нулю. Определитель такой матрицы равен единице [Тимофеев, 2013]. Например, для модели, включающей три объясняющих переменных  , в этом случае имеем:
, в этом случае имеем:
 . (3.32)
. (3.32)
Если же, наоборот, между факторами-аргументами существует полная линейная зависимость и все коэффициенты корреляции равны 1 (|rij| = 1), то определитель матрицы межфакторной корреляции равен нулю
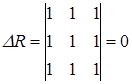 . (3.33)
. (3.33)
Таким образом, чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность объясняющих переменных и ненадежнее оценки множественной регрессии, полученные с использованием МНК.
Если в модели больше двух объясняющих переменных, то для обнаружения мультиколлинеарности полезно находить частные коэффициенты корреляции, поскольку парные коэффициенты корреляции определяют силу линейной зависимости между двумя факторами без учета влияния на них других объясняющих переменных. Например, между двумя экономическими переменными может наблюдаться высокий положительный коэффициент корреляции совсем не потому, что одна из них стимулирует изменение другой, а вследствие того, что обе эти переменные изменяются в одном направлении под влиянием других факторов, присутствующих в модели. Поэтому возникает необходимость оценки действительной тесноты (силы) линейной связи между двумя факторами, очищенной от влияния других переменных. Параметр, определяющий степень корреляции между двумя факторами Хi и Xj при исключении влияния остальных переменных называется частным коэффициентом корреляции.
Например, в случае модели с тремя объясняющими переменными Х1, Х2, Х3 частный коэффициент корреляции между Х1 и Х2 рассчитывается по формуле:
 (3.34)
(3.34)
Частный коэффициент корреляции может существенно отличаться от «обычного» парного коэффициента корреляции r12. Пусть, например, r12 = 0,5; r13 = 0,5; r23 = -0,5. Тогда частный коэффициент корреляции r12.3 = 1 (3.34), т. е. при относительно невысоком коэффициенте корреляции r12 частный коэффициент корреляции указывает на высокую зависимость (коллинеарность) между переменными Хi и Xj.
Таким образом, для обоснованного вывода о корреляции между объясняющими переменными множественной регрессии необходимо рассчитывать частные коэффициенты корреляции.
Частный коэффициент корреляции rij.1, 2, …, m, как и парный коэффициент rij, может принимать значения от -1 до 1. Присутствие в модели пар переменных, имеющих высокие коэффициенты частной корреляции (обычно больше 0,8), свидетельствует о наличии мультиколлинеарности.
Для устранения или уменьшения мультиколлинеарности используется ряд методов, простейшим из которых является исключение из модели одной или нескольких коррелированных переменных. Обычно решение об исключении какой-либо переменной принимается на основании экономических соображений. Следует заметить, что при удалении из анализа объясняющей переменной можно допустить ошибку спецификации. Например, при изучении спроса на некоторый товар в качестве объясняющих переменных целесообразно использовать цену данного товара и цены товаров-заменителей, которые зачастую коррелируют друг с другом. Исключив из модели цены заменителей, мы, вероятнее всего, допустим ошибку спецификации. Вследствие этого можно получить смещенные оценки и сделать ненадежные выводы.
Иногда для уменьшения мультиколлинеарности достаточно (если это возможно) увеличить объем выборки. Например, при использовании ежегодных показателей можно перейти к поквартальным данным. Увеличение количества данных сокращает дисперсии коэффициентов регрессионной модели и тем самым увеличивает их статистическую значимость.
В ряде случаев минимизировать либо вообще устранить мультиколлинеарность можно с помощью преобразования переменных, в результате которого осуществляется переход к новым переменным, представляющим собой линейные или относительные комбинации исходных [11].
Например, построенная регрессионная модель имеет вид:
 (3.35)
(3.35)
причем Х1 и Х2 – коррелированные переменные. В этом случае целесообразно оценивать регрессионные уравнения относительных величин:
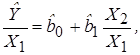
 .
.
Следует ожидать, что в моделях, построенных аналогично (3.36), эффект мультиколлинеарности не будет проявляться.
