- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации R 2
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
- Линейная регрессия в машинном обучении
- Применение линейной регрессии
- Функция потерь — метод наименьших квадратов
- Больше размерностей
- Проклятие нелинейности
- Метод Уэлфорда и одномерная линейная регрессия
- Содержание
- 1. Одномерная линейная регрессия
- 2. Решение для центрированных выборок
- 3. Решение в общем случае
- 4. Применение метода Уэлфорда
- 5. Экспериментальное сравнение методов
- Заключение
- Линейный многомерный регрессионный анализ
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В MS EXCEL имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Примечание : Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место множественная регрессия .
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части — оценке неизвестных параметров линейной модели .
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем прочность этого волокна (Y) зависит только от рабочей температуры процесса в реакторе (Х), которая задается оператором.
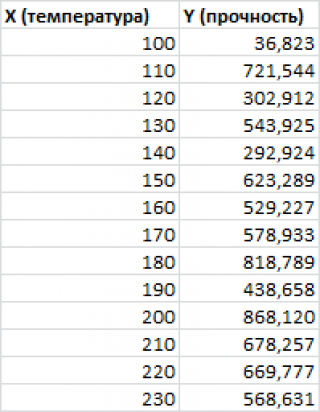
Построим диаграмму рассеяния (см. файл примера лист Линейный ), созданию которой посвящена отдельная статья . Вообще, построение диаграммы рассеяния для целей регрессионного анализа де-факто является стандартом.
СОВЕТ : Подробнее о построении различных типов диаграмм см. статьи Основы построения диаграмм и Основные типы диаграмм .
Приведенная выше диаграмма рассеяния свидетельствует о возможной линейной взаимосвязи между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание : Наличие даже такой очевидной линейной взаимосвязи не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие причинной взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание : Как известно, уравнение прямой линии имеет вид Y = m * X + k , где коэффициент m отвечает за наклон линии ( slope ), k – за сдвиг линии по вертикали ( intercept ), k равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х ( рабочую температуру процесса ) при некотором значении Х i и произвести несколько наблюдений переменной Y ( прочность нити ). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого значения . При увеличении количества измерений, среднее этих измерений, будет стремиться к математическому ожиданию случайной величины Y (при Х i ) равному μy(i)=Е(Y i ).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела Проверка статистических гипотез . В статье о проверке гипотезы о среднем значении генеральной совокупности в качестве нулевой гипотезы предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае простой линейной регрессии в качестве нулевой гипотезы предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ y(i) =α* Х i +β. Уравнение μ y(i) =α* Х i +β можно переписать в обобщенном виде (для всех Х и μ y ) как μ y =α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
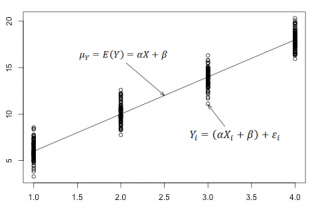
Данная линия называется регрессионной линией генеральной совокупности (population regression line), параметры которой ( наклон a и сдвиг β ) нам не известны (по аналогии с гипотезой о среднем значении генеральной совокупности , где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х + β , к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют линейной регрессионной моделью . Часто Х еще называют независимой переменной (еще предиктором и регрессором , английский термин predictor , regressor ), а Y – зависимой (или объясняемой , response variable ). Так как регрессор у нас один, то такая модель называется простой линейной регрессионной моделью ( simple linear regression model ). α часто называют коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε i была адекватной — требуется:
- Ошибки ε i должны быть независимыми переменными;
- При каждом значении Xi ошибки ε i должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε i ]=0);
- При каждом значении Xi ошибки ε i должны иметь равные дисперсии (обозначим ее σ 2 ).
Примечание : Последнее условие называется гомоскедастичность — стабильность, гомогенность дисперсии случайной ошибки e. Т.е. дисперсия ошибки σ 2 не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε i ]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε i ]= Е[a*Xi+β]+ Е[ε i ]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия случайной переменной Y равна дисперсии ошибки ε, т.е. VAR(Y)= VAR(ε)=σ 2 . Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε i ).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует регрессионная линия генеральной совокупности , т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений .
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно a и b . Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Первая задача регрессионного анализа – оценка неизвестных параметров ( estimation of the unknown parameters ). Подробнее см. раздел Оценки неизвестных параметров модели .
Вторая задача регрессионного анализа – Проверка адекватности модели ( model adequacy checking ).
Примечание : Оценки параметров модели обычно вычисляются методом наименьших квадратов (МНК), которому посвящена отдельная статья .
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры простой линейной регрессионной модели Y=a*X+β+ε оценим с помощью метода наименьших квадратов (в статье про МНК подробно описано этот метод ).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
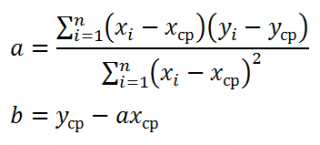
Таким образом, мы получим уравнение прямой линии Y= a *X+ b , которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание : В статье про метод наименьших квадратов рассмотрены случаи аппроксимации линейной и квадратичной функцией , а также степенной , логарифмической и экспоненциальной функцией .
Оценку параметров в MS EXCEL можно выполнить различными способами:
Сначала рассмотрим функции НАКЛОН() , ОТРЕЗОК() и ЛИНЕЙН() .
Пусть значения Х и Y находятся соответственно в диапазонах C 23: C 83 и B 23: B 83 (см. файл примера внизу статьи).
Примечание : Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью Генерация данных для линейной регрессии в MS EXCEL ).
В MS EXCEL наклон прямой линии а ( оценку коэффициента регрессии ), можно найти по методу МНК с помощью функции НАКЛОН() , а сдвиг b ( оценку постоянного члена или константы регрессии ), с помощью функции ОТРЕЗОК() . В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции ЛИНЕЙН() , английская версия LINEST (см. статью об этой функции ).
Формула =ЛИНЕЙН(C23:C83;B23:B83) вернет наклон а . А формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) — сдвиг b . Здесь требуются пояснения.
Функция ЛИНЕЙН() имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент статистика имеет значение ЛОЖЬ или опущен, то функция ЛИНЕЙН() возвращает только оценки параметров модели: a и b .
Примечание : Остальные значения, возвращаемые функцией ЛИНЕЙН() , нам потребуются при вычислении стандартных ошибок и для проверки значимости регрессии . В этом случае аргумент статистика должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
- ввести формулу в Строке формул
- нажать CTRL+SHIFT+ENTER (см. статью про формулы массива ).
Если в Строке формул выделить формулу = ЛИНЕЙН(C23:C83;B23:B83) и нажать клавишу F9 , то мы увидим что-то типа . Это как раз значения a и b . Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу = ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83)) . При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция ТРАНСП() транспонировала строку в столбец ).
