Назначение сервиса . С помощью онлайн-калькулятора можно найти следующие показатели:
- уравнение множественной регрессии, матрица парных коэффициентов корреляции, средние коэффициенты эластичности для линейной регрессии;
- множественный коэффициент детерминации, доверительные интервалы для индивидуального и среднего значения результативного признака;
Кроме этого проводится проверка на автокорреляцию остатков и гетероскедастичность.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Отбор факторов обычно осуществляется в два этапа:
- теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
- количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции). Научно обоснованное решение задач подобного вида также осуществляется с помощью дисперсионного анализа — однофакторного, если проверяется существенность влияния того или иного фактора на рассматриваемый признак, или многофакторного в случае изучения влияния на него комбинации факторов.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
- Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
- Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
- Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность — тесная линейная связь между факторами.
Пример . Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели.
Решение.
К исходной матрице X добавим единичный столбец, получив новую матрицу X
| 1 | 5 | 14.5 |
| 1 | 12 | 18 |
| 1 | 6 | 12 |
| 1 | 7 | 13 |
| 1 | 8 | 14 |
Матрица Y
| 9 |
| 13 |
| 16 |
| 14 |
| 21 |
Транспонируем матрицу X, получаем X T :
| 1 | 1 | 1 | 1 | 1 |
| 5 | 12 | 6 | 7 | 8 |
| 14.5 | 18 | 12 | 13 | 14 |
| Умножаем матрицы, X T X = |
|
В матрице, (X T X) число 5, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
| Умножаем матрицы, X T Y = |
|
Находим обратную матрицу (X T X) -1
| 13.99 | 0.64 | -1.3 |
| 0.64 | 0.1 | -0.0988 |
| -1.3 | -0.0988 | 0.14 |
Вектор оценок коэффициентов регрессии равен
| (X T X) -1 X T Y = y(x) = |
| * |
| = |
|
Получили оценку уравнения регрессии: Y = 34.66 + 1.97X1-2.45X2
Оценка значимости уравнения множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю коэффициент детерминации рассчитанного по данным генеральной совокупности. Для ее проверки используют F-критерий Фишера.
R 2 = 1 — s 2 e/∑(yi — yср) 2 = 1 — 33.18/77.2 = 0.57
F = R 2 /(1 — R 2 )*(n — m -1)/m = 0.57/(1 — 0.57)*(5-2-1)/2 = 1.33
Табличное значение при степенях свободы k1 = 2 и k2 = n-m-1 = 5 — 2 -1 = 2, Fkp(2;2) = 19
Поскольку фактическое значение F = 1.33 Пример №2 . Приведены данные за 15 лет по темпам прироста заработной платы Y (%), производительности труда X1 (%), а также по уровню инфляции X2 (%).
| Год | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X1 | 3,5 | 2,8 | 6,3 | 4,5 | 3,1 | 1,5 | 7,6 | 6,7 | 4,2 | 2,7 | 4,5 | 3,5 | 5,0 | 2,3 | 2,8 |
| X2 | 4,5 | 3,0 | 3,1 | 3,8 | 3,8 | 1,1 | 2,3 | 3,6 | 7,5 | 8,0 | 3,9 | 4,7 | 6,1 | 6,9 | 3,5 |
| Y | 9,0 | 6,0 | 8,9 | 9,0 | 7,1 | 3,2 | 6,5 | 9,1 | 14,6 | 11,9 | 9,2 | 8,8 | 12,0 | 12,5 | 5,7 |
Решение. Подготовим данные для вставки из MS Excel (как транспонировать таблицу для сервиса см. Задание №2) .