Существуют также другие, более теоретически разработанные способы обнаружения и подавления мультиколлинеарности, подробное описание которых выходит за рамки данной книги. Одним из таких методов является факторный анализ. Сущностью факторного анализа является процедура вращения факторов, т.е. перераспределение дисперсии по определённому методу с целью получения максимально простой и наглядной структуры факторов (выделение главных компонент) [23,35]. В результате проведения факторного анализа можно соответствующим образом сократить число переменных, тем самым избежать проявления мультиколлинеарности. При этом в один фактор объединяются сильно коррелирующие между собой переменные, что позволяет проводить регрессионный анализ на главных компонентах.
Факторный анализ играет большую самостоятельную роль в экономике и, прежде всего, разработан для поиска ненаблюдаемых, латентных переменных (факторов), имеющих определённый социально-экономический смысл [23].
Следует заметить, что если основная задача, решаемая с помощью эконометрической модели – прогнозирование поведения реального экономического объекта, то при общем удовлетворительном качестве модели проявление мультиколлинеарности не является слишком серьезной проблемой, требующей приложения больших усилий по ее выявлению и устранению, т. к. в данном случае наличие мультиколлинеарности не будет существенно сказываться на прогнозных качествах модели. Таким образом, вопрос о том – следует ли серьезно заниматься проблемой мультиколлинеарности или «смириться» с ее проявлением – решается исходя из целей и задач эконометрического анализа.
Вопросы и упражнения для самопроверки
1. Какова общая структура модели множественной линейной регрессии?
2. Опишите алгоритм определения коэффициентов множественной линейной регрессии (параметров модели) по МНК в матричной форме.
3. Как определяется статистическая значимость коэффициентов регрессии?
4. В чем суть скорректированного коэффициента детерминации и его отличие от обычного R 2 ?
5. Как используется F-статистика во множественном регрессионном анализе?
6. Вычислите величину стандартной ошибки регрессионной модели со свободным членом и без него, если 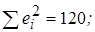 n = 30; m = 3.
n = 30; m = 3.
7. На основе n = 30 наблюдений оценена модель с тремя объясняющими переменными. Получены следующие результаты:

Стандартные ошибки (2,5) (1,6) (2,8) (0,07)
Проведите необходимые расчеты и занесите данные в скобки. Сделайте выводы о существенности коэффициентов регрессии на уровне значимости a =0,05.
8. Имеются данные о ставках месячных доходов по трем акциям за шестимесячный период:
| Акция | Доходы по месяцам, % | |||||
| А | 5,4 | 5,3 | 4,9 | 4,9 | 5,4 | 6,0 |
| В | 6,3 | 6,2 | 6,1 | 5,8 | 5,7 | 5,7 |
| С | 9,2 | 9,2 | 9,1 | 9,0 | 8,7 | 8,6 |
Есть основания предполагать, что доходы по акции С(Y) зависят от доходов по акциям А(X1) и В(X2). Необходимо:
а) составить уравнение регрессии Y по X1 и X2 с использованием МНК (указание: для удобства вычислений сумм первых степеней, квадратов и попарных произведений переменных составьте вспомогательную таблицу);
б) найти множественный коэффициент детерминации R 2 и оценить общее качество построенной модели;
в) проверить значимость полученного уравнения регрессионной модели на уровне a = 0,05.
9. Объясните суть матрицы ковариаций случайных отклонений.
10. Дайте определение и объясните смысл мультиколлинеарности факторов-аргументов.
11. Каковы основные последствия мультиколлинеарности?
12. Какие вы знаете способы обнаружения мультиколлинеарности?
13. Как оценивается степень коррелированности между двумя объясняющими переменными?
14. Перечислите основные методы устранения мультиколлинеарности.
15. В чем заключается сущность факторного анализа?
16. Как определяются парный и частный коэффициенты корреляции для независимых переменных.
17. Для модели с тремя независимыми переменными X1, X2, X3 построенной по n = 50 наблюдениям, определена следующая корреляционная матрица:
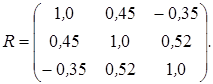
б) определить, имеет ли место мультиколлинеарность для уравнения регрессии.
Анализ общего качества уравнения регрессии.
Коэффициент детерминации R 2
После проверки точности и статистической значимости каждого коэффициента регрессионной модели обычно проводится анализ общего качества уравнения модели, которое оценивается по тому, как хорошо эмпирическое уравнение регрессии согласуется со статистическими данными. Другими словами, необходимо оценить, насколько широко рассеяны точки наблюдений по их совокупности относительно линии регрессии (линии модели). Поэтому представляется естественным вывод о том, что проверку общего качества регрессионной модели следует проводить на основе дисперсионного анализа, сравнивая дисперсии модельных и реальных значений исследуемой переменной Y.