Чтобы разобраться в этом подробнее необходимо ознакомиться с формулами массива .
Чтобы не связываться с вводом формул массива , можно использовать функцию ИНДЕКС() . Формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1) или просто ЛИНЕЙН(C23:C83;B23:B83) вернет параметр, отвечающий за наклон линии, т.е. а . Формула =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) вернет параметр b .
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент а , можно также вычислить через коэффициент корреляции и стандартные отклонения выборок :
= КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению ковариации выборок Х и Y и дисперсии выборки Х:
И, наконец, запишем еще одну формулу для нахождения сдвига b . Воспользуемся тем фактом, что линия регрессии проходит через точку средних значений переменных Х и Y.
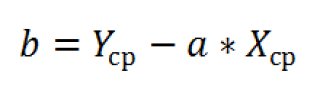
Вычислив средние значения и подставив в формулу ранее найденный наклон а , получим сдвиг b .
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры линии регрессии можно найти в матричной форме (см. файл примера лист Матричная форма ).
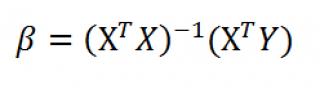
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг b ), β1 (наклон a ).
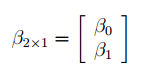
Матрица Х равна:
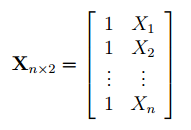
Матрица Х называется регрессионной матрицей или матрицей плана . Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица Х T – это транспонированная матрица Х . Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом Y обозначен столбец значений переменной Y.
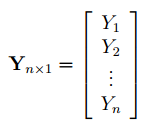
Чтобы перемножить матрицы используйте функцию МУМНОЖ() . Чтобы найти обратную матрицу используйте функцию МОБР() .
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
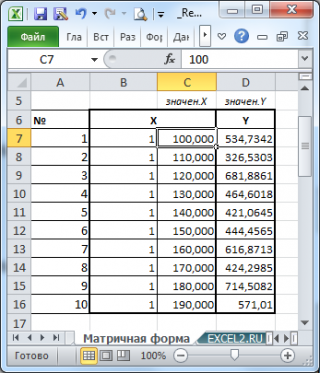
Слева от него достроим столбец с 1 для матрицы Х.
и введя ее как формулу массива в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае множественной регрессии .
Построение линии регрессии
Для отображения линии регрессии построим сначала диаграмму рассеяния , на которой отобразим все точки (см. начало статьи ).
Для построения прямой линии используйте вычисленные выше оценки параметров модели a и b (т.е. вычислите у по формуле y = a * x + b ) или функцию ТЕНДЕНЦИЯ() .
Формула = ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23) возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца В2 .
Примечание : Линию регрессии можно также построить с помощью функции ПРЕДСКАЗ() . Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции ТЕНДЕНЦИЯ() работает только в случае одного регрессора. Функция ТЕНДЕНЦИЯ() может быть использована и в случае множественной регрессии (в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
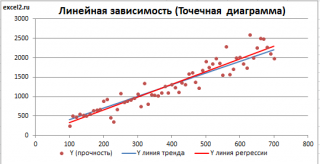
Как видно из диаграммы выше линия тренда и линия регрессии не обязательно совпадают: отклонения точек от линии тренда случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента Линия тренда. Для этого выделите диаграмму, в меню выберите вкладку Макет , в группе Анализ нажмите Линия тренда , затем Линейное приближение. В диалоговом окне установите галочку Показывать уравнение на диаграмме (подробнее см. в статье про МНК ).
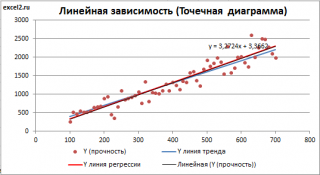
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами линией регрессии, а параметры уравнения a и b должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание: Для того, чтобы вычисленные параметры уравнения a и b совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был Точечная, а не График , т.к. тип диаграммы График не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; . Именно эти значения и берутся при расчете параметров линии тренда . Убедиться в этом можно если построить диаграмму График (см. файл примера ), а значения Хнач и Хшаг установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с a и b .
Коэффициент детерминации R 2
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения регрессионной модели ). Очевидно, что лучшей оценкой для yi будет среднее значение ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание : Далее будет использована терминология и обозначения дисперсионного анализа .
После построения регрессионной модели для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
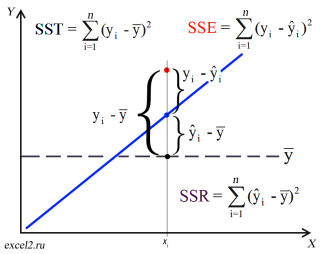
Очевидно, что используя регрессионную модель мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
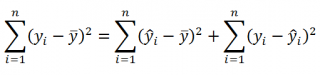
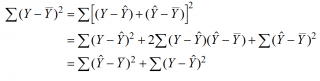
или в других, общепринятых в зарубежной литературе, обозначениях:
Total Sum of Squares = Regression Sum of Squares + Error Sum of Squares
Примечание : SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность дисперсии (вариации) и соответственно описывают разброс (изменчивость): Общую изменчивость (Total variation), Изменчивость объясненную моделью (Explained variation) и Необъясненную изменчивость (Unexplained variation).
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью / Общая изменчивость.
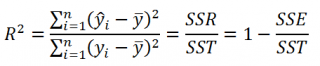
Этот показатель равен квадрату коэффициента корреляции и в MS EXCEL его можно вычислить с помощью функции КВПИРСОН() или ЛИНЕЙН() :
R 2 принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии ( Standard Error of a regression ) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение линейной регрессионной модели Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со средним значением μ и дисперсией σ 2 .
Оценив значение дисперсии σ 2 и вычислив из нее квадратный корень – получим Стандартную ошибку регрессии. Чем точки наблюдений на диаграмме рассеяния ближе находятся к прямой линии, тем меньше Стандартная ошибка.
Примечание : Вспомним , что при построении модели предполагается, что среднее значение ошибки ε равно 0, т.е. E[ε]=0.
Оценим дисперсию σ 2 . Помимо вычисления Стандартной ошибки регрессии эта оценка нам потребуется в дальнейшем еще и при построении доверительных интервалов для оценки параметров регрессии a и b .
Для оценки дисперсии ошибки ε используем остатки регрессии — разности между имеющимися значениями yi и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки дисперсии σ 2 используют следующую формулу:
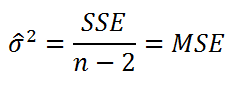
где SSE – сумма квадратов значений ошибок модели ε i =yi — ŷi ( Sum of Squared Errors ).
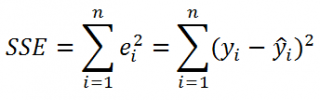
SSE часто обозначают и как SSres – сумма квадратов остатков ( Sum of Squared residuals ).
Оценка дисперсии s 2 также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов ошибок или MSRES (Mean Square of Residuals), т.е. среднее квадратов остатков . Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание : Напомним, что когда мы использовали МНК для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на линии регрессии.
Математическое ожидание случайной величины MSE равно дисперсии ошибки ε, т.е. σ 2 .
Чтобы понять почему SSE выбрана в качестве основы для оценки дисперсии ошибки ε, вспомним, что σ 2 является также дисперсией случайной величины Y (относительно среднего значения μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi = a * Хi + b (значение уравнения регрессии при Х= Хi), то логично использовать именно SSE в качестве основы для оценки дисперсии σ 2 . Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае простой линейной регрессии число степеней свободы равно n-2, т.к. при построении линии регрессии было оценено 2 параметра модели (на это было «потрачено» 2 степени свободы ).
