В действительности на результативный признак влияет, как правило, не один фактор, а множество различных одновременно действующих факторных признаков. Так, себестоимость единицы продукции зависит от количества произведенной продукции, цены закупки сырья, заработной платы работников и производительности их труда, накладных расходов.
Количественно оценить влияние различных факторов на результат, определить форму и тесноту связи между результативным признаком у и факторными признаками xit х2,. »х* можно, используя многофакторный регрессионный анализ, который сводится к решению следующих задач:
- — построение уравнения множественной регрессии;
- — определение степени влияния каждого фактора на результативный признак;
- — количественная оценка тесноты связи между результативным признаком и факторами;
- — оценка надежности построенной регрессионной модели;
- — прогноз результативного признака.
Уравнение множественной регрессии характеризует среднее изменение у с изменением двух и более признаков-факторов: у = /(лгр xv xk).
При выборе признаков-факторов, включаемых в уравнение множественной регрессии, нужно прежде всего рассмотреть матрицы коэффициентов корреляции и выделить те переменные, для которых корреляция с результативной переменной превосходит корреляцию с другими факторами, т.е. для которых верно неравенство

Не рекомендуется совместно включать во множественную регрессию
объясняющие переменные, тесно связанные между собой: при г > 0,7
переменные и х> дублируют друг друга, и совместное включение их в уравнение регрессии не дает дополнительной информации для объяснения вариации у. Линейно связанные переменные называются коллинеар- ными.
Нс рекомендуется включать в круг объясняющих переменных признаки, представленные как абсолютные и как средние или относительные величины. Нельзя включать в регрессию признаки, функционально связанные с зависимой переменной у, например, те, которые являются составной частью у (скажем, суммарный доход и заработная плата).
Наиболее простым для построения и анализа является линейное уравнение множественной регрессии:

Интерпретация коэффициентов регрессии линейного уравнения множественной регрессии следующая: каждый из них показывает, на сколько единиц в среднем изменяется у при изменении .г, на свою единицу измерения и закреплении прочих введенных в уравнение объясняющих переменных на среднем уровне.
Так как все включенные переменные хх имеют свою размерность, то сравнивать коэффициенты регрессии Ь< нельзя, т.е. по величине Ъх нельзя сделать вывод, что одна переменная влияет сильнее на г/, а другая слабее.
Параметры линейного уравнения множественной регрессии оцениваются методом наименьших квадратов (МНК). Условие МНК: или 

Условие экстремума функции равенство нулю частных производных первого порядка данной функции:

Отсюда получаем систему нормальных уравнений, решение которой дает значения параметров уравнения множественной регрессии:

При записи системы уравнений можно руководствоваться следующим простым правилом: первое уравнение получается как сумма п уравнений регрессии; второе и последующее — как сумма п уравнений регрессии, все члены которой умножены на затем на х2 и т.д.
Параметры уравнения множественной регрессии получаем через отношение частных определителей к определителю системы:

Рассмотрим построение уравнения множественной регрессии на примере линейной двухфакторной модели:

Представим все переменные как центрированные и нормированные, т.е. выраженные как отклонения от средних величин, деленные на стандартное отклонение. Обозначим преобразованные таким образом переменные буквой t

Тогда уравнение множественной регрессии примет следующий вид: 
где pt и р2 — стандартизированные коэффициенты регрессии (бс га-коэф- фициенты), определяющие, на какую часть своего среднеквадратического отклонения изменится у при изменении Xj на одно среднеквадратическое отклонение.
Уравнение регрессии (8.20) называется уравнением в стандартизованном масштабе (или стандартизированным уравнением регрессии). Оно не имеет свободного члена, поскольку все переменные выражены через отклонения от средних величин, а, как известно, а = у-Ь<хх -Ь2х2, или при k объясняющих переменных

В отличие от коэффициентов регрессии в натуральном масштабе Ьр которые нельзя сравнивать, стандартизированные коэффициенты регрессии Р; можно сравнивать, делая вывод, влияние какого фактора на у более значительно.
Стандартизированные коэффициенты регрессии находятся также с помощью МНК:


Приравняем первые частные производные нулю получим систему нормальных уравнений


систему можно записать иначе:

Отсюда находим p-коэффициенты и сравниваем их. Если Р,>Р2, то фактор Xj сильнее влияет на результат, чем фактор х2.
От стандартизированной регрессии можно перейти к уравнению регрессии в натуральном масштабе, т.е. получить регрессию 
Коэффициенты регрессии в натуральном масштабе находятся на основе ^-коэффициентов: 

где 
После этого вычисляется совокупный коэффициент детерминации:

который показывает долю вариации результативного признака под воздействием изучаемых факторных признаков. Важно знать вклад каждой объясняющей переменной. Он измеряется коэффициентом раздельной детерминации: 
Влияние отдельных факторов в уравнении множественной регрессии может быть охарактеризовано с помощью частных коэффициентов эластичности. В случае двухфакторной линейной регрессии коэффициенты эластичности рассчитываются по формулам и измеряются в процентах:

Мы разобрали технику построения уравнения множественной регрессии. Очевидно, что оценки параметров уравнения регрессии можно получить, используя только микрокалькулятор. В современных условиях построение регрессии и расчет показателей корреляции производят с помощью ПК и пакетов прикладных программ, таких как Excel либо более специализированных: Statgraphics или Statistica и др.
Чтобы выполнить построения уравнения множественной регрессии с помощью Microsoft Office Excel, надо воспользоваться инструментом анализа данных Регрессия. Выполняются действия, аналогичные расчету параметров парной линейной регрессии, рассмотренные выше, только в отличие от парной регрессии при заполнении параметра входной интервал X в диалоговом окне следует указать все столбцы, содержащие значения факторных признаков.
Рассмотрим построение множественного уравнения регрессии при двух объясняющих переменных (двухфакторная модель). Продолжая пример, введем второй фактор время, затраченное студентом в течение недели с целью получения заработка, в часах. Данные представлены в табл. 8.5.
Видео:Эконометрика. Множественная регрессия и корреляция.Скачать