Рассмотрим для определенного набора наблюдений n дисперсию Dn(y), которая характеризует разброс значений yi вокруг среднего значения. Из дисперсионного анализа следует, что эту дисперсию можно разбить на две части: объясняемую уравнением регрессии и не объясняемую (т. е. связанную со случайными отклонениями ei). Тогда выполняется следующее соотношение:
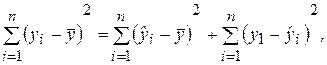 (2.27)
(2.27)
где 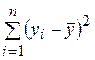 – общая сумма квадратов отклонений зависимой переменной Y от среднего значения;
– общая сумма квадратов отклонений зависимой переменной Y от среднего значения;
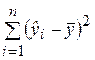 – сумма квадратов, объясняемая уравнением регрессии;
– сумма квадратов, объясняемая уравнением регрессии;
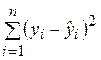 – необъясненная (остаточная) сумма квадратов. Напомним, что
– необъясненная (остаточная) сумма квадратов. Напомним, что 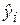 определяется как
определяется как 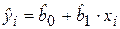 , а
, а 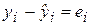 .
.
Разделив выражение (2.27) на его левую часть, получим формулу для оценки характеристики, которая обозначается как R 2 и называется коэффициентом детерминации:
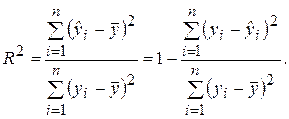 (2.28)
(2.28)
Коэффициент детерминации R 2 является мерой качества уравнения регрессионной модели и определяет долю дисперсии (разброса), объясняемую регрессией Y на Х, в общей дисперсии зависимой переменной Y.
Из проведенных рассуждений следует, что R 2 принимает значения между 0 и 1 (0 £ R 2 £ 1). Чем ближе R 2 к единице, тем теснее линейная связь между Х и Y (экспериментальные точки теснее примыкают к линии регрессии). Чем ближе R 2 к нулю, тем такая связь слабее. Если R 2 = 0, то дисперсия зависимой переменной полностью обусловлена воздействием неучтенных факторов и линия регрессии (модели) должна быть параллельна оси абсцисс (Y = 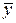 ).
).
Например, если для построенной модели R 2 = 0,7, то согласно (2.28) можно утверждать, что поведение зависимой переменной (результативного признака) Y на 70 % объясняется влиянием фактора Х и на 30 % обусловлено влиянием неучтенных факторов. Доля влияния неучтенных факторов связана со случайными отклонениями ei и определяется отношением 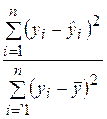 , характеризующим долю разброса зависимой переменной, не объясняемую линейной регрессией Y на Х.
, характеризующим долю разброса зависимой переменной, не объясняемую линейной регрессией Y на Х.
Естественно, что для исследуемого объекта наиболее качественной будет считаться модель с наибольшим значением коэффициента детерминации R 2 .
Заметим, что коэффициент детерминации имеет смысл рассматривать только при наличии параметра 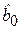 (свободного члена) в уравнении регрессионной модели.
(свободного члена) в уравнении регрессионной модели.
Таким образом, коэффициент детерминации R 2 определяет степень тесноты статистической связи между Y и Х. Но об этом же говорит выборочный коэффициент корреляции rxy. Рассматривая эти характеристики, можно установить, что в случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции 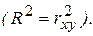
Действительно, учитывая (2.13),
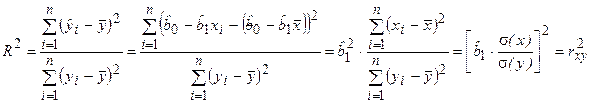 .
.
Естественно, возникает вопрос, какое значение R 2 можно считать удовлетворительным. Ответ на этот вопрос может быть неоднозначным, особенно в случае множественной регрессионной модели и зависит от объема выборки n и постановки задачи, вытекающей из предмодельного анализа.