Включаем в отчет: Проверка общего качества уравнения множественной регрессии (F-статистика. Критерий Фишера, Проверка на наличие автокорреляции),
После нажатия на кнопку Дале получаем готовое решение.
Уравнение регрессии (оценка уравнения регрессии):
Y = 0.2706 + 0.5257X1 + 1.4798X2
Скачать.
Качество построенного уравнения регрессии проверяется с помощью критерия Фишера (п. 6 отчета).
Пример №3 .
В таблице представлены данные о ВВП, объемах потребления и инвестициях некоторых стран.
| ВВП | 16331,97 | 16763,35 | 17492,22 | 18473,83 | 19187,64 | 20066,25 | 21281,78 | 22326,86 | 23125,90 |
| Потребление в текущих ценах | 771,92 | 814,28 | 735,60 | 788,54 | 853,62 | 900,39 | 999,55 | 1076,37 | 1117,51 |
| Инвестиции в текущих ценах | 176,64 | 173,15 | 151,96 | 171,62 | 192,26 | 198,71 | 227,17 | 259,07 | 259,85 |
Решение:
Для проверки полученных расчетов используем инструменты Microsoft Excel «Анализ данных» (см. пример).
Пример №4 . На основе данных, приведенных в Приложении и соответствующих Вашему варианту (таблица 2), требуется:
- Построить уравнение множественной регрессии. При этом признак-результат и один из факторов остаются теми же, что и в первом задании. Выберите дополнительно еще один фактор из приложения 1 (границы наблюдения должны совпадать с границами наблюдения признака-результата, соответствующего Вашему варианту). При выборе фактора нужно руководствоваться его экономическим содержанием или другими подходами. Пояснить смысл параметров уравнения.
- Рассчитать частные коэффициенты эластичности. Сделать вывод.
- Определить стандартизованные коэффициенты регрессии (b-коэффициенты). Сделать вывод.
- Определить парные и частные коэффициенты корреляции, а также множественный коэффициент корреляции; сделать выводы.
- Оценить значимость параметров уравнения регрессии с помощью t-критерия Стьюдента, а также значимость уравнения регрессии в целом с помощью общего F-критерия Фишера. Предложить окончательную модель (уравнение регрессии). Сделать выводы.
Решение. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 3.9 | 10 |
| 1 | 3.9 | 14 |
| 1 | 3.7 | 15 |
| 1 | 4 | 16 |
| 1 | 3.8 | 17 |
| 1 | 4.8 | 19 |
| 1 | 5.4 | 19 |
| 1 | 4.4 | 20 |
| 1 | 5.3 | 20 |
| 1 | 6.8 | 20 |
| 1 | 6 | 21 |
| 1 | 6.4 | 22 |
| 1 | 6.8 | 22 |
| 1 | 7.2 | 25 |
| 1 | 8 | 28 |
| 1 | 8.2 | 29 |
| 1 | 8.1 | 30 |
| 1 | 8.5 | 31 |
| 1 | 9.6 | 32 |
| 1 | 9 | 36 |
Матрица Y
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 8 |
| 8 |
| 8 |
| 10 |
| 9 |
| 11 |
| 9 |
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 14 |
| 14 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3.9 | 3.9 | 3.7 | 4 | 3.8 | 4.8 | 5.4 | 4.4 | 5.3 | 6.8 | 6 | 6.4 | 6.8 | 7.2 | 8 | 8.2 | 8.1 | 8.5 | 9.6 | 9 |
| 10 | 14 | 15 | 16 | 17 | 19 | 19 | 20 | 20 | 20 | 21 | 22 | 22 | 25 | 28 | 29 | 30 | 31 | 32 | 36 |
Умножаем матрицы, (X T X)
Умножаем матрицы, (X T Y)
Находим определитель det(X T X) T = 139940.08
Находим обратную матрицу (X T X) -1
Уравнение регрессии
Y = 1.8353 + 0.9459X 1 + 0.0856X 2
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s
| 0.62 |
| 0.28 |
| 0.38 |
| 0.01 |
| 0.11 |
| -1 |
| -0.57 |
| 0.29 |
| -0.56 |
| 0.02 |
| -0.31 |
| 1.23 |
| -1.15 |
| 0.21 |
| 0.2 |
| -0.07 |
| -0.07 |
| -0.53 |
| 0.34 |
| 0.57 |
se 2 = (Y — X*s) T (Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(X T X) -1
| k(x) = 0.36 |
| = |
|
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X сильная
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции — последовательно берутся пары yx1,yx2. , x1x2, x1x3.. и так далее и для каждой пары находится коэффициент корреляции
Коэффициент детерминации
R 2 = 0.97 2 = 0.95, т.е. в 95% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл: Tтабл (n-m-1;a) = (17;0.05) = 1.74
Поскольку Tнабл Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
- Построение парной регрессионной модели
- Построение модели множественной регрессии
- Множественная линейная регрессия. Улучшение модели регрессии
- Понятие множественной линейной регрессии
- Уравнение множественной линейной регрессии и метод наименьших квадратов
- МНК-оценка коэффиентов уравнения множественной регрессии в скалярном виде
- МНК-оценка коэффиентов уравнения множественной регрессии в матричном виде
- Построение наилучшей (наиболее качественной) модели множественной линейной регрессии
- Оценка качества модели множественной линейной регрессии в целом
- Анализ значимости коэффициентов модели множественной линейной регрессии
- Исключение резко выделяющихся наблюдений
- Исключение незначимых переменных из модели
- Нелинейные модели для сравнения
- Применение пошаговых алгоритмов включения и исключения переменных
- Выбор самой качественной модели множественной линейной регрессии
Построение парной регрессионной модели
Рекомендации к решению контрольной работы.
Статистические данные по экономике можно получить на странице Россия в цифрах.
После определения зависимой и объясняющих переменных можно воспользоваться сервисом Множественная регрессия. Регрессионную модель с 2-мя объясняющими переменными можно построить используя матричный метод нахождения параметров уравнения регрессии или метод Крамера для нахождения параметров уравнения регрессии.
Пример №3 . Исследуется зависимость размера дивидендов y акций группы компаний от доходности акций x1, дохода компании x2 и объема инвестиций в расширение и модернизацию производства x3. Исходные данные представлены выборкой объема n=50.
Тема I. Парная линейная регрессия
Постройте парные линейные регрессии — зависимости признака y от факторов x1, x2, x3 взятых по отдельности. Для каждой объясняющей переменной:
- Постройте диаграмму рассеяния (поле корреляции). При построении выберите тип диаграммы «Точечная» (без отрезков, соединяющих точки).
- Вычислите коэффициенты уравнения выборочной парной линейной регрессии (для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические») или надстройкой Пакет Анализа), коэффициент детерминации, коэффициент корреляции (функция КОРЕЛЛ), среднюю ошибку аппроксимации
 .
. - Запишите полученное уравнение выборочной регрессии. Дайте интерпретацию найденным в предыдущем пункте значениям.
- Постройте на поле корреляции прямую линию выборочной регрессии по точкам .
- Постройте диаграмму остатков.
- Проверьте статистическую значимость коэффициентов регрессии по критерию Стьюдента (табличное значение определите с помощью функции СТЬЮДРАСПОБР) и всего уравнения в целом по критерию Фишера (табличное значение Fтабл определите с помощью функции FРАСПОБР).
- Постройте доверительные интервалы для коэффициентов регрессии. Дайте им интерпретацию.
- Постройте прогноз для значения фактора, на 50% превышающего его среднее значение.
- Постройте доверительный интервал прогноза. Дайте ему экономическую интерпретацию.
- Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемого фактора на показатель.
Тема II. Множественная линейная регрессия
1. Постройте выборочную множественную линейную регрессию показателя на все указанные факторы. Запишите полученное уравнение, дайте ему экономическую интерпретацию.
2. Определите коэффициент детерминации, дайте ему интерпретацию. Вычислите среднюю абсолютную ошибку аппроксимации и дайте ей интерпретацию.
3. Проверьте статистическую значимость каждого из коэффициентов и всего уравнения в целом.
4. Постройте диаграмму остатков.
5. Постройте доверительные интервалы коэффициентов. Для статистически значимых коэффициентов дайте интерпретации доверительных интервалов.
6. Постройте точечный прогноз значения показателя y при значениях факторов, на 50% превышающих их средние значения.
7. Постройте доверительный интервал прогноза, дайте ему экономическую интерпретацию.
8. Постройте матрицу коэффициентов выборочной корреляции между показателем и факторами. Сделайте вывод о наличии проблемы мультиколлинеарности.
9. Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемых факторов на показатель.
Построение модели множественной регрессии
Исследуя модели простой и множественной регрессии, предполагалось, что зависимость между откликом Y и каждой из объясняющих переменных является линейной. Однако существуют и другие виды взаимосвязи. Одной из наиболее распространенных нелинейных взаимосвязей между двумя переменными является квадратичная зависимость. Для ее анализа предназначена модель квадратичной регрессии. [1]
Материал будет проиллюстрирован сквозным примером: прогнозирование продолжительности простоя художников, входящих в профсоюз. Представьте себе, что вы — директор телевизионной станции и стремитесь сократить производственные расходы. В частности, художники, входящие в профсоюз, получают почасовую оплату, даже когда они ничего не делают. Эти часы называют часами простоя. Считается, что общее количество часов простоя за неделю зависит от общего количества времени, проведенного в офисе, общего количества часов, проведенных на выезде, времени, затраченного на озвучивание, и общей продолжительности работы. Постройте модель множественной регрессии, позволяющую наиболее точно предсказать количество часов простоя. Она позволит выявить причины возникающих простоев и уменьшить их количество в будущем. Как построить наиболее подходящую модель? С чего начать?
Модель квадратичной регрессии:

где β0 — сдвиг, β1 — коэффициент линейного эффекта, β2 — коэффициент квадратичного эффекта, εi – случайная ошибка переменной Y в i-ом наблюдении.
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Модель квадратичной регрессии похожа на модель множественной регрессии с двумя переменными, за исключением того, что вторая объясняющая переменная является квадратом первой. Как и в модели множественной регрессии, выборочные коэффициенты регрессии b0,b1 и b2 представляют собой оценки параметров генеральной совокупности β0, β1 и β2. Таким образом, можно сформулировать следующую квадратичную модель с одной объясняющей переменной Х1 и зависимой переменной Y (уравнение квадратичной регрессии):

где коэффициент b0 является сдвигом, коэффициент b1 оценивает линейный эффект, а коэффициент b2 — квадратичный эффект.
Вычисление коэффициентов регрессии и предсказание отклика. Проиллюстрируем применение квадратичной модели на примере эксперимента, в котором изучается влияние зольной пыли на прочность бетона. Для этого была создана выборка, состоящая из 18 образцов 28-дневного бетона, прочность которого равна 4000 фунтов на дюйм. Объем зольной пыли колебался от 0 до 60%. Уровень значимости α = 0,05 (рис. 1).
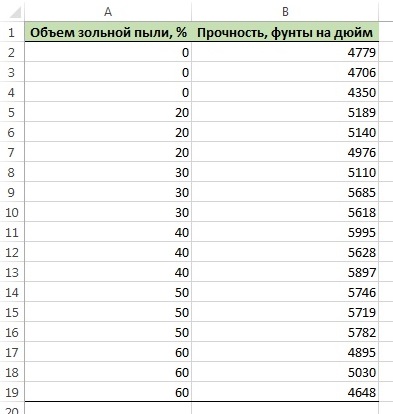
Рис. 1. Прочность 28-дневного бетона и содержание зольной пыли в 18 образцах
Для того чтобы выбрать наиболее подходящую модель, описывающую зависимость прочности бетона от процента зольной пыли, построим диаграмму разброса (рис. 2). Как видим, при возрастании процента зольной пыли прочность бетона увеличивается, достигает максимума при содержании зольной пыли, равном 40%, а затем уменьшается. Итак, квадратичная модель точнее описывает исследуемую зависимость, чем линейная.
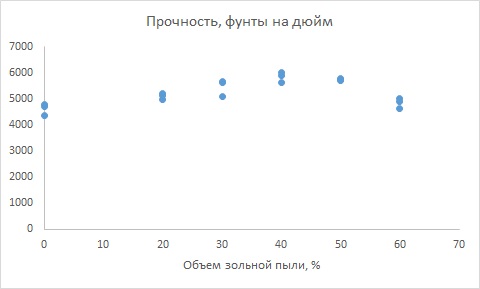
Рис. 2. Диаграмма разброса содержания зольной пыли (ось X) и прочности бетона (ось Y)
Значения трех коэффициентов регрессии (b0,b1 и b2) можно вычислить с помощью Пакета анализа Excel. Предварительно нужно создать еще одну колонку со значениями Х 2 (рис. 3).

Рис. 3. Результаты регрессионного анализа, полученные с помощью Пакета анализа Excel при решении задачи о прочности бетона
Уравнение квадратичной регрессии имеет следующий вид:

где  — предсказанная прочность i-го образца, Х1i — содержание зольной пыли в i-ом образце.
— предсказанная прочность i-го образца, Х1i — содержание зольной пыли в i-ом образце.
Для того чтобы продемонстрировать соответствие построенной модели исходным данным, на рис. 4 приведен график квадратичной зависимости прочности бетона от содержания зольной пыли. Для построения графика нужно вернуться к рис. 2, кликнуть правой кнопкой мыши на точках диаграммы, и выбрать Добавить линию тренда. В открывшемся окне выбрать параметр линии тренда Полиномиальная, степень 2, а также кликнуть Показывать уравнение на диаграмме.

Рис. 4. График квадратичной зависимости на диаграмме разброса содержания зольной пыли (ось X) и прочности бетона (ось Y)
Коэффициент b0, представляющий собой предсказанную среднюю прочность бетона при нулевом содержании зольной пыли, представляет собой сдвиг отклика и равен 4 486,361. Чтобы объяснить смысл коэффициентов b1 и b2, следует обратить внимание на рис. 4. Как видим, при увеличении содержания зольной пыли прочность бетона сначала увеличивается, а затем уменьшается. Этот эффект можно продемонстрировать, предсказав среднюю прочность бетона при содержании зольной пыли, равном 20, 40 и 60%. Используя квадратичную модель:

получаем следующие результаты (рис. 5):

Рис. 5. Предсказанная прочность бетона на основе квадратичной модели
Проверка значимости квадратичной модели. Убедившись, что квадратичная модель адекватна исходным данным, можно проверить, существует ли статистически значимая зависимость между прочностью бетона Y и содержанием зольной пыли X. Нулевая и альтернативная гипотезы формулируются следующим образом: Н0: β1 = β2 = 0 (между откликом Y и объясняющей переменной Х1 нет зависимости); Н1: β1 ≠ 0 и/или β2 ≠ 0 (между откликом Y и объясняющей переменной Х1 есть зависимость). Нулевую гипотезу можно проверить с помощью F-критерия:

(см. рис. 3, ячейки D31, D32, Е31)
Если уровень значимости α = 0,05, критическое значение F-распределения, имеющего две и 15 степеней свободы, =F.ОБР(0,95;2;15) = 3,682 (рис. 6). Поскольку F = 13,84 > FU = 3,68 и р =1-F.РАСП(E31;2;15;ИСТИНА) = 0,00039 2 = 0,6485. Эта величина означает, что 64,85% вариации прочности бетона можно объяснить квадратичной зависимостью между прочностью бетона и содержанием зольной пыли.
Преобразование данных в регрессионных моделях
Перейдем к изучению регрессионных моделей, в которых независимая переменная X, зависимая переменная Y или обе переменные подвергаются преобразованиям, чтобы преодолеть ограничения, наложенные на модель, либо для ее линеаризации. К наиболее распространенным преобразованиям относятся извлечение квадратного корня или логарифмирование.
Извлечение квадратного корня. Для преодоления ограничений, связанных со свойством гомоскедастичности, [2] а также для превращения нелинейной модели в линейную часто применяется извлечение квадратного корня. Если из объясняющей переменной извлекается квадратный корень, регрессионная модель принимает следующий вид:

Пример 1. Извлечение квадратного корня из переменной X (рис. 8а) превращает нелинейную зависимость (рис. 8б) в линейную (рис. 8в).

Рис. 8. Диаграммы разброса: (б) для исходных данных; (в) для квадратного корня из переменной X
Логарифмическое преобразование. Когда нарушается условие гомоскедастичности, кроме извлечения квадратного корня, часто применяется логарифмическое преобразование. Оно также позволяет превратить нелинейную модель в линейную. Чтобы не углубляться в сложные формулы, проиллюстрируем применение логарифмического преобразования на примере.
Пример 2. Диаграмма разброса (рис. 9а), демонстрирующая экспоненциальный рост исходных данных, может принять вид линейной путем преобразования зависимой и объясняющей переменных (рис. 9б). Удобнее всего это сделать простым выбором Логарифмической шкалы по обеим осям (рис. 9в). Иногда достаточно изменить только одну ось.

Рис. 9. Диаграммы разброса: (а) для исходных данных; (б) после логарифмического преобразования переменных X и Y; (в) показано, что преобразованы не исходные данные, а вид шкал на диаграмме
Коллинеарность
Применение модели множественной регрессии сопряжено с весьма важной проблемой — возможной коллинеарностью объясняющих переменных. Коллинеарными называют объясняющие переменные, значительно коррелирующие друг с другом. В этих ситуациях переменные не добавляют новой информации, поэтому их влияние на отклик трудно оценить. Это может привести к явной неустойчивости регрессионных коэффициентов, соответствующих коллинеарным переменным. Оценить коллинеарность можно, вычислив коэффициент инфляции (variance inflationary factor – VIF) для каждой объясняющей переменной. Коэффициент инфляции:

где Rj 2 — коэффициент множественной смешанной корреляции объясняющей переменной Xj со всеми другими объясняющими переменными.
Если модель содержит только две объясняющие переменные, величина R1 2 представляет собой коэффициент смешанной корреляции между переменными X1 и Х2. Он может совпадать с величиной R2 2 — коэффициентом смешанной корреляции между переменными Х2 и Х1. Если в модели содержатся три объясняющие переменные, то величина Rj 2 , где j = 1, 2, 3, представляет собой коэффициент множественной смешанной корреляции между переменной Xj и двумя другими объясняющими переменными.
Если объясняющие переменные не коррелируют друг с другом, коэффициент VIFj равен 1. Если объясняющие переменные сильно коррелируют друг с другом, VIFj может быть больше 10.
Модель множественной регрессии, в которой существуют большие коэффициенты инфляции, следует применять с крайней осторожностью. Эти модели позволяют предсказывать значения зависимой переменной только в том случае, если значения независимых переменных, подставляемые в модель, хорошо согласуются с данными, содержащимися в исходном наборе данных. Эти модели нельзя применять для экстраполяции отклика на значения независимых переменных, не содержащихся в исходной выборке. Кроме того, коэффициенты таких моделей не поддаются интерпретации, поскольку независимые переменные содержат перекрывающуюся информацию, а их индивидуальный вклад невозможно вычислить точно. Для решения этой проблемы следует исключить из регрессионной модели переменную, имеющую наибольший коэффициент инфляции. Довольно часто после этой операции сокращенная модель уже не содержит коллинеарных переменных.
Если вернуться к задаче о продажах батончиков OmniPower, рассмотренной ранее, окажется, что коэффициент корреляции между двумя объясняющими переменными (ценой и затратами на рекламу) равен –0,0968. Коэффициент инфляции этих переменных:

Таким образом, объясняющие переменные в задаче о продажах батончиков OmniPower не коллинеарны.
Построение модели множественной регрессии
Остановимся подробнее на процессе построения модели, содержащей несколько объясняющих переменных. Для начала вспомним о задаче, в которой для предсказания объема простоя на телевизионной станции были учтены четыре объясняющие переменные (продолжительность работы в офисе, количество часов, проведенных на выезде, время, затраченное на озвучивание, и общее количество рабочих часов в неделе). Попробуем предсказать количество часов простоя, используя данные, приведенные на рис. 10.

Рис. 10. Предсказание продолжительности простоя по количеству часов, проведенных в офисе, количеству часов, проведенных на выезде, количеству часов, затраченных на озвучивание, и общему количеству рабочих часов в неделе.
Прежде чем приступать к прогнозированию, необходимо учесть, что модель должна быть экономной. Это значит, что наша цель — разработать регрессионную модель, включающую в себя как можно меньше объясняющих переменных, позволяющих адекватно интерпретировать интересующий нас отклик. Регрессионная модель с минимальным количеством переменных намного проще других и меньше страдает от коллинеарности переменных. Кроме того, необходимо понимать, что модель с большим количеством объясняющих переменных порождает большие сложности при регрессионном анализе. Во-первых, оценка всех возможных регрессионных моделей становится крайне сложной вычислительной задачей. Во-вторых, даже если конкурентные модели удалось оценить, может оказаться, что единственной оптимальной модели не существует, а есть несколько одинаково хороших.
Начнем анализ простоев на телевизионной станции с оценки коллинеарности других объясняющих переменных, вычислив коэффициент инфляции (4) для каждой из них (рис. 11). Для этого необходимо исключить колонку Простой, а затем провести регрессионный анализ последовательно назначая в качестве зависимой переменной Присутствие, Отсутствие, Озвучивание и Всего, а в качестве объясняющих – три оставшиеся (подробнее см. Excel-файл).

Рис. 11. Анализ коллинеарности объясняющих переменных
Обратите внимание на то, что коэффициенты VIF относительно малы и колеблются от 1,23 для часов, проведенных на выезде, до 2,0 для общего количества рабочих часов. Таким образом, поскольку коэффициенты VIF не больше пяти, мы можем утверждать, что объясняющие переменные не коллинеарны.
Пошаговый подход к построению регрессионной модели. Продолжим анализ задачи о простоях и попробуем определить такой набор объясняющих переменных, который позволил бы построить адекватную и точную модель без необходимости учитывать все переменные. Одним из основных способов построения таких моделей является пошаговая регрессия, с помощью которой можно определить наилучшую регрессионную модель без перебора всех регрессионных моделей. После определения наилучшей модели для проверки проводится анализ остатков.
Напомним, что для оценки вклада переменных в модель множественной регрессии применяется F-критерий. В процессе шаговой регрессии F-критерий применяется к модели с любым количеством переменных. Важным свойством пошаговой процедуры является то, что объясняющие переменные, включенные в модель на предыдущих этапах, могут впоследствии исключаться из рассмотрения. Это значит, что на каждом этапе объясняющие переменные как включаются, так и исключаются из модели. Пошаговая регрессия останавливается, когда ни добавление, ни удаление объясняющих переменных не повышают точность модели.
При включении объясняющих переменных в модель и удалении их из нее уровень значимости α принимается равным 0,05. Начнем с попарного анализа, в котором зависимой переменной является Простой, а объясняющей переменной (единственной) последовательно: Присутствие, Отсутствие, Озвучивание и Всего (рис. 12). Видно, что наиболее сильно коррелирует с откликом Присутствие. Поскольку р-значение равно 0,001 и меньше 0,05, эта переменная включается в регрессионную модель.

Рис. 12. Анализ влияния первой объясняющей переменной на отклик
На следующем этапе в модель включается вторая объясняющая переменная. Она должна иметь наибольшее влияние на точность модели при условии, что первая объясняющая переменная (продолжительность работы в офисе) уже учтена. В данной задаче такой переменной оказалось количество часов, проведенных на выезде (рис. 13). Поскольку р-значение, соответствующее этой переменной, равно 0,027 и не больше 0,05, количество часов, проведенных на выезде (отсутствие), включается в модель.

Рис. 13. Анализ влияния второй объясняющей переменной при условии, что первая объясняющая переменная (Присутствие) уже учтена
Теперь необходимо определить, насколько велик вклад продолжительности работы в офисе и не следует ли исключить его из модели. Поскольку р-значение для этой переменной равно 0,0001, ее следует оставить в модели (см. Excel-файл).
На следующем этапе необходимо решить, стоит ли включать в модель третью переменную (рис. 14). Поскольку ни одна из оставшихся переменных не удовлетворяет F-критерию с 5%-ным уровнем значимости, в результате получаем регрессионную модель с двумя объясняющими переменными: продолжительностью работы в офисе (присутствие) и количеством часов, проведенных на выезде (отсутствие).

Рис. 14. Анализ влияния третьей объясняющей переменной при условии, что две объясняющие переменные (Присутствие и Отсутствие) уже учтены
Процедура пошаговой регрессии была предложена около тридцати лет назад, когда стоимость компьютерного времени была очень высока. В этих условиях она позволяла сократить объем перебора объясняющих переменных и широко использовалась. В настоящее время появились новые очень эффективные регрессионные модели. Так был разработан более общий подход к построению альтернативных регрессионных моделей, получивший название метода выбора наилучшего подмножества. В последнее время появилась новая методика исследования — интеллектуальный анализ данных — способ анализа информации в огромных базах данных для поиска статистически значимых зависимостей среди огромного количества объясняющих переменных. В этих условиях метод выбора наилучшего подмножества становится непрактичным.
С помощью метода выбора наилучшего подмножества либо оценивают всевозможные регрессионные модели для заданного набора данных, либо определяют наилучшие подмножества моделей для заданного количества независимых переменных. На рис. 15 показаны результаты применения метода выбора наилучшего подмножества для решения задачи о простоях на телевизионной станции. Обратите внимание на то, что максимальным значением скорректированного коэффициента r 2 является число 0,551. Оно достигается для модели, в которой учитываются четыре объясняющие переменные и эффект взаимодействия всех пяти оцениваемых параметров.

Рис. 15. Результаты применения метода выбора наилучшего подмножества для решения задачи о простоях на телевизионной станции; чтобы создать эту таблицу нужно последовательно провести регрессионный анализ для каждого набора объясняющих переменных (всего 15 раз, подробнее см. файл Данные для построения рисунка 15); обратите внимание на чрезвычайно маленькое значение коэффициента r 2 и учтите, что скорректированный коэффициент r 2 может быть отрицательным.
В качестве второго критерия часто используется статистика, предложенная Мэллоусом. Статистика Ср оценивает разность между эмпирической и истинной регрессионной моделями:

где n – количество наблюдений (в нашем случае 26, см. рис. 10), k — количество независимых переменных, включенных в регрессионную модель, Т — общее количество параметров (включая эффекты взаимодействия), включенных в полную модель регрессии (T = kmax + 1),  — коэффициент множественной смешанной корреляции в регрессионной модели, содержащей k независимых переменных,
— коэффициент множественной смешанной корреляции в регрессионной модели, содержащей k независимых переменных,  — коэффициент множественной смешанной корреляции в полной регрессионной модели, содержащей все Т оцениваемых параметра.
— коэффициент множественной смешанной корреляции в полной регрессионной модели, содержащей все Т оцениваемых параметра.
Вычислим статистику Ср для модели, содержащей продолжительность работы в офисе и количество часов, проведенных на выезде, используя вышеприведенную формулу:
n = 26, k = 2, T = 4 + 1 = 5, = 0,490, = 0,623.

Если отклонения регрессионной модели, содержащей k независимых переменных, от истинной модели являются случайными, среднее значение статистики Ср равно k + 1 , т.е. количеству параметров. Таким образом, при оценке многих альтернативных регрессионных моделей основная цель — найти модели, для которых величина Ср близка k + 1 или меньше этого числа. Как показано на рис. 15, этому критерию соответствует лишь одна модель, содержащая все четыре независимые переменные. Следовательно, необходимо выбрать именно эту модель. Довольно часто статистика Ср выделяет не одну, как в данном случае, а несколько моделей, которые подлежат более глубокому анализу на основе критериев экономии, простоты и соответствия исходным предположениям (по результатам анализа остатков). Обратите также внимание на то, что значение статистики С р для модели, выбранной по результатам пошагового анализа, равно 8,4. Эта величина намного превышает предполагаемый уровень k + 1 =3.
Определив объясняющие переменные, которые следует включить в модель, необходимо проверить ее точность с помощью анализа остатков (рис. 16). Обратите внимание на то, что все графики не демонстрируют никаких явных зависимостей.
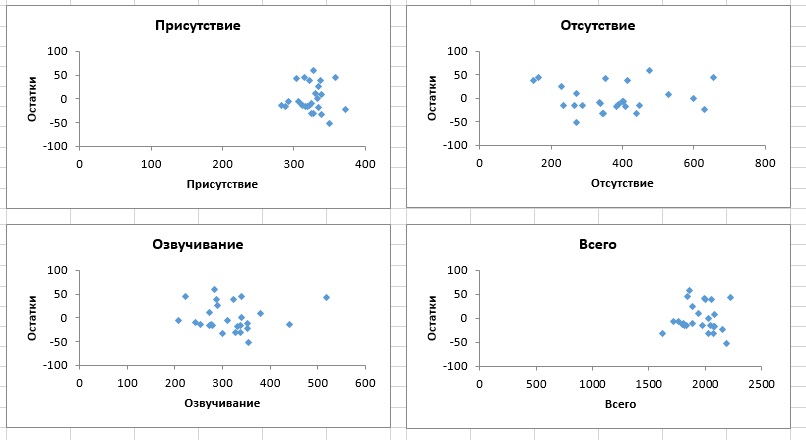
Рис. 16. Графики остатков, построенные с помощью Пакета анализа Excel при решении задачи о простоях
Этапы построения регрессионной модели (рис. 17):
- Определить набор независимых переменных для включения в регрессионную модель.
- Построить полную регрессионную модель, учитывающую все независимые переменные, и вычислить коэффициент VIF для каждой из них.
- Определить, все ли независимые переменные имеют коэффициент VIF больше пяти.
- Возможны три варианта: (а) для всех независимых переменных коэффициент VIF больше пяти. Перейти к п. 5; (б) для одной независимой переменной коэффициент VIF больше пяти. Исключить ее из модели и, перейти к п. 5; (в) для нескольких независимых переменных коэффициент VIF больше пяти. Исключить из модели независимую переменную, имеющую наибольший коэффициент VIF, и перейти к п. 2.
- Применить метод выбора наилучшего подмножества к оставшимся переменным и определить наилучшую модель (по величине Ср).
- Перечислить все модели, у которых Ср ≤ k + 1.
- Выбрать среди моделей, обнаруженных в п. 6, наилучшую.
- Выполнить полный анализ выбранной модели, включая анализ остатков.
- В зависимости от результатов анализа остатков добавить квадратичные члены, преобразовать данные и выполнить повторный анализ.
- Применить полученную модель, чтобы предсказать значения зависимой переменной.

Рис. 17. Схема построения модели
Ловушки и этические проблемы, связанные со множественной регрессией
Построение моделей является синтезом искусства и науки. Разные люди придерживаются разных точек зрения на оптимальность регрессионных моделей. В любом случае рекомендуем придерживаться схемы на рис. 17. Однако применение этой схемы сопряжено с некоторыми ловушками:
- Необходимо понимать, что при интерпретации коэффициента регрессии, соответствующего конкретной независимой переменной, остальные переменные считаются константами.
- Следует проводить анализ остатков для каждой независимой переменной.
- Нужно оценивать эффект взаимодействия и проверять, чтобы наклоны отклика по каждой из объясняющей переменной были одинаковыми.
- Необходимо вычислять коэффициенты VIF для каждой независимой переменной, включаемой в модель.
- Следует проверять несколько альтернативных моделей, используя метод выбора наилучшего подмножества.
Этические вопросы возникают, когда модель множественной регрессии используется для предсказания величин, находящихся под управлением пользователя. Ключевым моментом в этом случае являются намерения исследователя. Возможны варианты, когда статистик преднамеренно не исключает из модели множественной регрессии коллинеарные переменные и неправомерно применяет метод наименьших квадратов даже тогда, когда не выполняются необходимые условия.
Резюме. В заметке показано, как директор телевизионной станции может применять множественный линейный анализ для сокращения продолжительности простоев. Рассмотрены различные модели множественной регрессии, включая квадратичные модели, модели с фиктивными переменными, модели с эффектами взаимодействия. Изучены способы преобразования переменных, исследованы коллинеарные переменные и описан процесс построения регрессионной модели.
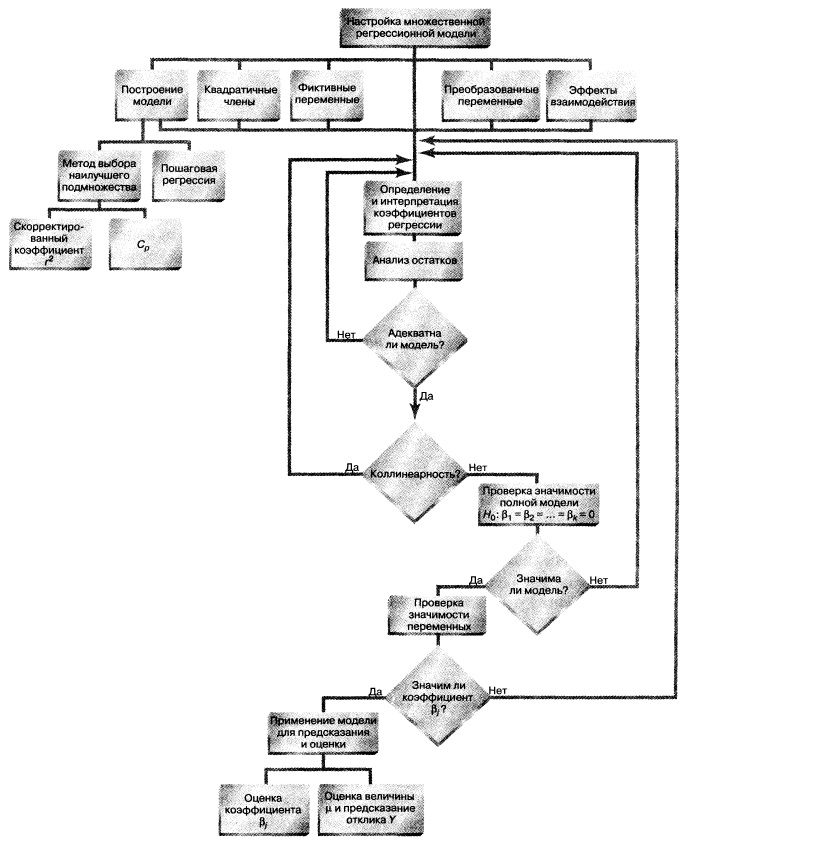
Рис. 18. Структурная схема заметки
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 937–981
[2] Гомоскедастичность – равенство дисперсий случайных отклонений для различных Х, то есть, распределение предсказанного отклика Y вокруг среднего значения  одинаково для всех Х.
одинаково для всех Х.
Множественная линейная регрессия. Улучшение модели регрессии
Понятие множественной линейной регрессии
Множественная линейная регрессия — выраженная в виде прямой зависимость среднего значения величины Y от двух или более других величин X 1 , X 2 , . X m . Величину Y принято называть зависимой или результирующей переменной, а величины X 1 , X 2 , . X m — независимыми или объясняющими переменными.
В случае множественной линейной регрессии зависимость результирующей переменной одновременно от нескольких объясняющих переменных описывает уравнение или модель
 ,
,
где  — коэффициенты функции линейной регрессии генеральной совокупности,
— коэффициенты функции линейной регрессии генеральной совокупности,
 — случайная ошибка.
— случайная ошибка.
Функция множественной линейной регрессии для выборки имеет следующий вид:
 ,
,
где  — коэффициенты модели регрессии выборки,
— коэффициенты модели регрессии выборки,
 — ошибка.
— ошибка.
Уравнение множественной линейной регрессии и метод наименьших квадратов
Коэффициенты модели множественной линейной регресии, так же, как и для парной линейной регрессии, находят при помощи метода наименьших квадратов.
Разумеется, мы будем изучать построение модели множественной регрессии и её оценивание с использованием программных средств. Но на экзамене часто требуется привести формулы МНК-оценки (то есть оценки по методу наименьших квадратов) коэффициентов уравнения множественной линейной регрессии в скалярном и в матричном видах.
МНК-оценка коэффиентов уравнения множественной регрессии в скалярном виде
Метод наименьших квадратов позволяет найти такие значения коэффициентов, что сумма квадратов отклонений будет минимальной. Для нахождения коэффициентов решается система нормальных уравнений

Решение системы можно получить, например, методом Крамера:
 .
.
Определитель системы записывается так:

МНК-оценка коэффиентов уравнения множественной регрессии в матричном виде
Данные наблюдений и коэффициенты уравнения множественной регрессии можно представить в виде следующих матриц:

Формула коэффициентов множественной линейной регрессии в матричном виде следующая:
 ,
,
где  — матрица, транспонированная к матрице X,
— матрица, транспонированная к матрице X,
 — матрица, обратная к матрице
— матрица, обратная к матрице  .
.
Решая это уравнение, мы получим матрицу-столбец b, элементы которой и есть коэффициенты уравнения множественной линейной регрессии, для нахождения которых и был изобретён метод наименьших квадратов.
Построение наилучшей (наиболее качественной) модели множественной линейной регрессии
Пусть при обработке данных некоторой выборки в пакете программных средств STATISTICA получена первоначальная модель множественной линейной регрессии. Предстоит проанализировать полученную модель и в случае необходимости улучшить её.
Качество модели множественной линейной регрессии оценивается по тем же показателям качества, что и в случае модели парной линейной регрессии: коэффициент детерминации  , F-статистика (статистика Фишера), сумма квадратов остатков RSS, стандартная ошибка регрессии (SEE). В случае множественной регрессии следует использовать также скорректированный коэффициент детерминации (adjusted ), который применяется при исключении или добавлении в модель наблюдений или переменных.
, F-статистика (статистика Фишера), сумма квадратов остатков RSS, стандартная ошибка регрессии (SEE). В случае множественной регрессии следует использовать также скорректированный коэффициент детерминации (adjusted ), который применяется при исключении или добавлении в модель наблюдений или переменных.
Важный показатель качества модели линейной регрессии — проверка на выполнение требований Гаусса-Маркова к остаткам. В качественной модели линейной регрессии выполняются все условия Гаусса-Маркова:
- условие 1: математическое ожидание остатков равно нулю для всех наблюдений ( ε(e i ) = 0 );
- условие 2: теоретическая дисперсия остатков постоянна (равна константе) для всех наблюдений ( σ²(e i ) = σ²(e i ), i = 1, . n );
- условие 3: отсутствие систематической связи между остатками в любых двух наблюдениях;
- условие 4: отсутствие зависимости между остатками и объясняющими (независимыми) переменными.
В случае выполнения требований Гаусса-Маркова оценка коэффициентов модели, полученная методом наименьших квадратов является
Затем необходимо провести анализ значимости отдельных переменных модели множественной линейной регрессии с помощью критерия Стьюдента.
В случае наличия резко выделяющихся наблюдений (выбросов) нужно последовательно по одному исключить их из модели и проанализировать наличие незначимых переменных в модели и, в случае необходимости исключить их из модели по одному.
В исследованиях поведения человека, как и во многих других, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Кроме того, требуется на основе тех же данных построить две нелинейные модели регрессии — с квадратами двух наиболее значимых переменных и с логарифмами тех же наиболее значимых переменных. Они также будут сравниваться с линейными моделями, полученных на разных шагах.
Также требуется построить модели с применением пошаговых процедур включения (FORWARD STEPWISE) и исключения (BACKWARD STEPWISE).
Все полученные модели множественной регрессии нужно сравнить и выбрать из них наилучшую (наиболее качественную). Теперь разберём перечисленные выше шаги последовательно и на примере.
Оценка качества модели множественной линейной регрессии в целом
Пример. Задание 1. Получено следующее уравнение множественной линейной регрессии:
и следующие показатели качества описываемой этим уравнением модели:
| adj. | RSS | SEE | F | p-level |
| 0,426 | 0,279 | 2,835 | 1,684 | 2,892 | 0,008 |
Сделать вывод о качестве модели в целом.
Ответ. По всем показателям модель некачественная. Значение не стремится к единице, а значение скорректированного ещё более низкое. Значение RSS, напротив, высокое, а p-level — низкое.
Для анализа на выполнение условий Гаусса-Маркова воспользуемся диаграммой рассеивания наблюдений (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши):

Результаты проверки графика показывают: условие равенства нулю математического ожидания остатков выполняется, а условие на постоянство дисперсии — не выполняется. Достаточно невыполнения хотя бы одного условия Гаусса-Маркова, чтобы заключить, что оценка коэффициентов модели линейной регрессии не является несмещённой, эффективной и состоятельной.
Анализ значимости коэффициентов модели множественной линейной регрессии
С помощью критерия Стьюдента проверяется гипотеза о том, что соответствующий коэффициент незначимо отличается от нуля, и соответственно, переменная при этом коэффициенте имеет незначимое влияние на зависимую переменную. В свою очередь, в колонке p-level выводится вероятность того, что основная гипотеза будет принята. Если значение p-level больше уровня значимости α, то основная гипотеза принимается, иначе – отвергается. В нашем примере установлен уровень значимости α=0,05.
Пример. Задание 2. Получены следующие значения критерия Стьюдента (t) и p-level, соответствующие переменным уравнения множественной линейной регрессии:
| Перем. | Знач. коэф. | t | p-level |
| X1 | 0,129 | 2,386 | 0,022 |
| X2 | -0,286 | -2,439 | 0,019 |
| X3 | -0,037 | -0,238 | 0,813 |
| X4 | 0,15 | 1,928 | 0,061 |
| X5 | 0,328 | 0,548 | 0,587 |
| X6 | -0,391 | -0,503 | 0,618 |
| X7 | -0,673 | -0,898 | 0,375 |
| X8 | -0,006 | -0,07 | 0,944 |
| X9 | -1,937 | -2,794 | 0,008 |
| X10 | -1,233 | -1,863 | 0,07 |
Сделать вывод о значимости коэффициентов модели.
Ответ. В построенной модели присутствуют коэффициенты, которые незначимо отличаются от нуля. В целом же у переменной X8 коэффициент самый близкий к нулю, а у переменной X9 — самое высокое значение коэффициента. Коэффициенты модели линейной регрессии можно ранжировать по мере убывания незначимости с возрастанием значения t-критерия Стьюдента.
Исключение резко выделяющихся наблюдений
Пример. Задание 3. Выявлены несколько резко выделяющихся наблюдений (выбросов, то есть наблюдений с нетипичными значениями): 10, 3, 4 (соответствуют строкам исходной таблицы данных). Эти наблюдения следует последовательно исключить из модели и по мере исключения заполнить таблицу с показателями качества модели. Исключили наблюдение 10 — заполнили значение показателей, далее исключили наблюдение 3 — заполнили и так далее. По мере исключения STATISTICA будет выдавать переменные, которые остаются значимыми в модели множественной линейной регрессии — они будут выделены красном цветом. Те, что не будут выделены красным цветом — незначимые переменные и их также нужно внести в соответствующую ячейку таблицы. По завершении исключения выбросов записать уравнение конечной множественной линейной регрессии.
| № | adj. | SEE | F | p- level | незнач. пер. |
| 10 | 0,411 | 2,55 | 2,655 | 0,015 | X3, X4, X5, X6, X7, X8, X10 |
| 3 | 0,21 | 2,58 | 2,249 | 0,036 | X3, X4, X5, X6, X7, X8, X10 |
| 4 | 0,16 | 2,61 | 1,878 | 0,082 | X3, X4, X5, X6, X7, X8, X10 |
Уравнение конечной множественной линейной регрессии:
Случается однако, когда после исключения некоторого наблюдения исключение последующих наблюдений приводит к ухудшению показателей качества модели. Причина в том, что с исключением слишком большого числа наблюдений выборка теряет информативность. Поэтому в таких случаях следует вовремя остановиться.
Исключение незначимых переменных из модели
Пример. Задание 4. По мере исключения из модели множественной линейной регрессии переменных с незначимыми коэффициентами (получены при выполнении предыдущего задания, занесены в последнюю колонку таблицы) заполнить таблицу с показателями качества модели. Последняя колонка, обозначенная звёздочкой — список переменных, имеющих значимое влияние на зависимую переменную. Эти переменные STATISTICA будет выдавать выделенными красным цветом. По завершении исключения незначимых переменных записать уравнение конечной множественной линейной регрессии.
| Искл. пер. | adj. | SEE | F | p- level | * |
| X3 | 0,18 | 1,71 | 2,119 | 0,053 | X4, X5, X6, X7, X8, X10 |
| X4 | 0,145 | 1,745 | 1,974 | 0,077 | X5, X6, X7, X8, X10 |
| X5 | 0,163 | 2,368 | 2,282 | 0,048 | X6, X7, X8, X10 |
| X6 | 0,171 | 2,355 | 2,586 | 0,033 | X7, X8, X10 |
| X7 | 0,167 | 2,223 | 2,842 | 0,027 | X8, X10 |
| X8 | 0,184 | 1,705 | 3,599 | 0,013 | X10 |
Когда осталась одна переменная, имеющая значимое влияние на зависимую переменную, больше не исключаем переменные, иначе получится, что в модели все переменные незначимы.
Уравнение конечной множественной линейной регрессии после исключения незначимых переменных:
Переменные X1 и X2 в задании 3 не вошли в список незначимых переменных, поэтому они вошли в уравнение конечной множественной линейной регрессии «автоматически».
Нелинейные модели для сравнения
Пример. Задание 5. Построить две нелинейные модели регрессии — с квадратами двух наиболее значимых переменных и с логарифмами тех же наиболее значимых переменных.
Так как в наблюдениях переменных X9 и X10 имеется 0, а натуральный логарифм от 0 вычислить невозможно, то берутся следующие по значимости переменные: X1 и X2.
Полученное уравнение нелинейной регрессии с квадратами двух наиболее значимых переменных:
Показатели качества первой модели нелинейной регрессии:
| adj. | RSS | SEE | F | p-level |
| 0,17 | 0,134 | 159,9 | 1,845 | 4,8 | 0,0127 |
Вывод: модель некачественная, так как RSS и SEE принимают высокие значения, p-level стремится к нулю, коэффициент детерминации незначимо отличается от нуля.
Полученное уравнение нелинейной регрессии с логарифмами двух наиболее значимых переменных:
Показатели качества второй модели нелинейной регрессии:
| adj. | RSS | SEE | F | p-level |
| 0,182 | 0,148 | 157,431 | 1,83 | 5,245 | 0 |
Вывод: модель некачественная, так как RSS и SEE принимают высокие значения, p-level стремится к нулю, коэффициент детерминации незначимо отличается от нуля.
Применение пошаговых алгоритмов включения и исключения переменных
Пример. Задание 6. Настроить пакет STATISTICA для применения пошаговых процедур включения (FORWARD STEPWISE) и исключения (BACKWARD STEPWISE). Для этого в диалоговом окне MULTIPLE REGRESSION указать Advanced Options (stepwise or ridge regression). В поле Method выбрать либо Forward Stepwise (алгоритм пошагового включения), либо Backward Stepwise (алгоритм пошагового исключения). Необходимо настроить следующие параметры:
- в окне Tolerance необходимо установить критическое значение для уровня толерантности (оставить предложенное по умолчанию);
- в окне F-remove необходимо установить критическое значение для статистики исключения (оставить предложенное по умолчанию);
- в окне Display Results необходимо установить режим At each step (результаты выводятся на каждом шаге процедуры).
Построить, как описано выше, модели множественной линейной регрессии автоматически.
В результате применения пошагового алгоритма включения получено следующее уравнение множественной линейной регрессии:
Показатели качества модели нелинейной регрессии, полученной с применением пошаговой процедуры включения:
| adj. | RSS | SEE | F | p-level |
| 0,41 | 0,343 | 113,67 | 1,61 | 6,11 | 0,002 |
В результате применения пошагового алгоритма исключения получено следующее уравнение множественной линейной регрессии:
Показатели качества модели нелинейной регрессии, полученной с применением пошаговой процедуры исключения:
| adj. | RSS | SEE | F | p-level |
| 0,22 | 0,186 | 150,28 | 1,79 | 6,61 | 0 |
Выбор самой качественной модели множественной линейной регрессии
Пример. Задание 7. Сравнить модели, полученные на предыдущих шагах и определить самую качественную.
| Модель | Ручная | Кв. перем. | Лог. перем. | forward stepwise | backward stepwise |
| 0,255 | 0,17 | 0,182 | 0,41 | 0,22 |
| adj. | 0,184 | 0,134 | 0,148 | 0,343 | 0,186 |
| RSS | 122,01 | 159,9 | 157,43 | 113,67 | 150,28 |
| SEE | 1,705 | 1,845 | 1,83 | 1,61 | 1,79 |
| F | 3,599 | 4,8 | 5,245 | 6,11 | 6,61 |
| p-level | 0,013 | 0,0127 | 0 | 0,002 | 0 |
Самая качественная модель множественной линейной регрессии — модель, построенная методом FORWARD STEPWISE (пошаговое включение переменных), так как коэффициент детерминации у неё самый высокий, а RSS и SEE наименьшие в сравнении значений оценок качества других регрессионных моделей.