Итак, как сказано было выше, квадратный корень из s 2 имеет специальное название Стандартная ошибка регрессии ( Standard Error of a regression ) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см. этот раздел ). Если ошибки предсказания ε имеют нормальное распределение , то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от линии регрессии . SEy имеет размерность переменной Y и откладывается по вертикали. Часто на диаграмме рассеяния строят границы предсказания соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
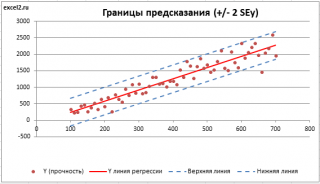
В MS EXCEL стандартную ошибку SEy можно вычислить непосредственно по формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
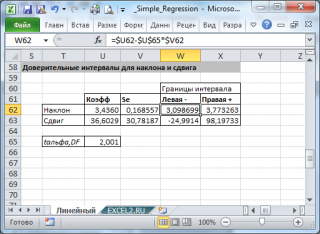
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе Оценка неизвестных параметров линейной модели мы получили точечные оценки наклона а и сдвига b . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ).
Стандартная ошибка коэффициента регрессии a вычисляется на основании стандартной ошибки регрессии по следующей формуле:
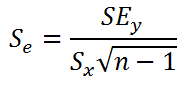
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
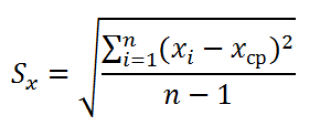
где Sey – стандартная ошибка регрессии, т.е. ошибка предсказания значения переменой Y ( см. выше ).
В MS EXCEL стандартную ошибку коэффициента регрессии Se можно вычислить впрямую по вышеуказанной формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции ЛИНЕЙН() :
Формулы приведены в файле примера на листе Линейный в разделе Регрессионная статистика .
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
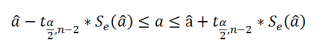
где — квантиль распределения Стьюдента с n-2 степенями свободы. Величина а с «крышкой» является другим обозначением наклона а .
Например для уровня значимости альфа=0,05, можно вычислить с помощью формулы =СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
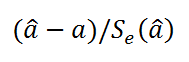
является t-распределением Стьюдента с n-2 степенью свободы (то же справедливо и для наклона b ).
Примечание : Подробнее о построении доверительных интервалов в MS EXCEL можно прочитать в этой статье Доверительные интервалы в MS EXCEL .
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии. Здесь мы считаем, что коэффициент регрессии a имеет распределение Стьюдента с n-2 степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Примечание : Подробнее о построении доверительных интервалов с использованием t-распределения см. статью про построение доверительных интервалов для среднего .
Стандартная ошибка сдвига b вычисляется по следующей формуле:
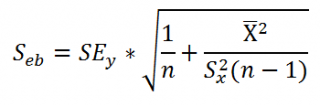
В MS EXCEL стандартную ошибку сдвига Seb можно вычислить с помощью функции ЛИНЕЙН() :
При построении двухстороннего доверительного интервала для сдвига его границы определяются аналогичным образом как для наклона : b +/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда коэффициент регрессии a равен 0.
Чтобы убедиться, что вычисленная нами оценка наклона прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы Н 1 принимают, что a 0.
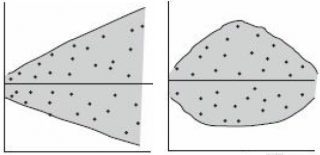
Ниже на рисунках показаны 2 ситуации, когда нулевую гипотезу Н 0 не удается отвергнуть.
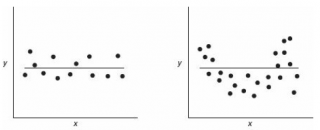
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом коэффициент линейной корреляции равен 0.
Ниже — 2 ситуации, когда нулевая гипотеза Н 0 отвергается.
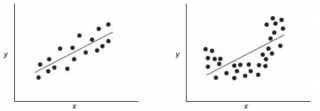
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
- Установить уровень значимости , пусть альфа=0,05;
- Рассчитать с помощью функции ЛИНЕЙН() стандартное отклонение Se для коэффициента регрессии (см. предыдущий раздел );
- Рассчитать число степеней свободы: DF=n-2 или по формуле = ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
- Вычислить значение тестовой статистики t 0 =a/S e , которая имеет распределение Стьюдента с числом степеней свободы DF=n-2;
- Сравнить значение тестовой статистики |t0| с пороговым значением t альфа ,n-2. Если значение тестовой статистики больше порогового значения, то нулевая гипотеза отвергается ( наклон не может быть объяснен лишь случайностью при заданном уровне альфа) либо
- вычислить p-значение и сравнить его с уровнем значимости .
В файле примера приведен пример проверки гипотезы:
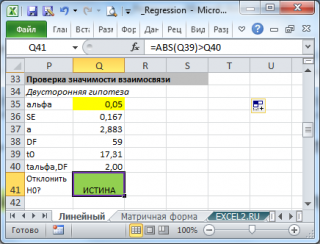
Изменяя наклон тренда k (ячейка В8 ) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание : Проверка значимости взаимосвязи эквивалентна проверке статистической значимости коэффициента корреляции . В файле примера показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью процедуры F-тест .
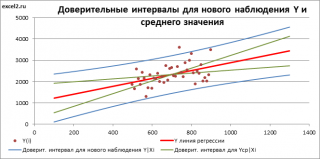
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры простой линейной регрессионной модели Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ= a * Хi + b
Ŷ также является точечной оценкой для среднего значения Yi при заданном Хi. Но, при построении доверительных интервалов используются различные стандартные ошибки .
Стандартная ошибка нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
- неопределенность связанную со случайностью оценок параметров модели a и b ;
- случайность ошибки модели ε.
Учет этих неопределенностей приводит к стандартной ошибке S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
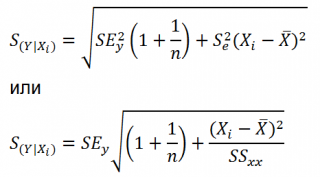
где SS xx – сумма квадратов отклонений от среднего значений переменной Х:
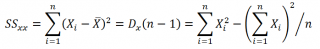
В MS EXCEL 2010 нет функции, которая бы рассчитывала эту стандартную ошибку , поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал или Интервал предсказания для нового наблюдения (Prediction Interval for a New Observation) построим по схеме показанной в разделе Проверка значимости взаимосвязи переменных (см. файл примера лист Интервалы ). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х ср ), то интервал будет постепенно расширяться при удалении от Х ср .
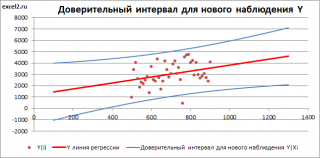
Границы доверительного интервала для нового наблюдения рассчитываются по формуле:
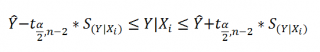
Аналогичным образом построим доверительный интервал для среднего значения Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае доверительный интервал будет уже, т.к. средние значения имеют меньшую изменчивость по сравнению с отдельными наблюдениями ( средние значения, в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
Стандартная ошибка S(Yср|Xi) вычисляется по практически аналогичным формулам как и стандартная ошибка для нового наблюдения:
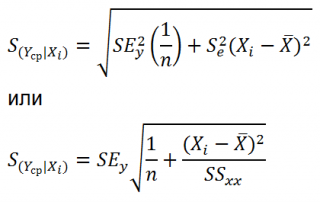
Как видно из формул, стандартная ошибка S(Yср|Xi) меньше стандартной ошибки S(Y|Xi) для индивидуального значения .
Границы доверительного интервала для среднего значения рассчитываются по формуле:
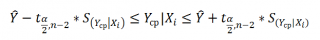
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел Предположения линейной регрессионной модели ).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках простой линейной модели n остатков имеют только n-2 связанных с ними степеней свободы . Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о нормальности распределения ошибок строят график проверки на нормальность (Normal probability Plot).
В файле примера на листе Адекватность построен график проверки на нормальность . В случае нормального распределения значения остатков должны быть близки к прямой линии.
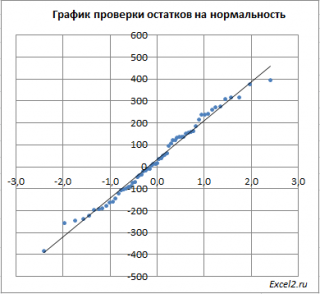