Более точно проверить значимость уравнения регрессии, т. е. установить, соответствует ли построенная модель реальным данным и достаточно ли включенных в уравнение объясняющих переменных для описания зависимой переменной, позволяет F-тест, который проводится по схеме статистической проверки гипотез. Тестируется гипотеза Н0 о статистической незначимости уравнения регрессии.
Рассмотрим «объясненную» и «необъясненную» дисперсии: 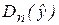 и Dn(e). Отношение этих дисперсий, рассчитанное на одну степень свободы, имеет F-распределение (F-статистику), фактически наблюдаемое значение которой для парной регрессии определяется формулой
и Dn(e). Отношение этих дисперсий, рассчитанное на одну степень свободы, имеет F-распределение (F-статистику), фактически наблюдаемое значение которой для парной регрессии определяется формулой
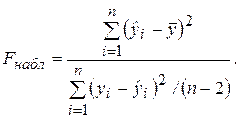 (2.29)
(2.29)
Учитывая смысл дисперсий и Dn(e), можно считать, что значение Fнабл показывает, в какой мере уравнение регрессии лучше оценивает значение зависимой переменной по сравнению с 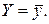
Согласно схеме статистической проверки гипотез, гипотеза Н0 отклоняется, т. е. признается статистическая значимость и надежность уравнения регрессии на заданном уровне α, если Fнабл превосходит критическое (табличное) значение F-статистики Фишера (Fнабл > Fкр = Fα, 1, n — 2). Если Fнабл 2 . В этом случае гипотеза Н0 о статистической незначимости регрессионной модели заменяется эквивалентной гипотезой о статистической незначимости R 2 .
Для парной регрессионной модели способы проверки значимости коэффициента 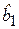 с использованием t-критерия (t-тест) и уравнения регрессии (показателя тесноты связи R 2 ) с использованием F-критерия равносильны, поскольку эти критерии связаны соотношением F = t 2 .
с использованием t-критерия (t-тест) и уравнения регрессии (показателя тесноты связи R 2 ) с использованием F-критерия равносильны, поскольку эти критерии связаны соотношением F = t 2 .
Наряду с коэффициентом детерминации R 2 для оценки качества парной регрессионной модели можно использовать характеристику, называемую средней ошибкой аппроксимации 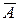 :
:
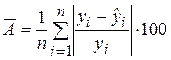 %. (2.31)
%. (2.31)
Средняя ошибка аппроксимации определяет среднее относительное отклонение расчетных данных (оцененных по уравнению модели) от фактических. является безразмерной величиной и обычно выражается в процентах. Принято считать, что качество модели считается удовлетворительным, если средняя ошибка аппроксимации не превышает 8-9 %.
Пример 2.3.Проверить общее качество и статистическую значимость уравнения регрессии для модели, построенной в примере 2.1.
Оценку качества построенной модели дают коэффициент детерминации R 2 и средняя ошибка аппроксимации 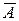 .
.
Вычислим коэффициент детерминации, воспользовавшись данными табл. 2.1.
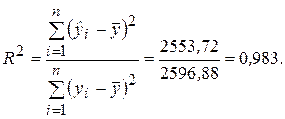
Величина коэффициента детерминации показывает, что поведение результативного признака (недельного потребления) Y на 98,3 % объясняется влиянием фактора Х (изменением недельного дохода), а остальные 1,7 % составляют долю необъясненной вариации, происходящей под действием прочих (неучтенных) факторов.
Расчет средней ошибки аппроксимации представлен в последнем столбце табл. 2.1.
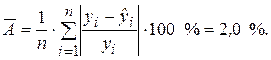
Рассчитанные значения коэффициента детерминации и средней ошибки аппроксимации свидетельствуют о достаточно высоком общем качестве построенной модели.
Проверим статистическую значимость уравнения регрессионной модели с помощью F-теста. Расчетное (наблюдаемое) значение F-статистики Фишера вычисляется по формуле:
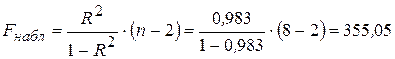 .
.
Табличное значение F-статистики при уровне значимости α = 0,01 и числе степеней свободы ν = n – 2 будет составлять 13,75 (Fкр = 13,75).
Так как Fнабл > Fкр (355,05 > 13,75), то нулевая гипотеза Н0 отклоняется и уравнение регрессионной модели признается статистически значимым и весьма надежным, поскольку наблюдаемое значение F-статистики превосходит табличное значение критерия более чем в 25 раз.
