- Страницы работы
- Фрагмент текста работы
- Уравнение множественной регрессии
- Построение парной регрессионной модели
- Множественная регрессия в EXCEL
- Оценка неизвестных параметров
- Диаграмма рассеяния
- Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
- Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
- Проверка гипотез
- Генерация данных для множественной регрессии с помощью заданного тренда
- Коэффициент детерминации
Страницы работы





Фрагмент текста работы
Тема 4. Множественная регрессия и корреляция
4.1. Спецификация модели множественной регрессии 4.2. Оценка параметров уравнения множествен-ной регрессии 4.3. Множественная корреляция 4.4. Оценка надежности результатов множествен-ной регрессии и корреляции 4.5. Предпосылки метода наименьших квадратов и обобщенный МНК
4.1. Спецификация модели множественной регрессии
Спецификация модели – обоснованный с позиций экономической теории выбор вида и структуры модели, отбор факторов и математическое описание характера их влияния на результирующий признак
Если при построении эконометрической модели не удается выявить единственный фактор, оказывающий доминирующее влияние на исследуемый результативный признак, то вместо парной регрессии применяют множественную регрессию. Множественная регрессия – это уравнение связи зависимой переменной с несколькими независимыми переменными: y = f ( x1, x2, … , xm, e ), где y — зависимая переменная (результативный признак); x1, x2, … , xm — независимые переменные (факторы); e — случайная величина (остаток). Спецификация модели множественной регрессии включает выбор вида функции регрессии и отбор факторов.
Функции множественной регрессии
Для построения модели множественной регрессии чаще используются следующие функции: · линейная y = a + b1 * x1 + b2 * x2 + … + bm * xm + e ; · степенная · экспонента · гипербола · полином y = a + b1* x1 + b2* x2 + b3* x12 + b4 * x22 + b5*x1*x2 + e Можно использовать и другие функции, приводимые к линейному виду. Однако, при этом число наблюдений должно не менее, чем в 6 – 8 раз превышать число факторов и модель должна быть экономически интерпретируемой.
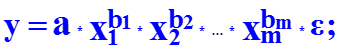
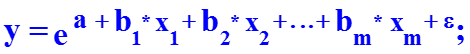
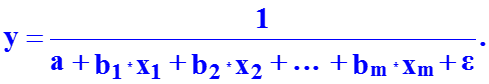
Степенная модель множественной регрессии применяется в производственных функциях вида : где P – количество продукта, изготавливаемого с помощью m производственных факторов объемом F1, F2, …, Fm; bi – эластичность количества продукции по отношению к объему i-го производственного фактора. Коэффициенты bi показывают, на сколько процентов изменяется результат с изменением соответствующего фактора на 1 процент. Сумма bi характеризует общую эластичность выпуска продукции, т.е. процент увеличения выпуска продукции при возрастании объема каждого фактора на 1 процент.
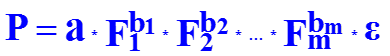
Стандартизованное уравнение линейной регрессии
В ряде случаев применяют линейное уравнение регрессии в стандартизованном масштабе: где — стандартизованные переменные; bi – стандартизованные коэффициенты регрессии. Коэффициенты bi позволяют ранжировать факторы по силе их влияния на результативный признак. Связь коэффи-циентов множественной регрессии bi со стандартизованными коэффициентами bi описывается соотношением Параметр a определяется как
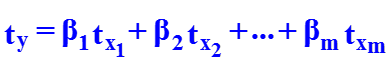
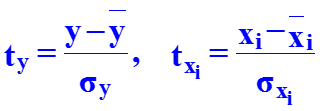
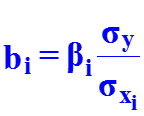
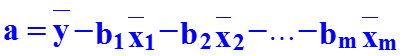
Примеры множественной линейной регрессии