Так как значения переменной Y мы генерировали с помощью тренда , вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
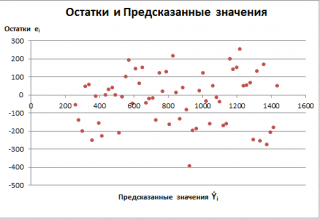
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор о нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе Стандартная ошибка регрессии оценкой стандартного отклонения ошибок является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
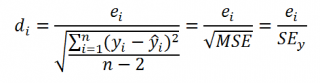
SEy можно вычислить с помощью функции ЛИНЕЙН() :
Иногда нормирование остатков производится на величину стандартного отклонения остатков (это мы увидим в статье об инструменте Регрессия , доступного в надстройке MS EXCEL Пакет анализа ), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
Линейная регрессия в машинном обучении
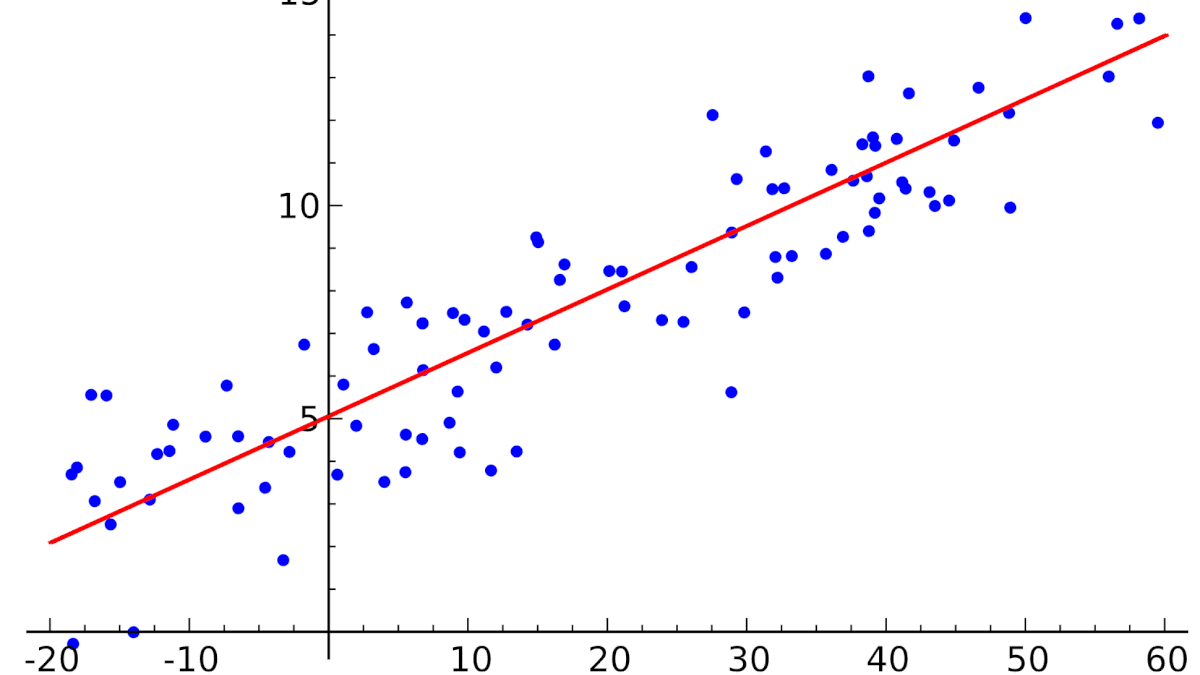
Линейная регрессия ( Linear regression ) — модель зависимости переменной x от одной или нескольких других переменных (факторов, регрессоров, независимых переменных) с линейной функцией зависимости.
Линейная регрессия относится к задаче определения «линии наилучшего соответствия» через набор точек данных и стала прос тым предшественником нелинейных методов, которые используют для обучения нейронных сетей. В этой статье покажем вам примеры линейной регрессии.
Применение линейной регрессии
Предположим, нам задан набор из 7 точек (таблица ниже).
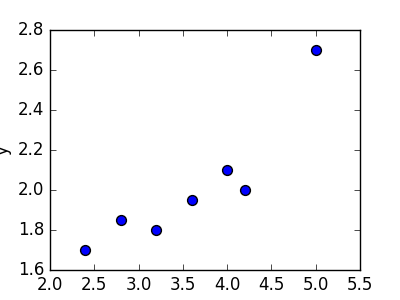
Цель линейной регрессии — поиск линии, которая наилучшим образом соответствует этим точкам. Напомним, что общее уравнение для прямой есть f (x) = m⋅x + b, где m — наклон линии, а b — его y-сдвиг. Таким образом, решение линейной регрессии определяет значения для m и b, так что f (x) приближается как можно ближе к y. Попробуем несколько случайных кандидатов:
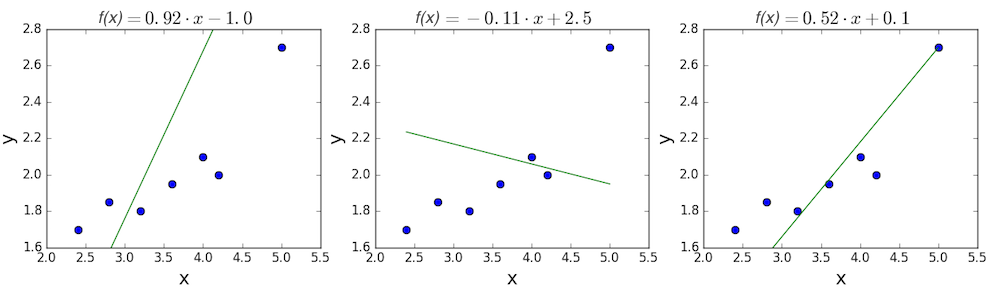
Довольно очевидно, что первые две линии не соответствуют нашим данным. Третья, похоже, лучше, чем две другие. Но как мы можем это проверить? Формально нам нужно выразить, насколько хорошо подходит линия, и мы можем это сделать, определив функцию потерь.
Функция потерь — метод наименьших квадратов
Функция потерь — это мера количества ошибок, которые наша линейная регрессия делает на наборе данных. Хотя есть разные функции потерь, все они вычисляют расстояние между предсказанным значением y( х) и его фактическим значением. Например, взяв строку из среднего примера выше, f(x)=−0.11⋅x+2.5, мы выделяем дистанцию ошибки между фактическими и прогнозируемыми значениями красными пунктирными линиями.
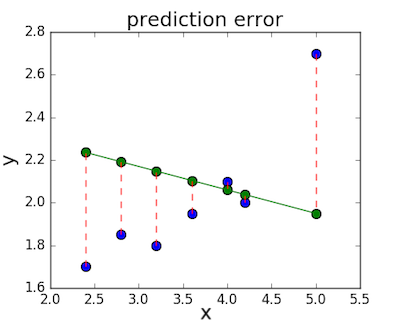
Одна очень распространенная функция потерь называется средней квадратичной ошибкой (MSE). Чтобы вычислить MSE, мы просто берем все значения ошибок, считаем их квадраты длин и усредняем.
Вычислим MSE для каждой из трех функций выше: первая функция дает MSE 0,17, вторая — 0,08, а третья — 0,02. Неудивительно, что третья функция имеет самую низкую MSE, подтверждая нашу догадку, что это линия наилучшего соответствия.
Рассмотрим приведенный ниже рисунок, который использует две визуализации средней квадратичной ошибки в диапазоне, где наклон m находится между -2 и 4, а b между -6 и 8.
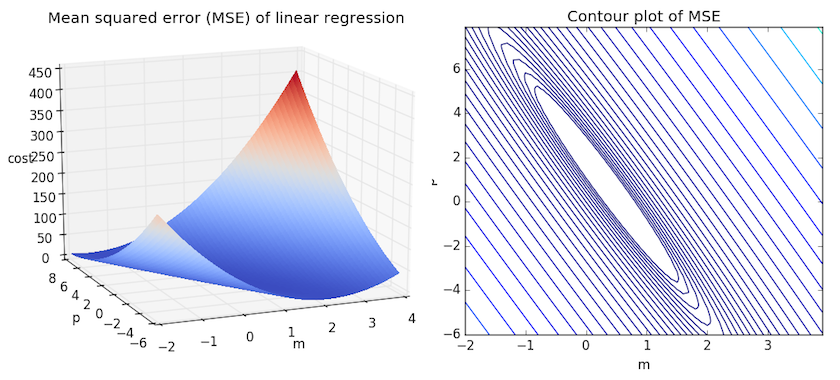 Слева: диаграмма, изображающая среднеквадратичную ошибку для -2≤m≤4, -6≤p≤8 Справа: тот же рисунок, но визуализирован как контурный график, где контурные линии являются логарифмически распределенными поперечными сечениями высоты.
Слева: диаграмма, изображающая среднеквадратичную ошибку для -2≤m≤4, -6≤p≤8 Справа: тот же рисунок, но визуализирован как контурный график, где контурные линии являются логарифмически распределенными поперечными сечениями высоты.
Глядя на два графика, мы видим, что наш MSE имеет форму удлиненной чаши, которая, по-видимому, сглаживается в овале, грубо центрированном по окрестности (m, p) ≈ (0.5, 1.0). Есл и мы построим MSE линейной регрессии для другого датасета, то получим аналогичную форму. Поскольку мы пытаемся минимизировать MSE, наша цель — выяснить, где находится самая низкая точка в чаше.
Больше размерностей
Вышеприведенный пример очень простой, он имеет только одну независимую переменную x и два параметра m и b. Что происходит, когда имеется больше переменных? В общем случае, если есть n переменных, их линейная функция может быть записана как:
Один трюк, который применяют, чтобы упростить это — думать о нашем смещении «b», как о еще одном весе, который всегда умножается на «фиктивное» входное значение 1. Другими словами:
Добавление измерений, на первый взгляд, ужасное усложнение проблемы, но оказывается, постановка задачи остается в точности одинаковой в 2, 3 или в любом количестве измерений. Существует функция потерь, которая выглядит как чаша — гипер-чаша! И, как и прежде, наша цель — найти самую нижнюю часть этой чаши, объективно наименьшее значение, которое функция потерь может иметь в отношении выбора параметров и набора данных.
Итак, как мы вычисляем, где именно эта точка на дне? Распространенный подход — обычный метод наименьших квадратов, который решает его аналитически. Когда есть только один или два параметра для решения, это может быть сделано вручную, и его обычно преподают во вводном курсе по статистике или линейной алгебре.
Проклятие нелинейности
Увы, обычный МНК не используют для оптимизации нейронных сетей, поэтому решение линейной регрессии будет оставлено как упражнение, оставленное читателю. Причина, по которой линейную регрессию не используют, заключается в том, что нейронные сети нелинейны.
Различие между линейными уравнениями, которые мы составили, и нейронной сетью — функция активации (например, сигмоида, tanh, ReLU или других).
Эта нелинейность означает, что параметры не действуют независимо друг от друга, влияя на форму функции потерь. Вместо того, чтобы иметь форму чаши, функция потерь нейронной сети более сложна. Она ухабиста и полна холмов и впадин. Свойство быть «чашеобразной» называется выпуклостью, и это ценное свойство в многопараметрической оптимизации. Выпуклая функция потерь гарантирует, что у нас есть глобальный минимум (нижняя часть чаши), и что все дороги под гору ведут к нему.
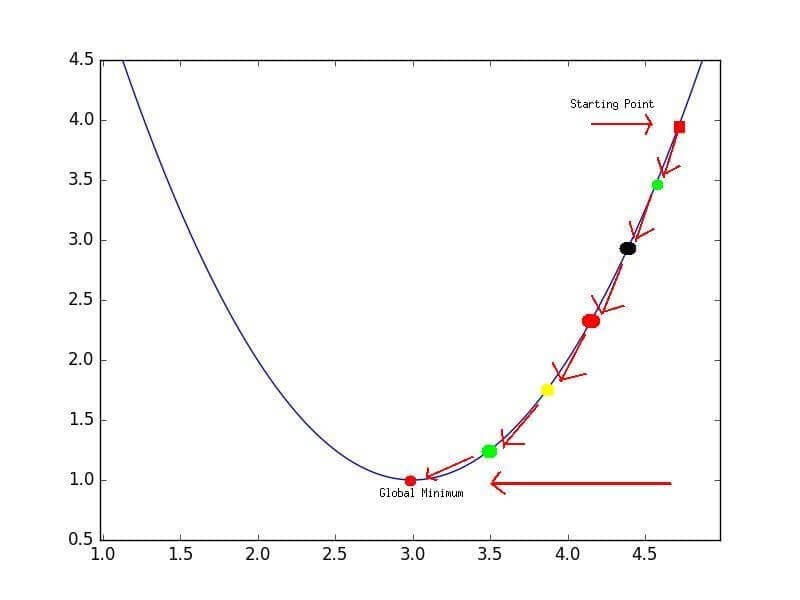 Минимум функции
Минимум функции
Но, вводя нелинейность, мы теряем это удобство ради того, чтобы дать нейронным сетям гораздо большую «гибкость» при моделировании произвольных функций. Цена, которую мы платим, заключается в том, что больше нет простого способа найти минимум за один шаг аналитически. В этом случае мы вынуждены использовать многошаговый численный метод, чтобы прийти к решению. Хотя существует несколько альтернативных подходов, градиентный спуск остается самым популярным методом.
Метод Уэлфорда и одномерная линейная регрессия
Одномерная линейная регрессия — один из самых простых регрессионных методов (и вообще один из самых простых методов машинного обучения), который позволяет описывать линейную зависимость наблюдаемой величины от одного из признаков. В общем случае в задачах машинного обучения приходится сталкиваться с большим количеством различных признаков; одномерная линейная регрессия в таком случае выбирает тот из них, который позволяет добиться наилучшей корреляции с целевой функцией.
В предыдущем посте из этой серии мы обсудили точность вычислений средних и ковариаций, а также познакомились с методом Уэлфорда, который во многих случаях позволяет избежать вычислительных погрешностей в этих задачах. Сегодня мы рассмотрим практическое применение метода Уэлфорда в задаче одномерной линейной регрессии.