Дата добавления: 2016-06-02 ; просмотров: 2225 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Проверка значимости регрессии с помощью дисперсионного анализа (F-тест)
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем проверку значимости простой линейной регрессии с помощью процедуры F -тест.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Процедуру F -теста рассмотрим на примере простой линейной регрессии , когда прогнозируемая переменная Y зависит только от одной переменной Х.
Чтобы определить может ли предложенная модель линейной регрессии быть использована для адекватного описания значений переменной Y, дисперсию наблюдаемых данных анализируют методом Дисперсионного анализа (ANOVA for Simple Regression) . Дисперсия данных разбивается на компоненты, которые затем используются в F -тесте для определения значимости регрессии.
F -тест для проверки значимости регрессии НЕ относится к простым и интуитивно понятным процедурам. Вероятно, это связано с тем, что для проведения F -теста требуется быть знакомым с определенным количеством статистических понятий и нужно неплохо разбираться в связанных с ними статистических методах. Нам потребуются понятия из следующих разделов статистики:
Можно, конечно, рассмотреть F -тест формально:
- вычислить на основании выборки значение тестовойFстатистики;
- сравнить полученное значение со значением, соответствующему заданному уровню значимости ;
- в зависимости от соотношения этих величин принять решение о значимости вычисленной линейной регрессии
В этой статье ставится более амбициозная задача – разобраться в самом подходе, на котором основан F -тест . Сначала введем несколько определений, которые используются в процедуре F -теста , затем рассмотрим саму процедуру.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части .
Определения, необходимые для F -теста
Согласно определению дисперсии , дисперсия выборки прогнозируемой переменной Y определяется формулой:
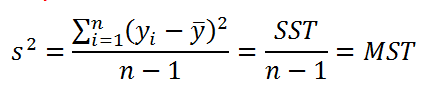
В формуле используется ряд сокращений:
- SST (Total Sum of Squares) – это просто компактное обозначение Суммы Квадратов отклонений от среднего (такое сокращение часто используется в зарубежной литературе).
- MST (Total Mean Square) – Среднее Суммы Квадратов отклонений (еще одно общеупотребительное сокращение).
Примечание : Необходимо иметь в виду, что с одной стороны величины MST и SST являются случайными величинами, вычисленными на основании выборки, т.е. статистиками . Однако с другой стороны, при проведении регрессионного анализа по данным имеющейся выборки вычисляются их конкретные значения. В этом случае величины MST и SST являются просто числами.
Значение n-1 в вышеуказанной формуле равно числу степеней свободы ( DF ) , которое относится к дисперсии выборки (одна степень свободы у n величин yi потеряна в результате наличия ограничения 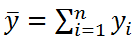 , связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
, связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
Как видно из формулы, отношение величин SST и DFT обозначается как MST. Эти 3 величины обычно выдаются в таблице результатов дисперсионного анализа в различных прикладных статистических программах (в том числе и в надстройке Пакет анализа, инструмент Регрессия ).
Значение SST, характеризующую общую изменчивость переменной Y, можно разбить на 2 компоненты:
- Изменчивость объясненную моделью (Explained variation), обозначается SSR
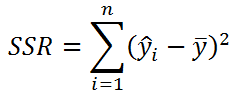
- Необъясненную изменчивость (Unexplained variation), обозначается SSЕ
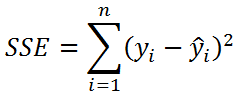
Известно , что справедливо равенство:
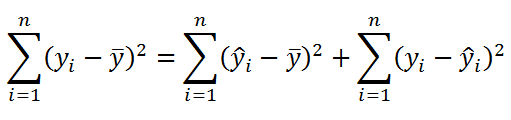
Величинам SSR и SSE также сопоставлены степени свободы . У SSR одна степень свободы , т.к. она однозначно определяется одним параметром – наклоном линии регрессии a (напомним, что мы рассматриваем простую линейную регрессию ). Это очевидно из формулы:
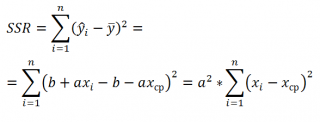
Примечание: Очевидность наличия только одной степени свободы проистекает из факта, что переменная Х – контролируемая (не является случайной величиной).