Лабораторная работа 1 Почему анализ называется линейным
| Название | Лабораторная работа 1 Почему анализ называется линейным |
| Дата | 20.03.2021 |
| Размер | 97.11 Kb. |
| Формат файла | |
| Имя файла | 9074 (1).docx |
| Тип | Лабораторная работа #186496 |
| Подборка по базе: Самостоятельная работа.docx, Практическая работа. Проектирование учебного занятия на основе П, практическая работа 2.docx, практическая работа 1. история.docx, Курсовая работа ППК Логистика.docx, Практическая работа №1.docx, Практическая работа №3.docx, Контрольная работа по налогам01.docx, Практическая работа № 3.docx, Елдар курсоваяя работа17.docx Примерные вопросы при онлайн-защите лабораторных работ Почему анализ называется линейным? Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. Почему анализ называется регрессионным? Регрессионный анализ (regression analysis) – это метод изучения статистической взаимосвязи между одной зависимой количественной зависимой переменной от одной или нескольких независимых количественных переменных. Почему анализ называется парным? Парный регрессионный анализ – это метод математической статистики, который позволяет найти наиболее точное и достоверное отображение (модель, аппроксимацию) стохастической зависимости между откликом Y и одним из факторов X. Какой показатель использовался как факторный, какой- как результативный? Факторный анализ – это анализ влияния отдельных факторов на результативный показатель с помощью детерминированных или стохастических приемов исследования.
Как выглядит уравнение регрессии в парном линейном регрессионном анализе? Y = a+bx+E Почему в модели появляются остатки? Остатки – результат деятельности большого числа различных факторов, поэтому логично ожидать, что ни один из этих факторов не должен оказывать большего влияния, чем остальные. Остатки должны представлять собой случайные величины, а значит подчиняться закону нормального распределения. Это означает следующее: основная масса точек должна лежать близко к регрессионной прямой, а чем дальше от прямой, тем точек должно быть меньше Каким методом получаются значения коэффициентов модели? В чем суть этого метода? Метод наименьших квадратов Общий смысл оценивания по методу наименьших квадратов заключается в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной от значений, предсказанных моделью.
а = 8,0626615
b = 0,9373385 Каково направление связи между фактором и результативным показателем (зависимой переменной)? Стохастический (корреляционный) – связь между результативным и факторными показателями является неполной или вероятностной. Чем прямая связь отличается от обратной? По направлению корреляционная связь бывает положительной («прямой») и отрицательной («обратной»). При прямой (обратной) связи увеличение одной из переменных ведет к увеличению (уменьшению) условной (групповой) средней другой. Что показывает коэффициент детерминации? Он показывает, какая доля дисперсии результативного признака объясняется влиянием независимых переменных. Какой вывод сделали на основе коэффициента детерминации? Коэффициент детерминации показывает, какую часть вариации (дисперсии) зависимой переменной Y воспроизводит (объясняет) построенное уравнение регрессии. В нашем случае построенное уравнение регрессии на 38,7% объясняет зависимость переменной Y от переменной X. Как обозначаются расчетные значения результативного показателя? Y = 0,937339+ 8,062661*X. Как рассчитываются прогнозные (расчетные) значения результативного показателя? Результативный показатель факторной модели представлен в виде произведения, частного или алгебраической суммы факторов. Как обозначается коэффициент детерминации? R^2 В чем он измеряется и каких пределах может варьировать? Доля дисперсии зависимой переменной, 0 2 2 =1 Каковы недостатки коэффициента детерминации? Какой коэффициент позволяет их решить? Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют! Поэтому сравнение моделей с разным количеством факторов с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели. скорректированный коэффициент детерминации , в котором используются несмещённые оценки дисперсий. В каких пределах находится скорректированный коэффициент детерминации? От 0 до 1 Что означает термин «значимость»? Значимость F – это вероятность значимости для F критерия
Коэффициент корреляции = 1,716439
= 2,306 В результате выполнения F-критерия нулевая гипотеза была принята или отвергнута? Почему? В результате выполнения F-критерия альтернативная гипотеза была принята или отвергнута? Почему? Поскольку |tкрит| > tрасч, то нулевую гипотезу о равенстве нулю коэффициента корреляции отвергаем с вероятностью ошибки меньше 5% и делаем вывод о значимости коэффициента корреляции.
Какова альтернативная гипотеза в t-критерии для коэффициента b? (в контексте рассматриваемой проблемной ситуации); В результате выполнения t-критерия для b нулевая гипотеза была принята или отвергнута? Почему? В результате выполнения t-критерия для b альтернативная гипотеза была принята или отвергнута? Почему? Нулевая гипотеза принята, так как коэффициент b меньше расчетного, то есть альтернативного (2,306). Как на основе доверительных интервалов для оценок коэффициентов регрессии можно сделать вывод об их значимости? Если окажется, что доверительный интервал включает 0, то соответствующий коэффициент регрессии объявляется незначимым. При заданном уровне значимости а = 0,05 и числе степеней свободы, равном n – 2, где n – заданный объем выборки (у нас n = 10) критическое значение статистики Стьюдента tкрит = 2,306. Как рассчитывается точечный прогноз результативной переменной? Точечный прогноз результативной переменнойу на основе линейной модели парной регрессии при заданном значении факторной переменной хm будет осуществляться по формуле: ym=β0+β1xm+εm.
[b1 – tкрит*S(b1);b1 + tкрит*S(b1)]; [b0 – tкрит*S(b0);b0 + tкрит*S(b0)]. Какой интервал получится шире- 95% или 99%? Шире 99%
Различие в формулах S ( y ˆ x* ) = S E * S E * Расположение и ширина доверительных интервалов меняются от выборки к выборке. Действительно, их расположение и ширина зависят как от оценок коэффициентов, которые являются переменными (случайными величинами), так и от случайных значений выборочных оценок среднеквадратичных отклонений a и b. Что удалось доказать по результатам проверки значимости (ответ обосновать): Что такое автокорреляция в остатках? Как она влияет на результаты оценивания регрессионного уравнения? Автокорреляция в остатках — корреляционная зависимость между значениями остатков zt за текущий и предыдущие моменты времени. Для чего используется статистика Дарбина-Уотсона? Применяют для обнаружения автокорреляции, подчиняющейся авторегрессионному процессу 1-го порядка. Предполагается, что величина остатков еt в каждом t-м наблюдении не зависит от его значений во всех других наблюдениях. Какова нулевая гипотеза в тесте Дарбина-Уотсона? Если коэффициент автокорреляции ρ положительный, то автокорреляция положительна, если ρ отрицательный, то автокорреляция отрицательна. Если ρ = 0, то автокорреляция отсутствует Какова альтернативная гипотеза в тесте Дарбина-Уотсона? Альтернативные гипотезы и состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках
Какой вывод сделали по результатам теста Дарбина-Уотсона? Поскольку |tкрит| > tрасч, то нулевую гипотезу о равенстве нулю коэффициента корреляции отвергаем с вероятностью ошибки меньше 5% и делаем вывод о значимости коэффициента корреляции. Для чего проводили тест Голфелда-Квандта? Оценить значимость уравнения регрессии. Пояснение: Тестирования гетероскедастичности случайных ошибок в регрессионной модели, которая применяется при существовании основания полагать, что может быть пропорционально стандартное отклонение ошибок некоторой переменной.
Гетероскедастичность Гомоскедастичность остатков означает, что дисперсия каждого отклонения одинакова для всех значений x. Если это условие не соблюдается, то имеет место гетероскедастичность. Гетероскедастичность остатков модели регрессии может привести к негативным последствиям:1) оценки неизвестных коэффициентов нормальной линейной модели регрессии являются несмещёнными и состоятельными, но при этом теряется свойство эффективности;2) существует большая вероятность того, что оценки стандартных ошибок коэффициентов модели регрессии будут рассчитаны неверно, что конечном итоге может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом. Какова нулевая гипотеза в тесте Голфелда-Квандта? Нулевая гипотеза о гомоскедастичности остатков отвергается на 5%-ном уровне значимости. Какова альтернативная гипотеза в Голфелда-Квандта? Гетероскедастичность — это свойство данных, используемых при построении регрессионной модели, когда разброс точек наблюдений вдоль линии регрессии является неравномерным на всем диапазоне изменения независимой переменной. Какой вывод сделали по результатам теста Голфелда-Квандта? Принимая стандартный 5% уровень значимости, в таблице критических точек распределения Фишера находим Fкрит = F(0,05;1;8) = 5,32. Поскольку Fрасч = 28,6 превышает Fкрит = 5,32, то делаем вывод о значимости уравнения регрессии
Количество степеней свободы — это количество значений в итоговом вычислении статистики, способных варьироваться. Что понимается под адекватностью модели? Адекватность модели — совпадение свойств (функций/параметров/характеристик и т. п.) модели и соответствующих свойств моделируемого объекта С каких позиций исследуется адекватность линейной парной регрессии? С позиции коэффициента детерминации – R^2 Какой вывод по результатам проведенного анализа можете сделать об адекватности модели? Коэффициент детерминации показывает, какую часть вариации (дисперсии) зависимой переменной Y воспроизводит (объясняет) построенное уравнение регрессии. В нашем случае построенное уравнение регрессии на 38,7% объясняет зависимость переменной Y от переменной X. Что характеризует коэффициент корреляции? Коэффициент корреляции – это статистическая мера, которая вычисляет силу связи между относительными движениями двух переменных. Как меняется значение коэффициента корреляции при изменении ролей результативного признака и фактора? с увеличением или с уменьшением значений одного признака происходит уменьшение или увеличение значений другого признака. Как на основе коэффициента корреляции делается вывод о тесноте и направлении связи между переменными? При отрицательной корреляции значения силы связи между переменными меняют на противоположные: если величина коэффициента корреляции между переменными равна 0,25 то это очень слабая корреляция и в большинстве случаев мы не берем ее в расчет; если величина коэффициента корреляции между переменными равна 0, 75 то это высокая корреляция и в своих интерпретациях нам стоит обратить на нее внимание; если величина коэффициента корреляции равна 1, следовательно полностью взаимосвязаны. Что означает значимость коэффициента корреляции?
Для оценки значимости коэффициента корреляции следует использовать статистику t = rxy * Видео:Регрессия - как строить и интерпретировать. Примеры линейной и множественной регрессии.Скачать  Задача №3. Расчёт параметров регрессии и корреляции с помощью ExcelПо территориям региона приводятся данные за 200Х г.
Задание:1. Постройте поле корреляции и сформулируйте гипотезу о форме связи. 2. Рассчитайте параметры уравнения линейной регрессии . 3. Оцените тесноту связи с помощью показателей корреляции и детерминации. 4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом. 5. Оцените с помощью средней ошибки аппроксимации качество уравнений. 6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования. 7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости . 8. Оцените полученные результаты, выводы оформите в аналитической записке. Решение:Решим данную задачу с помощью Excel. 1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа. Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у. Выделите область ячеек, содержащую данные. Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1. Рисунок 1 Построение поля корреляции Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии. 2. Для расчёта параметров уравнения линейной регрессии 1) Откройте существующий файл, содержащий анализируемые данные; Рисунок 2 Диалоговое окно «Мастер функций» 5) Заполните аргументы функции: Известные значения у – диапазон, содержащий данные результативного признака; Известные значения х – диапазон, содержащий данные факторного признака; Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0; Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения. Щёлкните по кнопке ОК; Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН 6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш + + . Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Остаточная сумма квадратов Рисунок 4 Результат вычисления функции ЛИНЕЙН Получили уровнение регрессии: Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб. 3. Коэффициент детерминации означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель. По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: . Связь оценивается как тесная. 4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат. Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле: Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у. Рисунок 5 Расчёт средних значений функции и аргумент Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%. С помощью инструмента анализа данных Регрессия можно получить: Порядок действий следующий: 1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки. 2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти. 3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК. • Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск. • Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его. 4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК. 5) Заполните диалоговое окно ввода данных и параметров вывода: Входной интервал Y – диапазон, содержащий данные результативного признака; Входной интервал X – диапазон, содержащий данные факторного признака; Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет; Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении; Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона; 6) Новый рабочий лист – можно задать произвольное имя нового листа. Затем нажмите кнопку ОК. Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия Результаты регрессионного анализа для данных задачи представлены на рисунке 7. Рисунок 7 Результат применения инструмента регрессия 5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8. Рисунок 8 Результат применения инструмента регрессия «Вывод остатка» Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле: Рисунок 9 Расчёт средней ошибки аппроксимации Средняя ошибка аппроксимации рассчитывается по формуле: Качество построенной модели оценивается как хорошее, так как не превышает 8 – 10%. 6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: Поскольку при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана). 8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей. Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля: . для числа степеней свободы На рисунке 7 имеются фактические значения t-статистики: t-критерий для коэффициента корреляции можно рассчитать двумя способами: I способ: где – случайная ошибка коэффициента корреляции. Данные для расчёта возьмём из таблицы на Рисунке 7. II способ: Фактические значения t-статистики превосходят табличные значения: Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы. Доверительный интервал для параметра a определяется как Для параметра a 95%-ные границы как показано на рисунке 7 составили: Доверительный интервал для коэффициента регрессии определяется как Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили: Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля. 7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит: Тогда прогнозное значение прожиточного минимума составит: Ошибку прогноза рассчитаем по формуле: где Дисперсию посчитаем также с помощью ППП Excel. Для этого: 1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию. 2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК. 3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК. Рисунок 10 Расчёт дисперсии Получили значение дисперсии Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7. Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением: Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным. Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил. 🔍 ВидеоУравнение линейной регрессии. Интерпретация стандартной табличкиСкачать  Эконометрика. Оценка значимости параметров уравнения регрессии. Критерий Стьюдента.Скачать  Линейная регрессияСкачать  Линейная регрессия. Что спросят на собеседовании? ч.1Скачать  Эконометрика Линейная регрессия и корреляцияСкачать  Математика #1 | Корреляция и регрессияСкачать  Как применять линейную регрессию?Скачать  Эконометрика. Оценка значимости уравнения регрессии. Критерий ФишераСкачать  Парная регрессия: линейная зависимостьСкачать  Лекция 8. Линейная регрессияСкачать  РегрессияСкачать  РЕАЛИЗАЦИЯ ЛИНЕЙНОЙ РЕГРЕССИИ | Линейная регрессия | LinearRegression | МАШИННОЕ ОБУЧЕНИЕСкачать  Множественная регрессия в ExcelСкачать  Лекция 2.1: Линейная регрессия.Скачать  Корреляционно-регрессионный анализ многомерных данных в ExcelСкачать 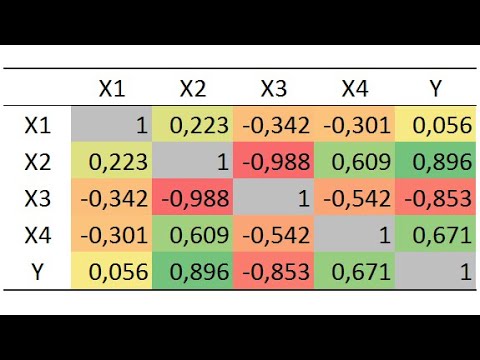 Решение задачи регрессии | Глубокое обучение на PythonСкачать  Что такое линейная регрессия? Душкин объяснитСкачать  Множественная регрессияСкачать  |