Расходы семьи на продукты питания y в зависимости от дохода на одного члена семьи x1 и размера семьи x2: y = a + b1 * x1 + b2 * x2 + e Уровень потребления в текущем периоде Ct в зависимости от дохода того же периода Rt и от дохода предшествующего периода Rt-1 : Ct = a + b0 * Rt + b1 * Rt-1 + e , b0 — краткосрочная предельная склонность к потреблению, b = b0 + b1 — долгосрочная склонность к потреблению. Функция потребления может рассматриваться также в зависимости от предыдущего уровня потребления Ct-1: Ct = a + b0 * Rt + b1 * Ct-1 + e , долгосрочная склонность к потреблению здесь равна:
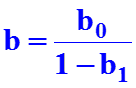
Фиктивные переменные для качественных факторов
Факторы должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, то каждому его уровню следует тем или иным способом придать количественную определенность. С этой целью применяются фиктивные переменные. Если качественный фактор имеет два различимых уровня, то вводится одна фиктивная переменная Z, значения которой устанавливаются равными:
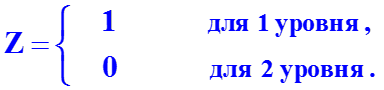
Если качественный фактор имеет три уровня, то вводятся две фиктивные переменные Z1 и Z2, значения которых устанавливаются равными:
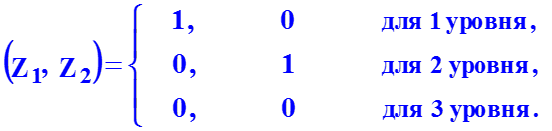
Фиктивная переменная для качественного фактора с 2 уровнями
Факторы должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, то каждому его уровню следует тем или иным способом придать количественную определенность. С этой целью применяются фиктивные переменные. Если качественный фактор имеет два различимых уровня с n1 и n2 наблю-дениями, то вводится одна фиктивная переменная
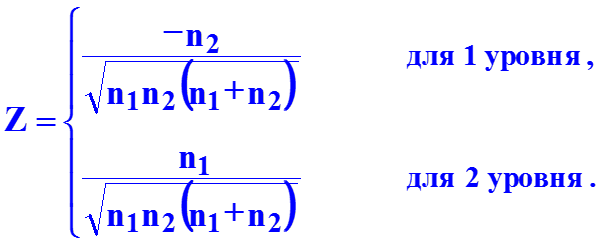
Можно использовать значение 0 для первого уровня и 1 для второго уровня (или, наоборот).
Фиктивные переменные для качественного фактора с 3 уровнями
Уравнение множественной регрессии
Назначение сервиса . С помощью онлайн-калькулятора можно найти следующие показатели:
- уравнение множественной регрессии, матрица парных коэффициентов корреляции, средние коэффициенты эластичности для линейной регрессии;
- множественный коэффициент детерминации, доверительные интервалы для индивидуального и среднего значения результативного признака;
Кроме этого проводится проверка на автокорреляцию остатков и гетероскедастичность.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Отбор факторов обычно осуществляется в два этапа:
- теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
- количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции). Научно обоснованное решение задач подобного вида также осуществляется с помощью дисперсионного анализа — однофакторного, если проверяется существенность влияния того или иного фактора на рассматриваемый признак, или многофакторного в случае изучения влияния на него комбинации факторов.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
- Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
- Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
- Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность — тесная линейная связь между факторами.
Пример . Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели.
Решение.
К исходной матрице X добавим единичный столбец, получив новую матрицу X
| 1 | 5 | 14.5 |
| 1 | 12 | 18 |
| 1 | 6 | 12 |
| 1 | 7 | 13 |
| 1 | 8 | 14 |
Матрица Y
| 9 |
| 13 |
| 16 |
| 14 |
| 21 |
Транспонируем матрицу X, получаем X T :
| 1 | 1 | 1 | 1 | 1 |
| 5 | 12 | 6 | 7 | 8 |
| 14.5 | 18 | 12 | 13 | 14 |
| Умножаем матрицы, X T X = |
|
В матрице, (X T X) число 5, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
| Умножаем матрицы, X T Y = |
|
Находим обратную матрицу (X T X) -1
| 13.99 | 0.64 | -1.3 |
| 0.64 | 0.1 | -0.0988 |
| -1.3 | -0.0988 | 0.14 |
Вектор оценок коэффициентов регрессии равен
| (X T X) -1 X T Y = y(x) = |
| * |
| = |
|
Получили оценку уравнения регрессии: Y = 34.66 + 1.97X1-2.45X2
Оценка значимости уравнения множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю коэффициент детерминации рассчитанного по данным генеральной совокупности. Для ее проверки используют F-критерий Фишера.
R 2 = 1 — s 2 e/∑(yi — yср) 2 = 1 — 33.18/77.2 = 0.57
F = R 2 /(1 — R 2 )*(n — m -1)/m = 0.57/(1 — 0.57)*(5-2-1)/2 = 1.33
Табличное значение при степенях свободы k1 = 2 и k2 = n-m-1 = 5 — 2 -1 = 2, Fkp(2;2) = 19
Поскольку фактическое значение F = 1.33 Пример №2 . Приведены данные за 15 лет по темпам прироста заработной платы Y (%), производительности труда X1 (%), а также по уровню инфляции X2 (%).
| Год | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X1 | 3,5 | 2,8 | 6,3 | 4,5 | 3,1 | 1,5 | 7,6 | 6,7 | 4,2 | 2,7 | 4,5 | 3,5 | 5,0 | 2,3 | 2,8 |
| X2 | 4,5 | 3,0 | 3,1 | 3,8 | 3,8 | 1,1 | 2,3 | 3,6 | 7,5 | 8,0 | 3,9 | 4,7 | 6,1 | 6,9 | 3,5 |
| Y | 9,0 | 6,0 | 8,9 | 9,0 | 7,1 | 3,2 | 6,5 | 9,1 | 14,6 | 11,9 | 9,2 | 8,8 | 12,0 | 12,5 | 5,7 |
Решение. Подготовим данные для вставки из MS Excel (как транспонировать таблицу для сервиса см. Задание №2) .

Включаем в отчет: Проверка общего качества уравнения множественной регрессии (F-статистика. Критерий Фишера, Проверка на наличие автокорреляции),
После нажатия на кнопку Дале получаем готовое решение.
Уравнение регрессии (оценка уравнения регрессии):
Y = 0.2706 + 0.5257X1 + 1.4798X2
Скачать.
Качество построенного уравнения регрессии проверяется с помощью критерия Фишера (п. 6 отчета).
Пример №3 .
В таблице представлены данные о ВВП, объемах потребления и инвестициях некоторых стран.
| ВВП | 16331,97 | 16763,35 | 17492,22 | 18473,83 | 19187,64 | 20066,25 | 21281,78 | 22326,86 | 23125,90 |
| Потребление в текущих ценах | 771,92 | 814,28 | 735,60 | 788,54 | 853,62 | 900,39 | 999,55 | 1076,37 | 1117,51 |
| Инвестиции в текущих ценах | 176,64 | 173,15 | 151,96 | 171,62 | 192,26 | 198,71 | 227,17 | 259,07 | 259,85 |
Решение:
Для проверки полученных расчетов используем инструменты Microsoft Excel «Анализ данных» (см. пример).
Пример №4 . На основе данных, приведенных в Приложении и соответствующих Вашему варианту (таблица 2), требуется:
- Построить уравнение множественной регрессии. При этом признак-результат и один из факторов остаются теми же, что и в первом задании. Выберите дополнительно еще один фактор из приложения 1 (границы наблюдения должны совпадать с границами наблюдения признака-результата, соответствующего Вашему варианту). При выборе фактора нужно руководствоваться его экономическим содержанием или другими подходами. Пояснить смысл параметров уравнения.
- Рассчитать частные коэффициенты эластичности. Сделать вывод.
- Определить стандартизованные коэффициенты регрессии (b-коэффициенты). Сделать вывод.
- Определить парные и частные коэффициенты корреляции, а также множественный коэффициент корреляции; сделать выводы.
- Оценить значимость параметров уравнения регрессии с помощью t-критерия Стьюдента, а также значимость уравнения регрессии в целом с помощью общего F-критерия Фишера. Предложить окончательную модель (уравнение регрессии). Сделать выводы.
Решение. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 3.9 | 10 |
| 1 | 3.9 | 14 |
| 1 | 3.7 | 15 |
| 1 | 4 | 16 |
| 1 | 3.8 | 17 |
| 1 | 4.8 | 19 |
| 1 | 5.4 | 19 |
| 1 | 4.4 | 20 |
| 1 | 5.3 | 20 |
| 1 | 6.8 | 20 |
| 1 | 6 | 21 |
| 1 | 6.4 | 22 |
| 1 | 6.8 | 22 |
| 1 | 7.2 | 25 |
| 1 | 8 | 28 |
| 1 | 8.2 | 29 |
| 1 | 8.1 | 30 |
| 1 | 8.5 | 31 |
| 1 | 9.6 | 32 |
| 1 | 9 | 36 |
Матрица Y
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 8 |
| 8 |
| 8 |
| 10 |
| 9 |
| 11 |
| 9 |
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 14 |
| 14 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3.9 | 3.9 | 3.7 | 4 | 3.8 | 4.8 | 5.4 | 4.4 | 5.3 | 6.8 | 6 | 6.4 | 6.8 | 7.2 | 8 | 8.2 | 8.1 | 8.5 | 9.6 | 9 |
| 10 | 14 | 15 | 16 | 17 | 19 | 19 | 20 | 20 | 20 | 21 | 22 | 22 | 25 | 28 | 29 | 30 | 31 | 32 | 36 |
Умножаем матрицы, (X T X)
Умножаем матрицы, (X T Y)
Находим определитель det(X T X) T = 139940.08
Находим обратную матрицу (X T X) -1
Уравнение регрессии
Y = 1.8353 + 0.9459X 1 + 0.0856X 2
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s
| 0.62 |
| 0.28 |
| 0.38 |
| 0.01 |
| 0.11 |
| -1 |
| -0.57 |
| 0.29 |
| -0.56 |
| 0.02 |
| -0.31 |
| 1.23 |
| -1.15 |
| 0.21 |
| 0.2 |
| -0.07 |
| -0.07 |
| -0.53 |
| 0.34 |
| 0.57 |
se 2 = (Y — X*s) T (Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(X T X) -1
| k(x) = 0.36 |
| = |
|
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X сильная
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции — последовательно берутся пары yx1,yx2. , x1x2, x1x3.. и так далее и для каждой пары находится коэффициент корреляции
Коэффициент детерминации
R 2 = 0.97 2 = 0.95, т.е. в 95% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл: Tтабл (n-m-1;a) = (17;0.05) = 1.74
Поскольку Tнабл Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
Построение парной регрессионной модели
Рекомендации к решению контрольной работы.
Статистические данные по экономике можно получить на странице Россия в цифрах.
После определения зависимой и объясняющих переменных можно воспользоваться сервисом Множественная регрессия. Регрессионную модель с 2-мя объясняющими переменными можно построить используя матричный метод нахождения параметров уравнения регрессии или метод Крамера для нахождения параметров уравнения регрессии.
Пример №3 . Исследуется зависимость размера дивидендов y акций группы компаний от доходности акций x1, дохода компании x2 и объема инвестиций в расширение и модернизацию производства x3. Исходные данные представлены выборкой объема n=50.
Тема I. Парная линейная регрессия
Постройте парные линейные регрессии — зависимости признака y от факторов x1, x2, x3 взятых по отдельности. Для каждой объясняющей переменной:
- Постройте диаграмму рассеяния (поле корреляции). При построении выберите тип диаграммы «Точечная» (без отрезков, соединяющих точки).
- Вычислите коэффициенты уравнения выборочной парной линейной регрессии (для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические») или надстройкой Пакет Анализа), коэффициент детерминации, коэффициент корреляции (функция КОРЕЛЛ), среднюю ошибку аппроксимации
 .
. - Запишите полученное уравнение выборочной регрессии. Дайте интерпретацию найденным в предыдущем пункте значениям.
- Постройте на поле корреляции прямую линию выборочной регрессии по точкам .
- Постройте диаграмму остатков.
- Проверьте статистическую значимость коэффициентов регрессии по критерию Стьюдента (табличное значение определите с помощью функции СТЬЮДРАСПОБР) и всего уравнения в целом по критерию Фишера (табличное значение Fтабл определите с помощью функции FРАСПОБР).
- Постройте доверительные интервалы для коэффициентов регрессии. Дайте им интерпретацию.
- Постройте прогноз для значения фактора, на 50% превышающего его среднее значение.
- Постройте доверительный интервал прогноза. Дайте ему экономическую интерпретацию.
- Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемого фактора на показатель.
Тема II. Множественная линейная регрессия
1. Постройте выборочную множественную линейную регрессию показателя на все указанные факторы. Запишите полученное уравнение, дайте ему экономическую интерпретацию.
2. Определите коэффициент детерминации, дайте ему интерпретацию. Вычислите среднюю абсолютную ошибку аппроксимации и дайте ей интерпретацию.
3. Проверьте статистическую значимость каждого из коэффициентов и всего уравнения в целом.
4. Постройте диаграмму остатков.
5. Постройте доверительные интервалы коэффициентов. Для статистически значимых коэффициентов дайте интерпретации доверительных интервалов.
6. Постройте точечный прогноз значения показателя y при значениях факторов, на 50% превышающих их средние значения.
7. Постройте доверительный интервал прогноза, дайте ему экономическую интерпретацию.
8. Постройте матрицу коэффициентов выборочной корреляции между показателем и факторами. Сделайте вывод о наличии проблемы мультиколлинеарности.
9. Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемых факторов на показатель.
Множественная регрессия в EXCEL
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).
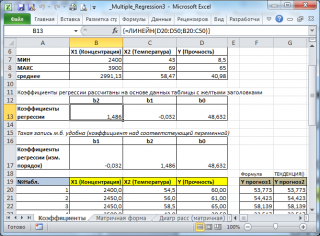
В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений 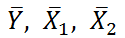 , т.е.:
, т.е.: 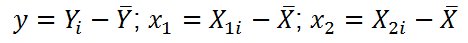
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):
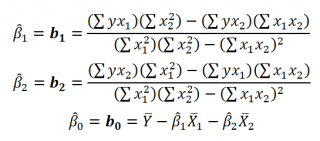
При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.
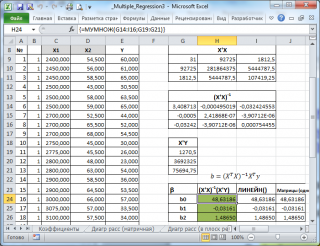
Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).
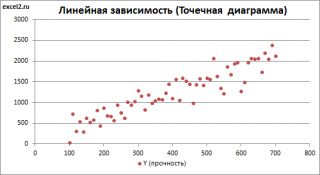
В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.
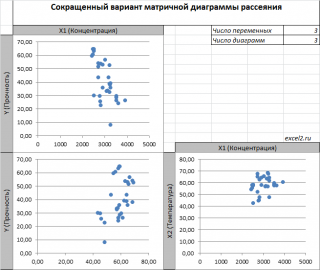
Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.
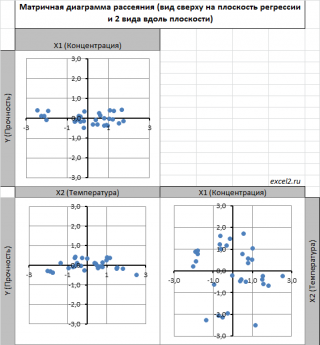
На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
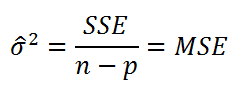
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
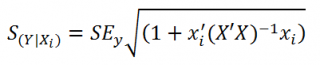
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
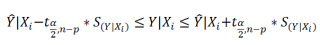
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
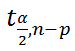 – квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
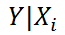 – прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
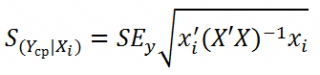
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
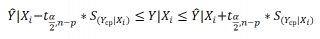
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
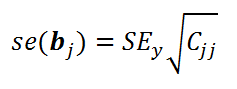
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β 0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
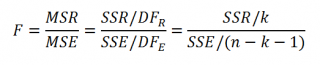
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).
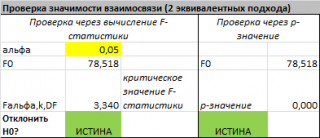
В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
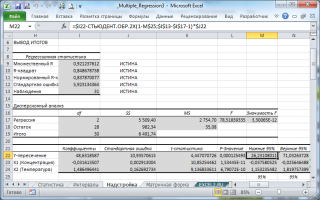
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
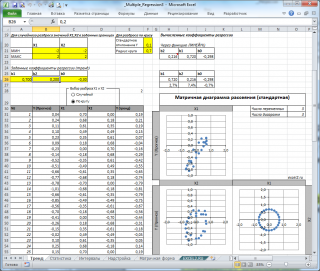
Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .
Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
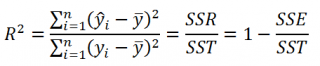
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
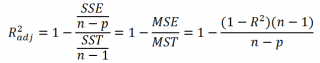
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).