Число степеней свободы величины SSR имеет специальное обозначение: DFR (для простой регрессии DFR=1, т.к. число независимых переменных Х равно 1) . По аналогии с MST, отношение этих величин также часто обозначают MSR = SSR / DFR .
У SSE число степеней свободы равно n -2 , которое обозначается как DFE (или DFRES — residual degrees of freedom). Двойка вычитается, т.к. изменчивость переменной yi имеет 2 ограничения, связанные с оценкой 2-х параметров линейной модели ( а и b ): ŷi=a*xi+b
Отношение этих величин также часто обозначают MSE = SSE / DFE .
MSR и MSE имеют размерность дисперсий, хотя корректней их называть средними значениями квадратов отклонений. Тем не менее, ниже мы их будем «дисперсиями», т.к. они отображают меру разброса: MSE – меру разброса точек наблюдений относительно линии регрессии, MSR показывает насколько линия регрессии совпадает с горизонтальной линией среднего значения Y.
Примечание : Напомним, что MSE (Mean Square of Errors) является оценкой дисперсии s 2 ошибки, подробнее см. статью про линейную регрессию , раздел Стандартная ошибка регрессии .
Число степеней свободы обладает свойством аддитивности: DFT = DFR + DFE . В этом можно убедиться, составив соответствующее равенство n -1=1+( n -2)
Наконец, определившись с определениями, переходим к рассмотрению самой процедуры F -тест .
Процедура F -теста
Сущность F -теста при проверке значимости регрессии заключается в том, чтобы сравнить 2 дисперсии : объясненную моделью (MSR) и необъясненную (MSE). Если эти дисперсии «примерно равны», то регрессия незначима (построенная модель не позволяет объяснить поведение прогнозируемой Y в зависимости от значений переменной Х). Если дисперсия, объясненная моделью (MSR) «существенно больше», чем необъясненная, то регрессия значимая .
Примечание : Чтобы быстрее разобраться с процедурой F -теста рекомендуется вспомнить процедуру проверки статистических гипотез о равенстве дисперсий 2-х нормальных распределений (т.е. двухвыборочный F-тест для дисперсий ).
Чтобы пояснить вышесказанное изобразим на диаграммах рассеяния 2 случая:
- регрессия значима (в этом случае имеем значительный наклон прямой) и
- регрессия незначима (линия регрессии близка к горизонтальной прямой).
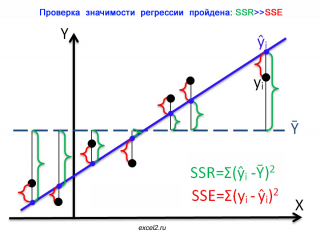
На первой диаграмме показан случай, когда регрессия значима:
- Зеленым цветом выделены расстояния от среднего значения до линии регрессии , вычисленные для каждого хi. Сумма квадратов этих расстояний равна SSR;
- Красным цветом выделены расстояния от линии регрессии до соответствующих точек наблюдений . Сумма квадратов этих расстояний равна SSЕ.
Из диаграммы видно, что в случае значимой регрессии, сумма квадратов «зеленых» расстояний, гораздо больше суммы квадратов «красных». Понятно, что их отношение будет гораздо больше 1. Следовательно, и отношение дисперсий MSR и MSE будет гораздо больше 1 (не забываем, что SSE нужно разделить еще на соответствующее количество степеней свободы n-2).
В случае значимой регрессии точки наблюдений будут находиться вдоль линии регрессии. Их разброс вокруг этой линии описываются ошибками регрессии, которые были минимизированы посредством процедуры МНК . Очевидно, что разброс точек относительно линии регрессии значительно меньше, чем относительно горизонтальной линии, соответствующей среднему значению Y.
Совершенно другую картину мы можем наблюдать в случае незначимой регрессии.
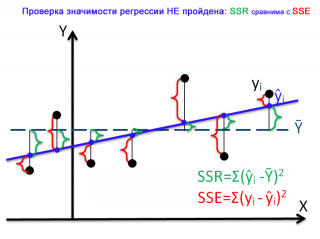
Очевидно, что в этом случае, сумма квадратов «зеленых» расстояний, примерно соответствует сумме квадратов «красных». Это означает, что объясненная дисперсия примерно соответствует величине необъясненной дисперсии (MSR/MSE будет близко к 1).