Содержание
1. Одномерная линейная регрессия
В задаче одномерной линейной регрессии мы предполагаем, что имеются две последовательности вещественных чисел: признаки  и ответы
и ответы  . Кроме того, имеется вектор соответствующих весов
. Кроме того, имеется вектор соответствующих весов  . Как и всегда, мы будем предполагать, что эти последовательности содержат потенциально бесконечное количество элементов, но на данный момент рассмотрены только
. Как и всегда, мы будем предполагать, что эти последовательности содержат потенциально бесконечное количество элементов, но на данный момент рассмотрены только  первых элементов каждой из последовательностей.
первых элементов каждой из последовательностей.
Нашей задачей будет восстановить линейную зависимость между признаками и ответами, то есть, построить линейную решающую функцию  :
:

При этом минимизируется среднеквадратичный функционал потерь:

Для анализа проще работать с формулой, свободной от радикала и нормировки:

Поскольку точки минимума для функционалов  и
и  совпадают, такая замена корректна.
совпадают, такая замена корректна.
2. Решение для центрированных выборок
Для функционала потерь легко записать производные по  и
и  :
:


Если приравнять их к нулю, получим:



Важное отступление. Приравнивание производной нулю в данном случае корректно, т.к.:
1. Функционал потерь является выпуклым по оптимизируемым параметрам, поэтому любая точка локального оптимума будет также точкой глобального оптимума.
2. Функционал потерь по оптимизируемым параметрам представляет собой параболу, поэтому найденные экстремальные точки будут точками минимума.
Если бы оптимальный параметр равнялся нулю, найти решение не составило бы труда. Можно заметить, что центрирование, стандартный для машинного обучения способ предобработки выборки, приводит именно к этому эффекту. Действительно, рассмотрим задачу для центрированных переменных:


Сумма взвешенных признаков теперь равняется нулю, так же, как и сумма взвешенных ответов:


Тогда оптимальное значение свободного параметра равняется нулю:

А это значит, что и оптимальное значение параметра  найти легко:
найти легко:

3. Решение в общем случае
Теперь давайте попробуем вернуться к общему случаю нецентрированных данных. Если  — решающая функция для центрированного случая, значения которой определяются формулой
— решающая функция для центрированного случая, значения которой определяются формулой

и приближают величину  , то следующая решающая функция аппроксимирует уже величину
, то следующая решающая функция аппроксимирует уже величину  :
:

Поэтому решение изначальной задачи одномерной линейной регрессии можно записать следующим образом:


Здесь мы используем введенное в прошлой статье обозначение для взвешенного среднего:


Можно понять, что такой переход корректен, еще одним способом. Если решение для центрированных данных оптимально, то параметры и  доставляют минимум функционалу потерь :
доставляют минимум функционалу потерь :

Произведём теперь замену переменных, вернувшись к нецентрированным данным:


Получившееся выражение описывает значение функционала потерь для несмещённых данных в соответствии с формулами для и , которые мы получили выше. Значение функционала при этом достигает минимума, следовательно, задача решена корректно!
4. Применение метода Уэлфорда
Теперь заметим, что при вычислении параметра используются те самые ковариации, вычислением которых мы занимались в предыдущей статье. В самом деле, используя обозначения из неё, можно записать:

Это значит, что для вычисления коэффициента регрессии требуется два раза вычислить ковариации при помощи метода Уэлфорда. В процессе этих вычислений мы одновременно найдём и средние величины, необходимые для вычисления свободного коэффициента регрессии.
Код для добавления очередного элемента в выборку состоит из обновления средних и дисперсий для признаков и ответов, а также ковариации между признаками и ответами:
Величина GoalsDeviation здесь не используется, но она потребуется нам в дальнейших статьях.
Объединение всех вычислений в рамках одного класса позволяет избежать некоторых накладных расходов. Скажем, если бы в реализации использовались два объекта для хранения средних и три объекта для хранения ковариаций (признаки с признаками, ответы с ответами, признаки с ответами), то сумма весов обновлялась бы пять раз для каждого примера из выборки.
5. Экспериментальное сравнение методов
Для практического сравнения я написал программу, в которой реализуются различные способы решения задач одномерной и многомерной линейной регрессии. О многомерной регрессии речь пойдёт в следующих статьях, а сейчас сосредоточимся на одномерном случае.
Сравнивать будем, как обычно, «наивные» методы, методы, основанные на суммировании методом Кэхэна, и методы, основанные на методе Уэлфорда.
Класс является шаблонным и имеет специализации со счетчиками типа double и типа TKahanAccumulator.
Кроме того, реализован класс TTypedBestSLRSolver , который выбирает лучший из признаков для построения одномерной регрессионной модели. Делается это очень просто: задача одномерной линейной регрессии решается для каждого из признаков, а затем выбирается лучшая из получившихся моделей.
Для проверки разработанных методов воспользуемся модельными данными из коллекции LIAC. Некоторые из наборов данных для удобства помещены в директорию data в формате, который понимает написанная программа.
Данные в задачах «портятся» простым способом: значения признаков и ответов умножаются на некоторое число, после чего к ним прибавляется некоторое другое число. Таким образом мы можем получить проблемный с точки зрения вычислений случай: большие средние значения по сравнению с величинами разбросов.
В режиме research-bslr выборка изменяется несколько раз подряд, и каждый раз на ней запускается процедура скользящего контроля. Результатом проверки является среднее значение коэффициента детерминации для тестовых выборок.
Например, для выборки kin8nm результаты работы получаются следующими:
В данном случае уменьшение всех значений в выборке в 10 тысяч раз вместе с одновременным добавлением к ним величины в 10000 приводит к неработоспособности стандартного алгоритма, даже при использовании суммирования по методу Кэхэна. Аналогичные результаты получаются и на других выборках, в том числе и тех из них, что встречаются в реальной жизни в продакшене.
Заключение
Итак, сегодня мы поговорили о задаче одномерной линейной регрессии, разобрались с тем, как получаются аналитические решения в этой задаче и как использовать метод Уэлфорда для нахождения решений.
Метод Уэлфорда делает решение задачи существенно более устойчивым к возможным проблемам в данных. Однако, этот метод оказывается в 2-4 раза медленнее стандартного алгоритма, поэтому на практике нужно решить для себя, что в данный момент важнее — не зависеть от возможных проблем в данных или работать максимально быстро.
Если же есть необходимость много раз строить модели на различных данных и нет возможности контролировать качество каждой полученной модели, я бы рекомендовал использовать метод Уэлфорда.
В следующей статье мы поговорим о применении метода Уэлфорда для решения задачи многомерной линейной регрессии.
Линейный многомерный регрессионный анализ
Пример 4 Коммерческий агент рассматривает возможность закупки зданий под офисы. Агент может использовать множественный регрессионный анализ для оценки цены здания под офис на основе следующих переменных:
y-оценочная цена здания под офис;
x1-общая площадь в квадратных метрах;
x4-время эксплуатации здания в годах.
Агент наугад выбирает 11 зданий из имеющихся 1500 и получает следующие данные (табл. 6).
«Пол-входа» означает вход только для доставки корреспонденции.
В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (x1,x2,x3,x4) и зависимой переменной (y) ,т.е. ценой здания под офис в данном районе.
Для многомерного регрессионного анализа выполним следующие операции:
| A | B | C | D | E |
| х1 -площадь, м 2 | х2 -офисы | х3 — входы | х4— срок, лет | Цена, у.е. |
| 1.5 | ||||
| 1.5 |
§ выделим блок ячеек А14:Е18 (в соответствии с табл. 6),
§ нажмём клавиши Ctrl+Shift+Enter,
§ в выделенных ячейках появится результат:
Продолжение табл. 6
| A | B | C | D | E |
| -234.237 | 2553.210 | 12529.7682 | 27.6413 | 52317.830 |
| 13.2680 | 530.66915 | 400.066838 | 5.42937 | 12237.361 |
| 0.99674 | 970.57846 | #H/Д | #H/Д | #H/Д |
| 459.753 | #H/Д | #H/Д | #H/Д | |
| 5652135.3 | #H/Д | #H/Д | #H/Д |
Уравнение множественной регрессии y=ml∙xl+m2∙x2+m3∙x3+m4∙x4+b теперь может быть получено из строки 14:
y=27,64∙x1+12530∙x2+2553∙x3-234,24∙x4+52318 (14)
Теперь агент может определить оценочную стоимость здания под офис в том же районе, которое имеет площадь 2500 кв. м , три офиса, два входа, зданию 25 лет, используя следующее уравнение:
Это значение может быть вычислено с помощью функции ТЕНДЕНЦИЯ:
При интерполировании с помощью функции
для получения уравнения множественной экспоненциальной регрессии выводится результат (табл. 7):
| 0,99835752 | 1,0173792 | 1,0830186 | 1,0001704 | 81510,335 |
| 0,00014837 | 0,0065041 | 0,0048724 | 6,033E-05 | 0,1365601 |
| 0,99158875 | 0,0105158 | #Н/Д | #Н/Д | #Н/Д |
| 176,832548 | #Н/Д | #Н/Д | #Н/Д | |
| 0,07821851 | 0,0006635 | #Н/Д | #Н/Д | #Н/Д |
| #Н/Д | #Н/Д | #Н/Д | #Н/Д | #Н/Д |
Коэффициент детерминированности здесь составляет 0,992 (99,2%), т.е. меньше, чем при линейной интерполяции, поэтому в качестве основного следует оставить уравнение множественной регрессии (14).
Таким образом, функции ЛИНЕЙН, ЛГРФПРИБЛ, НАКЛОН определяют коэффициенты , свободные члены и статистические параметры для уравнений одномерной и множественной регрессии, а функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ позволяют получить прогноз новых значений без составления уравнения регрессии по значениям тренда.
Контрольные вопросы
1 Сущность регрессионного анализа, его использование для прогнозирования функций.
2 Как получить уравнение одномерной линейной регрессии, каков синтаксис функций линейного приближения?
3 Как получить уравнение многомерной линейной регрессии, каков синтаксис функции?
4 Как получить уравнение одномерной экспоненциальной регрессии, каков синтаксис функции экспоненциального приближения?
5 Как получить уравнение многомерной экспоненциальной регрессии, каков синтаксис функции экспоненциального приближения?
6 Что выполняют функции ЛИНЕЙН, ТЕНДЕНЦИЯ, РОСТ, ЛГРФПРИБЛ, ПРЕДСКАЗ?
7 Каковы правила ввода и использования табличных формул?
8 Как на гистограмме исходных данных добавить линию тренда?
9 Как с помощью линии тренда отобразить прогнозируемые величины?
Задание
Вариант задания к данной лабораторной работе включает две задачи. Для каждой из них необходимо составить и определить:
1 Таблицу исходных данных, а также значений, полученных методами линейной и экспоненциальной регрессии.
2 Коэффициенты в уравнениях прямой и экспоненциальной кривой (функции ЛИНЕЙН и ЛГРФПРИБЛ), напишите уравнения прямой и экспоненциальной кривой для простой и множественной регрессии..
3 Погрешности (ошибки) прямой и экспоненциальной кривой. вычислений для коэффициентов и функций, коэффициенты детерминированности. Оценить, какой тип регрессии наилучшим образом подходит для вашего варианта задания.
4 Прогноз изменения данных, выполненный с использованием линейной и экспоненциальной регрессии (функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ).
5 Построить гистограмму (или график) исходных данных для задачи 1 (одномерная регрессия), отобразить на ней линию тренда, а также соответствующее ей уравнение и коэффициент детерминированности.
Варианты заданий
(номер варианта соответствует номеру компьютера)
Вариант 1
1 На рынке наблюдается стойкое снижение цен на компьютеры. Сделать прогноз, сколько необходимо будет снизить цену на компьютеры в следующем месяце в Вашей фирме, чтобы как минимум сравнять ее с ценой на аналогичные компьютеры в конкурирующей фирме, если известна динамика изменения цен на них в конкурирующей фирме за последние 12 месяцев.
Для выполнения задания нужно ввести ряд из 12 ячеек с ценами конкурирующей фирмы , сделать прогноз цены на следующий месяц и др.(см. Задание).
2 Известна структура расходов фирмы на рекламу в газетах, на радио, в журналах, на телевидении, на наружную рекламу ( в процентах от общей суммы ), а также оборот фирмы в каждом за последние 6 месяцев. Какой оборот можно ожидать в следующем месяце, если предполагается следующая структура расходов на рекламу: газеты-40%, журналы-40%, радио-5%, телевидение-14%, наружная реклама-1%.
Для выполнения задания нужно составить таблицу со столбцами вида:
| Месяц | Х1 – газеты, % | Х2 –журналы, % | Х3 – радио, % | Х4 – телевид.,% | Х5 – наружн. рекл.% | Оборот, $. |
| Январь | ||||||
| . . . | . . . | . . . | . . . | . . . | . . . | . . . |
| Июнь |
и сделать множественный регрессионный прогноз .(см. Задание).
Вариант 2
1 Имеются данные о динамике продаж в расчете на душу населения по хлебобулочным продуктам и молочным изделиям, а также динамика изменения среднедушевого годового дохода за последние 10 лет. Для каждой группы товаров построить регрессионные модели, описывающие зависимость объемов продаж от размера доходов. Сделать прогноз об объемах продаж и размерах доходов на следующий год.
Для выполнение задания нужно составить таблицу вида:
| Годы | . . . | |||
| х1 – хлеб, кг | 0,5 | 26,7 | . . . | 42,8 |
| х2 –молоко, л | 0,45 | . . . | 39,5 | |
| у – доход, р. | . . . |
и получить два уравнения – у =f (x1) и у= f(х2) , сделать прогноз на следующий год для рядов х1, х2, у и др. (см. Задание).
2 Руководство фирмы провело оценку качеств пяти рекламных агентов по следующим признакам: х1— эрудиция, х2— энергичность, х3— умение работать с людьми, х4 — внешность, х5— знание предметной области. Полученные средние оценки, нормированные от 0 до 1, были сопоставлены с оценками эффективности деятельности агентов ( % успешных сделок от количества возможных). Определить, какую эффективность можно ожидать от рекламного агента, обладающего усредненными качествами. Сравнить ее со средней эффективностью упомянутых 5 агентов.
Исходные данные нужно ввести в таблицу вида:
| A | B | C | D | E | F | G | |
| х1-Эруд. | х2 -Энер | х3-Люди | х4-Вн. | х5-Зн. | Эф-ть | ||
| Агент 1 | 0,8 | 0,2 | 0,4 | 0,6 | 1,0 | 76% | |
| . | . . . | . . . | . . . | . . . | . . . | . . . | . . . |
| Агент 5 | 0,5 | 0,7 | 0,3 | 0,4 | 0,74 | 81% | |
| Средняя эффективность пяти агентов | |||||||
| Ср. агент | 0,5 | 0,5 | 0,5 | 0,5 | 0,5 |
Массив ячеек B2-F6 заполняется произвольными числами от 0 до 1,
столбец G2-G6 – процентами удачных сделок по принципу «Чем выше уровень качеств агента, тем выше эффективность его работы», в ячейке G7 должна быть формула для вычисления среднего значения содержимого ячеек G2-G6, в ячейке G8 нужно вычислить значение эффективности для среднего агента по формуле, полученной в результате множественного регрессионного анализа работы пяти агентов. Остальные пункты – см. Задание.
Вариант 3
1 Автомобильный салон имеет данные о количестве проданных автомобилей «Мерседес» и «БМВ» за последние 4 квартала. Учитывая тенденцию изменения объема продаж, определить, каких автомобилей необходимо закупить больше ( «Мерседес» или «БМВ» ) в следующем квартале?
Для выполнения задания нужно составить и заполнить таблицу вида
| 1 квар-л | 2 квар-л | 3 квар-л | 4 квар-л | Новый кв-л |
| Мерседес | ||||
| БМВ |
сделать прогноз продаж на новый квартал и выполнить другие пункты Задания.
2 Известны следующие данные о 5 недавно проданных подержанных автомобилях: х1 — стоимость продажи, х2 — стоимость аналогичного нового автомобиля, х3 — год выпуска, х4 — пробег, х5— кол-во капитальных ремонтов, х6— экспертные заключения о состоянии кузова и техническом состоянии автомобилей (по 10-бальной шкале ). Определить, сколько может стоить автомобиль с соответствующими характеристиками: 20 000 руб., 34 000 руб., 1990 г. , 140000 км. , 0, 6 – см. пример 4.
Вариант 4 1 Определить минимально необходимый тираж ежемесячного журнала » Speed-Info » и возможный доход от размещения в нем рекламы в следующем месяце, если известны данные об объемах продаж этого журнала и доходах от размещения рекламы за прошедшие 12 месяцев (считать, что расценки на рекламу не менялись ).
Для выполнения задания нужно составить таблицу вида
| Месяц | . . . |
| Тираж | . . . |
| Доход | . . . |
и заполнить ячейки за 12 месяцев условными данными. По этим данным нужно сделать линейный и экспоненциальный прогноз и др. (см. Задание).
2 В целях привлечения покупателей и увеличения оборота фирма проводит стратегию ежемесячного снижения цен на свой товар. На основании
данных о динамике изменения цен, объемов продаж в данной фирме и еще в 3 конкурирующих фирмах за последние 12 месяцев сделать прогноз о том, возрастет ли объем продаж у данной фирмы при очередном снижении цен в следующем месяце, если предположить, что цены и объемы у конкурентов в следующем месяце будут средние за рассматриваемый период.
Для выполнения задания нужно составить таблицу вида
| A | B | C | D | T | F | G | H | I | |
| мес | Фирма | Конкурент 1 | Конкурент 2 | Конкурент 3 | |||||
| У1— объём | Х1— цена | Х2— объём | Х3— цена | Х4— объём | Х5 -цена | Х6 -объём | Х7 -цена | ||
| . / / /. | . . . . / / /. | . / / /.. . . | . . . . / / /. | . . . . / / /. | . . . . / / /. | . / / /.. . . | . . / / /.. . | . . . / / /. . | . . / / /. . . |
Вариант 5
1 На основании данных о курсе американского доллара и евро в первом полугодии сделать прогноз о соотношении данных валют на второе полугодие. Во что будет выгоднее вкладывать деньги в конце года?
Для выполнения задания нужно составить таблицу вида
| Месяц | . . . | |||||
| Доллар | 24,.5 | 24,9 | 25,7 | 26,9 | 28,0 | 28,8 |
| Евро | 72,1 | 76,3 | 79,6 | 85,3 | 89,7 | 90,9 |
и сделать линейный прогнозы на следующие 6 месяцев и др.(см.Задание).
2 Известны данные за последние 6 месяцев о том, сколько раз выходила реклама фирмы, занимающейся недвижимостью, на телевидении – х1, радио – х2, в газетах и журналах – х3, а также количество звонков – у1 и количество совершенных сделок у2. Какое соотношение количества совершенных сделок к количеству звонков у (в %) можно ожидать в следующем месяце, если известно, сколько раз выйдет реклама в каждом из перечисленных средств массовой информации.
Для выполнения задания нужно составить и заполнить таблицу вида
| A | B | C | D | E | |
| х1 | х2 | х3 | y = y2/y1·100% | ||
| Январь | 78% | ||||
| . . | . . . | . . . | . . . | . . . | . . . |
| Июнь | 89% | ||||
| Июль |
и выполнить применительно к таблице пункты Задания.
Вариант 6
1 Для некоторого региона известен среднегодовой доход населения, а также данные о структуре расходов ( тыс. руб. в год ) за последние 5 лет по следующим статьям: питание – х1, жилье – х2, одежда – х3, здоровье – х4, транспорт –х5, отдых – х6, образование – х7. На основании известных данных провести анализ потребительского кредита ( или накопления ) в следующем году.
Для выполнения задания нужно составить таблицу вида
| Годы | х1 | х2 | х3 | х4 | х5 | х6 | х7 | Σхi | Доход | Кредит |
| 0,3 | 18,3 | 21,4 | 3,1 | |||||||
| . . . | . . | . . | . . | . . | . . . | . . | . . . | . . . | . | . |
| 1,2 | 6,5 | 24,7 | 26,2 | 1,5 |
В ячейках столбца Σхiдолжны быть записаны формулы, вычисляющие суммы всех расходов х1 + х2+. + х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбцаКредит –формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход — Σхi.. Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
2 Для 10 однокомнатных квартир, расположенных в одном районе, известны следующие данные: общая площадь — х1, жилая площадь – х2, площадь кухни – х3, наличие балкона – х4, телефона – х5, этаж – х6, а также стоимость – х7. Определить, сколько может стоить однокомнатная квартира в этом районе без балкона, без телефона, расположенная на 1-ом этаже, общей площадью 28 кв. м, жилой- 16 кв. м, с кухней 6 кв. м.
Вариант 7
1 Определить возможный прирост населения ( количество человек на 1000 населения ) в 2005 году, если известны данные о количестве родившихся и умерших на 1000 населения в 1991-2000 годах.
2 После некоторого спада наметился рост объемов продаж матричных
принтеров. Используя данные об объемах продаж, ценах на матричные, струйные и лазерные принтеры, а также на их расходные материалы за последние 6 месяцев, определить возможный спрос на матричные принтеры в следующем месяце. Проанализируйте, связано ли увеличение спроса на матричные принтеры с уменьшением спроса на струйные и лазерные.
Для выполнения задания нужно составить и заполнить таблицу вида
| Матричные принтеры | Струйные принтеры | Лазерные принтеры | |||||||
| Спрос у1 | Цена, x1 | Р.мат z1 | Спрос, y2 | Цена, x2 | Р.мат z2 | Спрос, y3 | Цена x3 | Р.мат. z3 | |
| . . | . . . | . . . | . . . | . . . | . . . | . . . | . . . | . . . | . . . |
сделать прогноз на седьмой месяц по уравнению у1= f(x1,z1), получить уравнение у1 = f(y2, x2, z2, y3, x3, z3) и проанализировать его. Если слагаемые y2 и y3 входят в регрессионное уравнение со знаком «-» , то уменьшение спросов y2 и y3 ведёт к увеличению спроса у1. Выполнить другие пункты Задания.
Вариант 8
1 Построить прогноз развития спроса населения региона на телевизоры, если известна динамика продаж телевизоров (тыс. шт. ) и динамика численности населения данного региона (тыс. чел. ) за последние 10 лет.
Для выполнения задания нужно составить таблицу из двух рядов (продаж телевизоров и численности населения по годам и сделать прогноз по обоим рядам на следующий год. Выполнить другие пункты Задания.
2 Размещая рекламу в 4-х изданиях, фирма собрала сведения о поступивших на нее откликов — у и сопоставила их с данными об изданиях: х1— стоимость издания, х2 — стоимость одного блока рекламы, х3 — тираж, х4 — объем аудитории, х5— периодичность, х6— наличие телепрограммы. Какое количество откликов можно ожидать на рекламу в издании со следующими характеристиками: 15000 руб. , 10$ , 1000 экз. , 25000 чел. , 4 раза в месяц , без телепрограммы.
Для выполнения задания нужно составить и заполнить таблицу вида
| Данные | Отклики-у | х1 | х2 | х3 | х4 | х5 | х6 |
| Издание 1 | |||||||
| . . . | . . . | . . . | . . . | . . . | . . . | . . . | . . . |
| Издание 4 | |||||||
| Прогноз |
сделать прогноз при заданных характеристиках и выполнить другие пункты Задания.
Вариант 9. 1 Размещая свою рекламу в двух печатных изданиях одновременно, фирма собрала сведения о количестве поступивших звонков и количестве совершенных сделок по объявлениям в каждом из указанных изданий за последние 12 месяцев. Определить, в каком из изданий и насколько эффективность размещения рекламы в следующем месяце будет больше?
Для выполнения задания нужно составить таблицу вида:
| Издание 1 | Издание 2 | |||
| Месяцы | Звонки | Сделки | Звонки | Сделки |
| . . . | . . . | . . . | . . . | . . . |
| 13 лин. | ||||
| 13-эксп. |
Эффективность определяется как сделки /звонки. Сделать линейный и экспоненциальный прогнозы по обоим изданиям, выполнить другие пункты Задания.
2 Пусть комплект мягкой мебели ( диван + 2 кресла ) характеризуется следующими признаками ( 1- есть, 0- нет ) : х1— деревянные подлокотники, х2— велюровое покрытие, х3 — кресло-кровать, х4 — угловой диван, х5— раскладывающийся диван, х6 — место для хранения белья. На основании данных о стоимости 5 комплектов мягкой мебели, для которых известны перечисленные признаки, сделать вывод о возможной стоимости комплекта с обычным раскладывающимся диваном , с местом для белья, без деревянных подлокотников, с обычными креслами.
Для выполнения задания нужно составить таблицу
| Признаки | х1 | х2 | х3 | х4 | х5 | х6 | у1 — стоимость |
| Комплект 1 | 12560 р. | ||||||
| . . . | . . . | . . . | . . . | . . . | . . . | . . . | . |
| Комплект 5 | 10980 р. | ||||||
| Прогноз |
сделать прогноз и выполнить другие пункты .
Вариант 10
1 Для двух радиостанций известны данные об изменении объема аудитории и динамике роста цен за 1 минуту эфирного времени за последние 12 месяцев. Определить, для какой радиостанции стоимость одного контакта со слушателем в следующем месяце будет меньше?
Для выполнения задания нужно составить и заполнить таблицу вида
| A | B | C | D | E | |
| Радиостанция 1 | Радиостанция 2 | ||||
| Месяц | Аудитория | Цена 1 мин. | Аудитория | Цена 1 мин. | |
| . | . | . | . | . | . |
| Прогноз | |||||
| Контакт |
В строке «Контакт» в ячейках С8 и D8 должны быть записаны формулы =С7/B7 и =E7/D7 соответственно, вычисляющие стоимость 1 мин. эфира для одного слушателя в прогнозируемом месяце. Прогноз нужно выполнить для линейного и экспоненциального приближений и выбрать более достоверный, а также сделать другие пункты Задания.
2 На основании данных ежемесячных исследований известна динамика рейтинга банка ( в условных единицах ) за последние 6 месяцев в следующих сферах:
а) менеджмент и технология – х1;
б) менеджеры и персонал – х2;
в) культура банковского обслуживания – х3;
г) имидж банка на рынке финансовых услуг – х4;
д) реклама банка – х5.
Определить возможное изменение количества вкладчиков данного банка в следующем месяце, если известны значения сфер рейтинга и количество вкладчиков в каждом из рассматриваемых 6 месяцев.
Для выполнения задания нужно составить и заполнить таблицу
| A | B | C | D | E | F | G | |
| Месяц | х1 | х2 | х3 | х4 | х5 | Кол-во вкладчиков | |
| . . | . . . | . . . | . . . | . . . | . . . | . . . | . . . |
| Прогноз |
и выполнить другие пункты Задания.
Содержание отчёта
1Название, цель, содержание работы
2 Письменные ответы на контрольные вопросы
3 Выводы по работе
На дискете должны быть сохранены результаты работы
В отчете по лабораторной работе должны быть записаны все выполненные пункты Задания (таблицы, уравнения, прогнозируемые значения, стандартные ошибки, коэффициенты детерминированности, графики или гистограммы с приближающими кривыми и линиями тренда и др.