Если ответ о значимости регрессии практически очевиден для 2-х вышеуказанных крайних ситуаций, то как сделать правильное заключение для промежуточных углов наклона линии регрессии?
Понятно, что если вычисленное на основании выборки значение MSR/MSE будет существенно больше некоторого критического значения, то регрессия значима, если нет, то не значима. Очевидно, что это значение должно быть больше 1, но как определить это критическое значение статистически обоснованным методом ?
Вспомним, что для формулирования статистического вывода (т.е. значима регрессия или нет) используют проверку гипотез . Для этого формулируют 2 гипотезы: нулевую Н 0 и альтернативную Н 1 . Для проверки значимости регрессии в качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. наклон прямой a=0. В качестве альтернативной гипотезы Н 1 принимают, что a 0.
Примечание : Даже если связи между переменными нет (a=0), то вычисленная на основании данных выборки оценка наклона — величина а , из-за случайности выборки будет близка, но все же отлична от 0.
По умолчанию принимается, что нулевая гипотеза верна – связи между переменными нет. Если это так, то:
- MSR/MSE будет близко к 1;
- Случайная величина F = MSR/MSE будет иметь F-распределениесо степенями свободы 1 (в числителе) и n-2 (знаменателе). F является тестовой статистикой для проверки значимости регрессии.
Примечание : MSR и MSE являются случайными величинами (т.к. они получены на основе случайной выборки). Соответственно, выражение F=MSR/MSE, также является случайной величиной, которая имеет свое распределение, среднее значение и дисперсию .
Ниже приведен график плотности вероятности F-распределения со степенями свободы 1 (в числителе) и 59 (знаменателе). 59=61-2, 61 наблюдение минус 2 степени свободы.
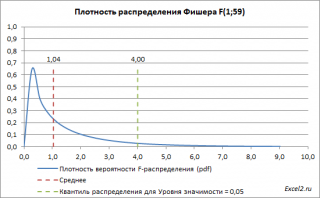
Если нулевая гипотеза верна, то значение F 0 =MSR/MSE, вычисленное на основании выборки, должно быть около ее среднего значения (т.е. около 1,04). Если F 0 будет существенно больше 1 (чем больше F0 отклоняется в сторону больших значений, тем это маловероятней), то это будет означать, что F не имеет F-распределение , а, следовательно, нулевую гипотезу нужно отклонить и принять альтернативную, утверждающую, что связь между переменными есть (значима).
Обычно предполагают, что если вероятность, того что F -статистика приняла значение F0 составляет менее 5%, то это событие маловероятно и нулевую гипотезу необходимо отклонить. 5% — это заданный исследователем уровень значимости , который может быть, например, 1% или 10%.
Значение статистики F0 может быть вычислено на основании выборки:
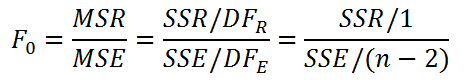
Вычисления в MS EXCEL
В MS EXCEL критическое значение для заданного уровня значимости F1-альфа, 1, n-2 можно вычислить по формуле = F.ОБР(1- альфа;1; n-2) или = F.ОБР.ПХ(альфа;1; n-2) . Другими словами требуется вычислить верхний альфа-квантиль F-распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F0> F1-альфа, 1, n-2 мы имеем основание для отклонения нулевой гипотезы.
Значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В случае простой регрессии значение F0 также равно квадрату t-статистики, которую мы использовали при проверке двусторонней гипотезе о равенстве 0 коэффициента регрессии .
Проверку значимости регрессии можно также осуществить через вычисление p-значения. В этом случае вычисляют вероятность того, что случайная величина F примет значение F0 (это и есть p-значение), затем сравнивают p-значение с заданным уровнем значимости . Если p-значение больше уровня значимости, то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL для проверки гипотезы используя p -значение используйте формулу = F.РАСП.ПХ(F0;1;n-2) файл примера , где показано эквивалентность всех подходов проверки значимости регрессии).
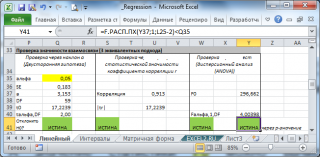
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Таблица, которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .